《28天玩转TensorFlow2》第9天:TensorFlow2构建数据管道—图片格式
扫描关注微信公众号pythonfan,获取更多

- 涉及到的知识点
- 卷积神经网络可视化
- 中间层输出可视化
- 卷积核可视化
- 类激活图
- 训练好的模型读取
- 卷积神经网络可视化
扫码关注微信号,回复关键词:CV,获取文章所有代码。
实例:TensorFlow花卉
本数据集一共有3670张图片,图片大小不一,共5类:daisy(雏菊), dandelion(蒲公英), roses(玫瑰), sunflowers(向日葵), tulips(郁金香)。每一类为一个文件夹。
1,数据获取
daisy :633张

dandelion :898张

roses :641张

sunflowers:699张

tulips :799张

2、图像数据转换
所有图片的路径ALL_FIG_PATH,对应的标签ALL_LABEL,标签和真实类别对应的字典class_dict。
# 将数据变为同样大小的,并且归一化
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [192, 192]) # 统一大小
image /= 255.0 # 归一化
return image
# 根据路径读取图片数据
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
3、构建数据通道
首先分割数据集,将数据集合按照比例分为训练、验证以及测试数据集。将图片路径和图片的标签合并在一起,形成数据集形式。将训练数据进行随机转换,并将数据存储在缓存文件中,提升模型训练的效率。
BATCH_SIZE = 64 # 批次训练的样本数
train_ds = TRAIN_DATA.cache(filename='./cache.tf-data') # 定义缓存文件,提升运行效率
train_ds = train_ds.apply(tf.data.experimental.shuffle_and_repeat(buffer_size=fig_count)) # 随机打乱的缓冲定义为全部图片的个数,有助于打乱数据
train_ds = train_ds.batch(BATCH_SIZE).prefetch(1) # 训练数据
val_ds = VAL_DATA.batch(BATCH_SIZE) # 验证数据
4、构建CNN模型
-
4.1 模型建立
利用Sequential按层顺序创建CNN模型
### 建立模型
def build_cnn(name='CNN_V'):
# 输入层
in_put = tf.keras.Input(shape=(192, 192, 3), name='INPUT')
# 卷积层
x = tf.keras.layers.Conv2D(filters=32, kernel_size=[3,3], activation='relu', name='CONV_1')(in_put)
# 卷积层
x = tf.keras.layers.Conv2D(filters=64, kernel_size=[3,3], activation='relu', name='CONV_2')(x)
# 最大池化层
x = tf.keras.layers.MaxPooling2D(pool_size=[2,2], name='MAXPOOL_1')(x)
# 卷积层
x = tf.keras.layers.Conv2D(filters=64, kernel_size=[3,3], activation='relu', padding='same', name='CONV_3')(x)
# 卷积层
x = tf.keras.layers.Conv2D(filters=64, kernel_size=[3,3], activation='relu', padding='same', name='CONV_4')(x)
# 最大池化层
x = tf.keras.layers.MaxPooling2D(pool_size=[2,2], name='MAXPOOL_2')(x)
# 卷积层
x = tf.keras.layers.Conv2D(filters=64, kernel_size=[3,3], activation='relu', padding='same', name='CONV_5')(x)
# 卷积层
x = tf.keras.layers.Conv2D(filters=64, kernel_size=[3,3], activation='relu', padding='same', name='CONV_6')(x)
# 卷积层
x = tf.keras.layers.Conv2D(filters=5, kernel_size=[1,1], activation='relu', padding='same', name='CONV_7')(x)
# 全局平均池化层,和平铺层相比,有助于减少参数
x = tf.keras.layers.GlobalAveragePooling2D(name='GAP_1')(x)
# 输出层
out_put = tf.keras.layers.Dense(5, activation='softmax', name='OUTPUT')(x)
# 建立模型
model = tf.keras.Model(inputs=in_put, outputs=out_put, name=name)
