Alluxio环境搭建
Alluxio环境搭建
1.简介
Alluxio(之前名为Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。 应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有常规方案快几个数量级。
由于Alluxio的设计以内存为中心,并且是数据访问的中心,所以Alluxio在大数据生态圈里占有独特地位,它居于传统大数据存储 (如:Amazon S3,Apache HDFS和OpenStack Swift等)和大数据计算框架(如Spark,Hadoop Mapreduce)之间。对于用户应用和计算框架,无论其是否运行在相同的计算引擎之上,Alluxio都可以作为底层来支持数据的访问、快速存储,以 及多任务的数据共享和本地化。因此,Alluxio可以为那些大数据应用提供一个数量级的加速,同时它还提供了通用的数据访问接口。对于底层存储系 统,Alluxio连接了大数据应用和传统存储系统之间的间隔,并且重新定义了一组面向数据使用的工作负载程序。因Alluxio对应用屏蔽了底层存储系 统的整合细节,所以任何底层存储系统都可以支撑运行在Alluxio之上的应用和框架。此外Alluxio可以挂载多种底层存储系统,所以它可以作为统一 层为任意数量的不同数据源提供服务。

2.环境搭建
实验用集群硬件配置(虚拟机):
系统:Ubuntu 14.04 LTS 64位
CPU:Intel Core i5-6500 @ 3.2GHz
内存:4G
硬盘:30G
集群其他服务:Zookeeper,Hadoop,Spark
集群内机器数量:3
集群其他服务的搭建参考文档。
2.1 Alluxio参数配置与启动
在Alluxio官方下载安装包,解压安装包:
tar xvfz alluxio-1.0.1-bin.tar.gz解压后进入conf目录下,在workers文件中添加对应worker的hostname。重命名alluxio-env.sh.template为alluxio-en.sh,在这个文件里可以配置一些常用的环境变量,例如JAVA_HOME以及一些ALLUXIO的变量如下所示
export JAVA_HOME=/usr/jdk1.8.0_77
export ALLUXIO_MASTER_ADDRESS=alluxio0(此处为master机器的hostname)
export ALLUXIO_WORKER_MEMORY_SIZE=512M(配置每个Worker的内存盘大小)还可以通过新建在conf目录下新建一个alluxio-site.properties文件的方式去覆盖默认配置属性,更多配置属性参考配置项设置文档。
配置项配置完毕后运行命令格式化并启动alluxio:
./bin/alluxio format(格式化Alluxio)
./bin/alluxio-start.sh all SudoMount (这个脚本存在多个可选参数,all SudoMount指的是启动集群所有节点服务,并通过root权限格式化和挂载内存文件系统)
启动之后可以通过jps查看是否存在AlluxioMaster和AlluxioWorker进程,同时也可以通过WebUI监控:http://masterIP:19999/home
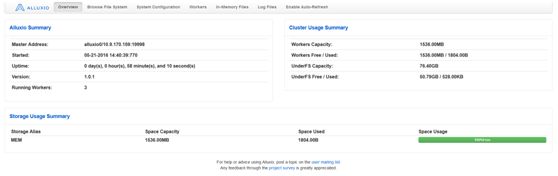
启动完成后可以通过运行测试用例检测功能完整性
./bin/alluxio runTests在Web界面中可以看到文件系统里增加了多个测试用例生存的文件

2.2将HDFS作为底层文件系统
将Alluxio与HDFS关联需要在alluxio-env.sh文件中增加一个环境变量
export ALLUXIO_UNDERFS_ADDRESS=hdfs://namenode:9000/alluxio这里填写的是HDFS中namenode的地址,如果只想将alluxio文件系统中的文件关联到HDFS中指定路径下,可以将路径加在地址后面,如上面的/alluxio。
运行完测试用例后就可以看到,那些PERSISTED的文件在HDFS中都能看到
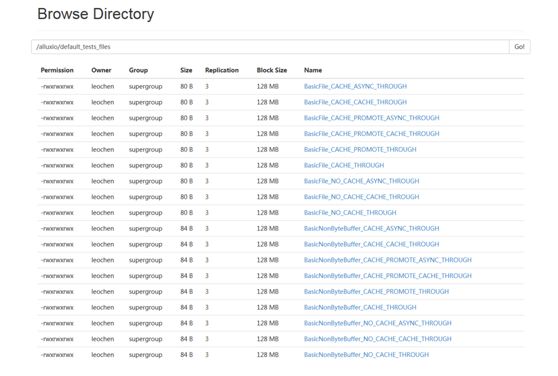
2.3在Alluxio上运行Spark任务
首先需要将一个spark对alluxio依赖包的路径添加到Spark的ClassPath
export SPARK_CLASSPATH=/home/leochen/alluxio-1.0.1/core/client/target/alluxio-core-client-spark-1.0.1-jar-with-dependencies.jar:$SPARK_CLASSPATH路径为下载依赖包存放的路径
通过alluxio文件系统的命令拷贝一个文件到内存文件系统中
alluxio fs copyFromLocal /media/sf_VirtualBoxShare/REAMDE.md /(将本地文件系统的文件拷贝到内存文件系统的根目录下)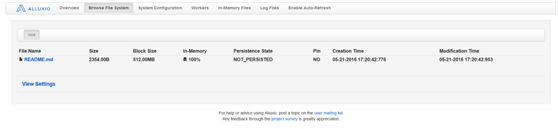
更多文件操作命令参考官方文档命令行接口。
启动一个sparkShell,对这个文件进行过滤操作
val num = sc.textFile(“alluxio://alluxio0:19998/README.md”).filter(line => line.contains(“alluxio”)).count得到结果

相比通过HDFS访问文件的方式,这里修改了文件系统的协议类型以及对应的IP和端口号。
如果所访问的文件不在内存文件系统中,但是在对应的底层文件系统中存有备份,那么Alluxio会透明地从底层文件系统取数据。
3.更多参考
Alluxio官方网站
Alluxio源代码
Alluxio与不同底层文件系统之间命名空间的介绍
文件系统API