OO第一单元总结
以下内容为个人对OO第一单元多项式求导的总结博客。主要有以下五个方面。
一、程序分析
1. 第一次作业
第一次作业内容比较简单,表达式中只有带符号整数和幂函数,求导时的规则也较简单。
UML类图如下:
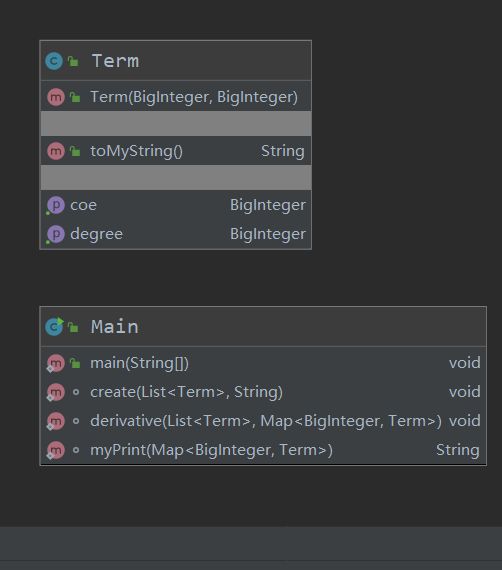
class信息如下:

method信息如下:
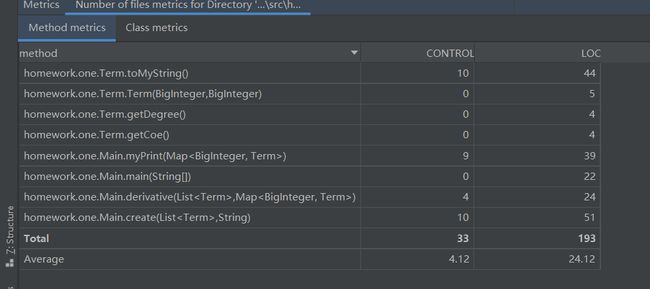
第一次作业因为内容比较简单,表达式可分为多个项进行存储,而每个项也只要存储系数与幂函数的指数信息即可。项内的方法并不多,只有简单的get函数(没有set,求导与化简都在外部进行)和转化为字符串的函数。
主要的功能,接受输入并存储表达式、求导并合并同类项、最后输出都集中在main函数中。
2. 第二次作业
第二次作业相比第一次增加了三角函数sin与cos,并要求wrong format的判断。但大体与第一次作业相同。
UML类图如下:
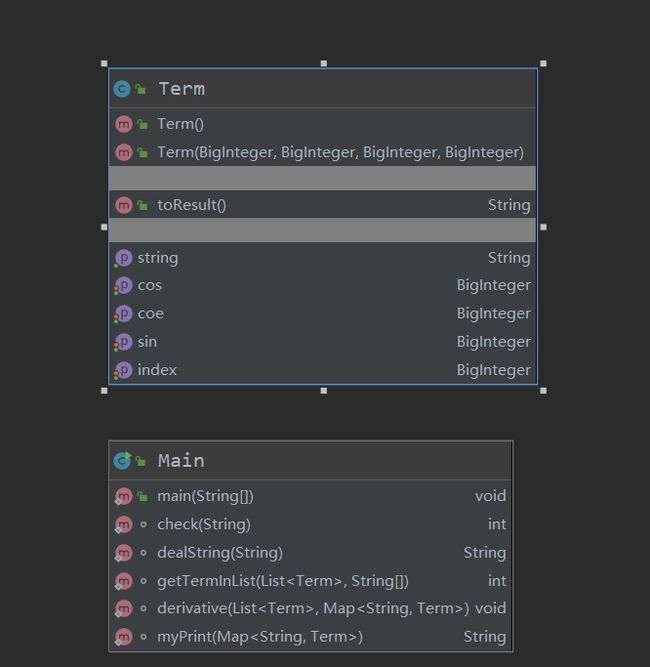
class信息如下:
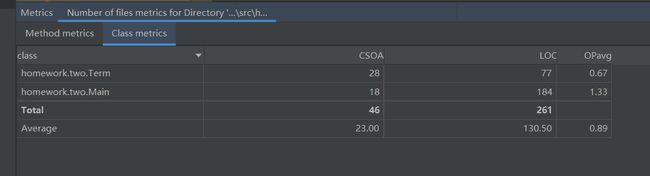
method信息如下:
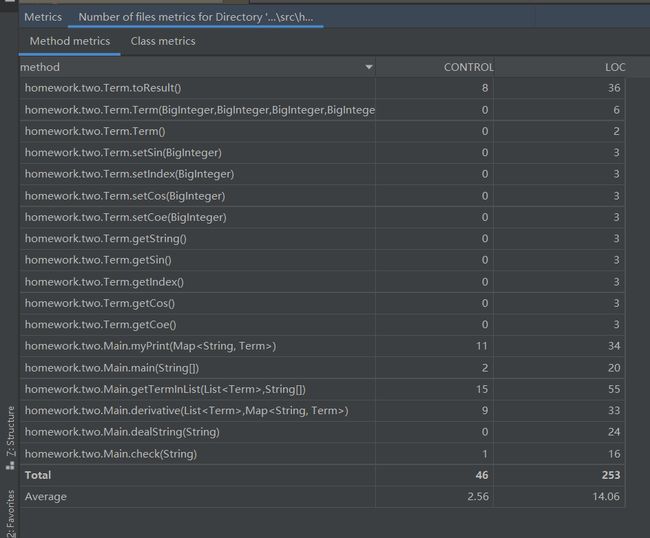
第二次作业与第一次结构大致相同,同样是从表达式中提取项并进行信息存储,但除了系数与幂函数指数外还需要新增加正弦函数的指数与余弦函数的指数两个信息,其他构造基本一致。
对于main函数,提取输入、求导合并、最终输出的功能不变,但需要增加关于表达式形式的判断,即wrong format的判断。