# 模型编译
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
# 建立模型
CNN_Model = build_cnn()
CNN_Model.summary()
Model: "CNN_V"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
INPUT (InputLayer) [(None, 192, 192, 3)] 0
_________________________________________________________________
CONV_1 (Conv2D) (None, 190, 190, 32) 896
_________________________________________________________________
CONV_2 (Conv2D) (None, 188, 188, 64) 18496
_________________________________________________________________
MAXPOOL_1 (MaxPooling2D) (None, 94, 94, 64) 0
_________________________________________________________________
CONV_3 (Conv2D) (None, 94, 94, 64) 36928
_________________________________________________________________
CONV_4 (Conv2D) (None, 94, 94, 64) 36928
_________________________________________________________________
MAXPOOL_2 (MaxPooling2D) (None, 47, 47, 64) 0
_________________________________________________________________
CONV_5 (Conv2D) (None, 47, 47, 64) 36928
_________________________________________________________________
CONV_6 (Conv2D) (None, 47, 47, 64) 36928
_________________________________________________________________
CONV_7 (Conv2D) (None, 47, 47, 5) 325
_________________________________________________________________
GAP_1 (GlobalAveragePooling2 (None, 5) 0
_________________________________________________________________
OUTPUT (Dense) (None, 5) 30
=================================================================
Total params: 167,459
Trainable params: 167,459
Non-trainable params: 0
_________________________________________________________________
-
4.2 模型训练
建立回调,保存最佳模型。
# 保存模型的文件夹
checkpoint_path_base = "./cnn_v-{val_accuracy:.5f}.ckpt"
checkpoint_dir_base = os.path.dirname(checkpoint_path_base)
# 创建一个回调,保证验证数据集损失最小
model_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path_base, save_weights_only=True,
monitor='val_accuracy', mode='max', verbose=2, save_best_only=True)
# 模型训练
model_history = CNN_Model.fit(train_ds, epochs=400, verbose=2, validation_data=val_ds, steps_per_epoch=10, callbacks=[model_callback])
5、CNN可视化
加载最佳模型
# 加载已经训练好的参数
model_best= build_cnn()
best_para_weight = tf.train.latest_checkpoint(checkpoint_dir_base)
model_best.load_weights(best_para_weight)
-
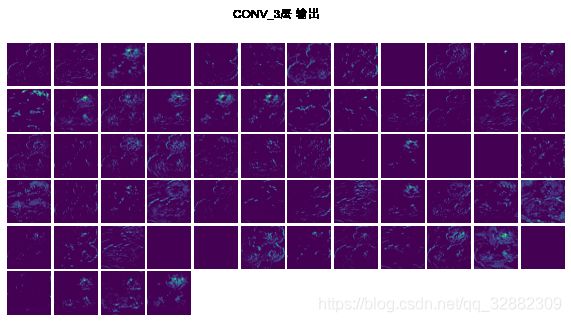
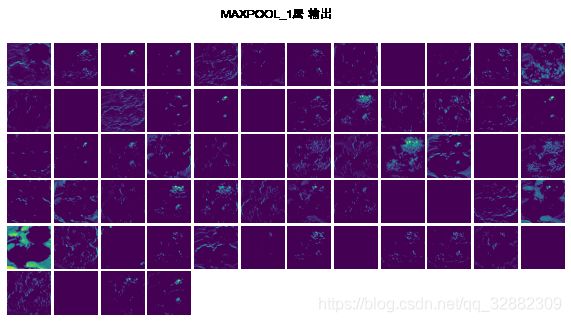
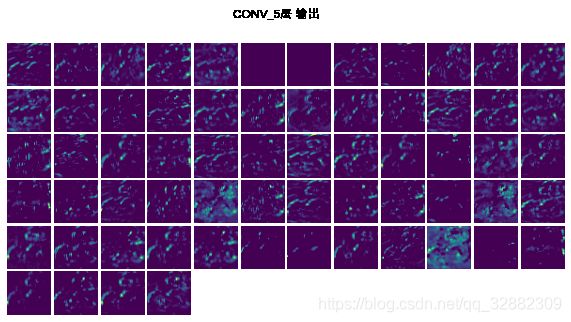
5.1 可视化模型每层的输出
在测试数据中随机选择第一个图片,查看模型中的每一层针对此图片的输出。




