记一次Phoenix写入优化
场景描述
现有大量CSV格式的数据记录存储在HDFS中,需要批量索引到Hbase以便于数据查询。限于Hbase的主键索引以及使用Hbase API的诸多不方便,最后采用了Phoenix+Hbase的技术架构。基于此方案数据的索引可通过Phoenix的SQL API、Spark RDD插件、以及Phoenix提供的批量加载工具” CsvBulkLoadTool”来实现数据写入,由于HDFS原始数据和Phoenix表并非一一对应关系且Phoenix表字段使用了组合值,这里不考虑使用CsvBulkLoadTool。
以下优化不在考虑数据类型.重点比较表[索引]是否分区、表分区数、RDD分区数
create table if not exists "mytable" ("id" VARCHAR NOT NULL PRIMARY KEY,...);
创建索引:
create index table_index on "mytable"("data"."ts","data"."imsi","data"."cid") SALT_BUCKETS=120;
数据写入方式:
Spark中使用Phoenix SQL API ,为避免一批提交的数据过大而提交失败,代码中控制了每批次提交的记录数.
由于之前使用批处理的时候没有指定每批次的数据写入大小,发现服务启动之后长时间挂起,Hbase写入阻塞Phoenix不能连接重启集群后恢复,怀疑是否由于大批量的提交引起,这里仅测试在表未分区的情况下每批次提交数据大小对写入的性能影响。下表记录了在特定场景下批次大小对Phoenix写入的影响
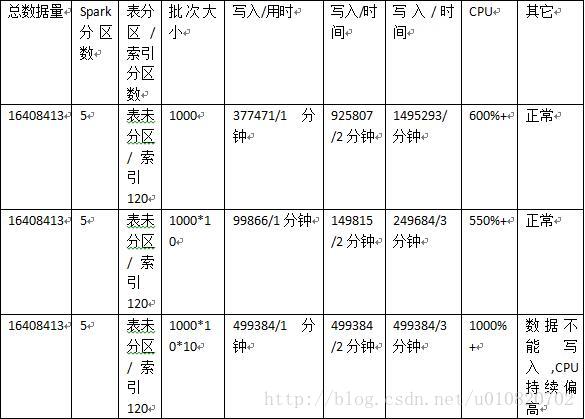
总结:
这里不与非批处理进行比较,理论上大量数据的批量写入优于逐条写入。
PhoenixSQL批量写入中每次提交的数据量对写入性能有很大影响,批次大小若不控制容易引起Hbase集群&Phoenix环境异常,可通过测试寻找最佳批次大小。
猜测:
Phoenix表未分区的情况下所有数据先被写入一个节点随着数据量的增加RegionServer进行Region拆分,此过程伴随大量的IO操作且对写入有极大影响,使用Phoenix对表进行预分区是否可避免。之前在网络上见有文章表明Phoenix SQL批量写入每批次总数最好不要超过30万,当前最优写入为5000*5节点=25万/批次,认为可靠。
创建表:
create table if not exists "mytable" ("id" VARCHAR NOT NULL PRIMARY KEY,...)SALT_BUCKETS=120;
创建索引:
create index table_index on "mytable"("data"."ts","data"."imsi","data"."cid") SALT_BUCKETS=120;
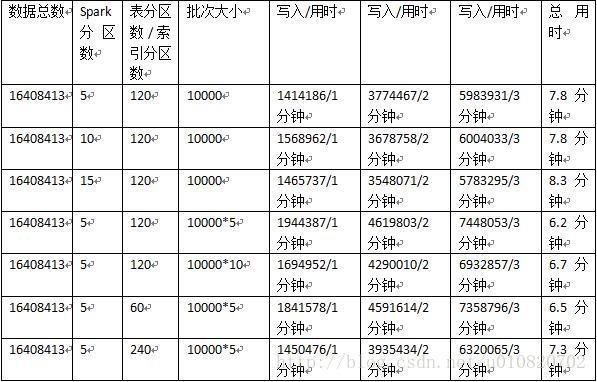
总结:
对表和索引进行分区对写入性能有极大的影响[索引也是表],Spark RDD的分区数对写入性能影响很小,表分区数和批次大小对写入性能影响很大,并非是线性关系,可通过测试寻找一个最佳的表分区数和批次大小。
猜测:
表分区数似乎在所有RegionServer的CPU核心数之和左右拥有更强的写入性能。通过Spark RDD写入是否拥有更强的写入能力。

结论:
目前没有觉得Spark RDD写入有什么明显的优势,这里也没有进行进一步的优化.
