numpy.loadtxt()方法读取csv文件为numpy数组
csv文件数据如下:
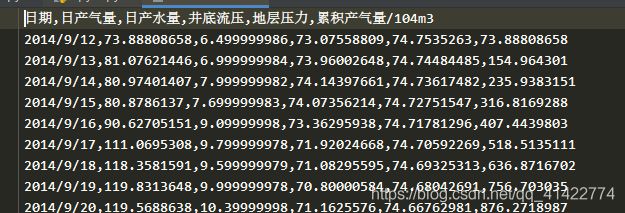
因为csv文件里面的日期是字符串,后面的为数值,数据类型不同不能一次性读取到一个numpy数组里面,否则会报类型错误,
所以分为两次读取,t1读取数据(即第1、2、3、4、5列),t2读取字符串格式的日期(第0列)
在读取字符串时,最后的.astype(str)作用是改变np.array中所有数据元素的数据类型为字符串类型,因为存储的时候是bytes形式存储的,如果不进行转换,读取出来的即为b’2014/9/12’此种类型的,转换之后即为’2014/9/12’字符串形式。
关于python 中的 type(), dtype(), astype()的区别见此
import numpy as np
# numpy读取csv文件
filepath = 'E:\\waterwell\\导入数据\\水气两相法导入数据\\生产数据1.csv'
#csv文件数据之间是以','分割,unpack是可选参数,默认为False,表示不转置所读取的数据矩阵
#skiprows=1 表示跳过第一行,,usecols=(1,2,3,4,5)表示读取列数,不读取第0列
t1 = np.loadtxt(filepath,dtype=np.int,delimiter=',',skiprows=1,usecols=(1,2,3,4,5),encoding='utf-8')
# 读取字符串,最后的.astype(str)作用是改变np.array中所有数据元素的数据类型
t2 = np.loadtxt(filepath,dtype=bytes,delimiter=',',skiprows=1,usecols=(0),encoding='utf-8').astype(str)
print(t1)
print(len(t1))
print(t2)
print(len(t2))
结果:
[[ 73 6 73 74 73]
[ 81 6 73 74 154]
[ 80 7 74 74 235]
...
[ 34 105 53 57 123323]
[ 33 104 53 57 123357]
[ 33 104 53 57 123391]]
1754
['2014/9/12' '2014/9/13' '2014/9/14' ... '2019/6/30' '2019/7/1' '2019/7/2']
1754