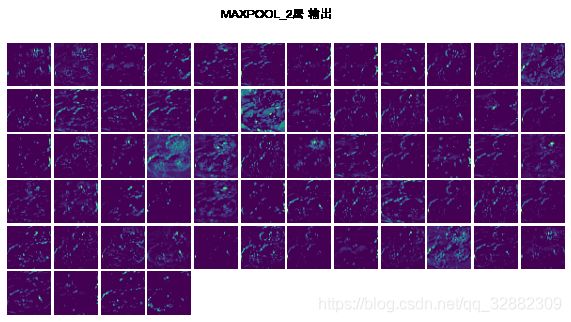
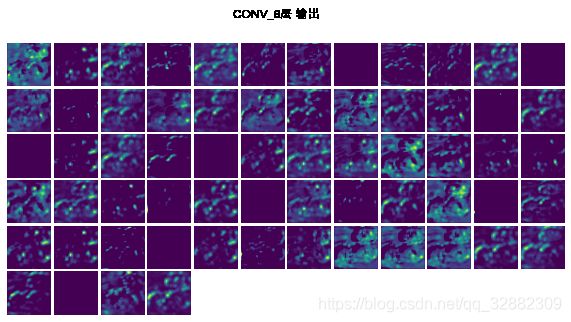

-
5.2 可视化每个卷积层学到的特征
可视化卷积层中的每个卷积核学到的特征,并不是待模型训练完毕后,将该卷积核展示出来,因为卷积核的高度和宽度一般都很小,直接展示出来作用不大,并不能清晰的看出学到的特征。一般有2种方式,一是利用反卷积,实现比较困难;二是下面利用梯度上升的思想来做,通过合成一个图片,使得该卷积核获得最大的激活值,经过一定次数的优化,最终这个图片就可认为是该卷积核学到的特征,步骤如下:
- 给定训练好的模型一个随机噪声的初始图,将这张图作为模型的输入 x x x,计算其在模型中第 i i i层 j j j个卷积核的激活值 A i j ( x ) A_{ij}(x) Aij(x),也就是输出值;
- 计算梯度 δ A i j ( x ) δ x \frac{\delta A_{ij}(x)}{\delta x} δxδAij(x)做一个反向传播,也就是用该图的卷积核梯度来更新噪声图: x + = η δ A i j ( x ) δ x x += \eta \frac{\delta A_{ij}(x)}{\delta x} x+=ηδxδAij(x)其中 η \eta η为学习率;
以此通过改变每个像素的颜色值以增加对该卷积核的激活值。








-
5.3 类激活图可视化
- (1)类激活图(CAM, class activation map)
类激活热力图是针对训练好的模型,输入属于某类的一个图片,输出的是这张图片中各个位置对于这个类的贡献程度的热力图。
实现CAM对模型结构是有要求的,也就是模型的倒数第二层必须是GAP层(GlobalAveragePooling,全局均值池化),并且该层的输出必须等于类别数,因为池化层的输出是根据前面的卷积层的卷积核的个数来的,所以这就要求前面的卷积核的个数为类别数。
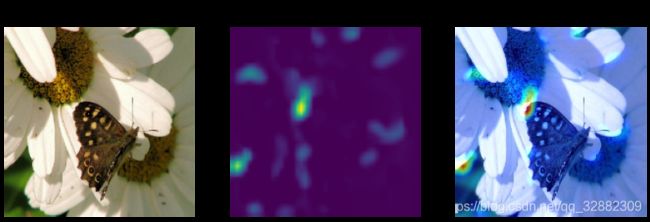
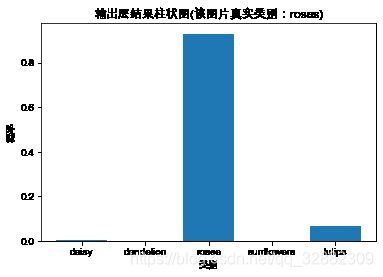
下面以本文中的例子说一下如何实现CAM,首先看下面的图片:
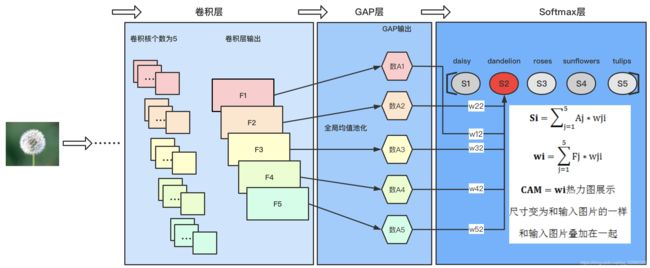
上面图示模型中最后一个卷积层中浓缩了很多的特征信息,GAP层就可看作分类器,最后的结果就是分类器结合不同权重的线性叠加,所以CAM就是最后一个卷积层的输出和权重的线性叠加,转变成热力图,放大到和输入图片相同的尺寸,并和原始图片叠加在一起。下面给出本文中CAM的结果。





- (2)加权梯度类激活图(Grad-CAM)
如果训练好的模型的结构不符合要求,则可以利用Grad-CAM的方法去实现,避免了修改模型结构,再次进行训练的麻烦。 Grad-CAM的原理就是给出一张图片,得到模型针对该图片的预测概率的最大值,并计算该值针对卷积层输出的梯度,并计算梯度的均值,将梯度均值与对应的每个卷积核的输出相乘,求和然后计算均值,得到类激活图。