总结
使用Phoenix+Hbase进行大量数据写入的场景下[这里定义了二级索引]可使用SQL+批处理的方式进行写入,需要适当控制每批次提交的数据量避免Phoenix过载拒绝写入。同时可预先对表进行分区以加快写入速率,分区数在Hbase节点的 总的CPU 核心数作为宜,Spark所有节点的批次总和控制在30万左右比较靠谱。
现有大量CSV格式的数据记录存储在HDFS中,需要批量索引到Hbase以便于数据查询。限于Hbase的主键索引以及使用Hbase API的诸多不方便,最后采用了Phoenix+Hbase的技术架构。基于此方案数据的索引可通过Phoenix的SQL API、Spark RDD插件、以及Phoenix提供的批量加载工具” CsvBulkLoadTool”来实现数据写入,由于HDFS原始数据和Phoenix表并非一一对应关系且Phoenix表字段使用了组合值,这里不考虑使用CsvBulkLoadTool。
以下优化不在考虑数据类型.重点比较表[索引]是否分区、表分区数、RDD分区数
基础环境

- 第一版SQL写入
create table if not exists "mytable" ("id" VARCHAR NOT NULL PRIMARY KEY,...);
创建索引:
create index table_index on "mytable"("data"."ts","data"."imsi","data"."cid") SALT_BUCKETS=120;
数据写入方式:
Spark中使用Phoenix SQL API ,为避免一批提交的数据过大而提交失败,代码中控制了每批次提交的记录数.
由于之前使用批处理的时候没有指定每批次的数据写入大小,发现服务启动之后长时间挂起,Hbase写入阻塞Phoenix不能连接重启集群后恢复,怀疑是否由于大批量的提交引起,这里仅测试在表未分区的情况下每批次提交数据大小对写入的性能影响。下表记录了在特定场景下批次大小对Phoenix写入的影响
总结:
这里不与非批处理进行比较,理论上大量数据的批量写入优于逐条写入。
PhoenixSQL批量写入中每次提交的数据量对写入性能有很大影响,批次大小若不控制容易引起Hbase集群&Phoenix环境异常,可通过测试寻找最佳批次大小。
猜测:
Phoenix表未分区的情况下所有数据先被写入一个节点随着数据量的增加RegionServer进行Region拆分,此过程伴随大量的IO操作且对写入有极大影响,使用Phoenix对表进行预分区是否可避免。之前在网络上见有文章表明Phoenix SQL批量写入每批次总数最好不要超过30万,当前最优写入为5000*5节点=25万/批次,认为可靠。
- 第二版SQL写入
创建表:
create table if not exists "mytable" ("id" VARCHAR NOT NULL PRIMARY KEY,...)SALT_BUCKETS=120;
创建索引:
create index table_index on "mytable"("data"."ts","data"."imsi","data"."cid") SALT_BUCKETS=120;
总结:
对表和索引进行分区对写入性能有极大的影响[索引也是表],Spark RDD的分区数对写入性能影响很小,表分区数和批次大小对写入性能影响很大,并非是线性关系,可通过测试寻找一个最佳的表分区数和批次大小。
猜测:
表分区数似乎在所有RegionServer的CPU核心数之和左右拥有更强的写入性能。通过Spark RDD写入是否拥有更强的写入能力。
- 第三版RDD写入
基于第二版的结论第三版中设定Spark分区数为5,表及索引分区数为120测试Spark RDD提供的Phoenix写入API测试
结论:
目前没有觉得Spark RDD写入有什么明显的优势,这里也没有进行进一步的优化.
总结
使用Phoenix+Hbase进行大量数据写入的场景下[这里定义了二级索引]可使用SQL+批处理的方式进行写入,需要适当控制每批次提交的数据量避免Phoenix过载拒绝写入。同时可预先对表进行分区以加快写入速率,分区数在Hbase节点的 总的CPU 核心数作为宜,Spark所有节点的批次总和控制在30万左右比较靠谱。