对于形式判断的方法,个人选择使用正则表达式直接给出最后表达式的正确形式。正则表达式构建代码如下:
String number = "([+-]?\\d+)";
String pow = "(x(\\*\\*[+-]?\\d+)?)";
String tri = "((sin|cos)\\(x\\)(\\*\\*[+-]?\\d+)?)";
String factor = number + "|" + pow + "|" + tri; //因子
String term = "([+-]?)(" + factor + ")((\\*)(" + factor + "))*"; //项
String formula = "([+-]?)(" + term + ")(([+-])(" + term + "))*"; //表达式
3. 第三次作业
第三次作业相比于第二次作业难度大幅提升,增加了嵌套表达式的内容,个人还因为其他事情而减少了第三次作业的学习时间,因此第三次作业个人的代码写的一塌糊涂,在ddl前的最后两小时才通过了中测。
UML类图如下:
class信息如下:

method信息如下:
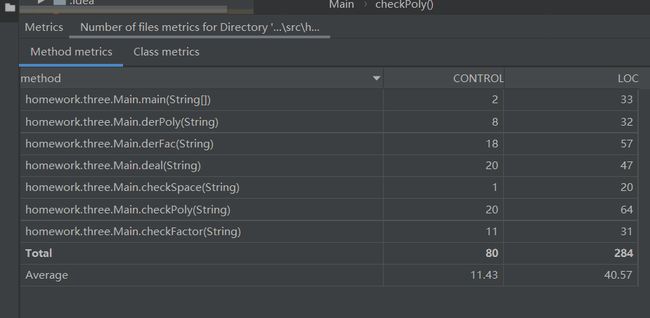
如上图所示,由于个人能力所限,第三次作业的结构完全是C语言的过程式编程的结构。
为了应对表达式的嵌套问题,个人使用递归函数来简化问题,查询到表达式后进行递归处理,之后对表达式内部的表达式进行下一层的递归。
对于形式判断的问题,个人将其分为了两步。首先是对空格的错误形式进行逐一排除,之后删除全部空格;第二对删除空格后的表达式进行形式检查,替换表达式中内嵌的表达式与三角函数内嵌的因子,之后对整体使用正则表达式来进行检查。对于内嵌的表达式和因子,则继续使用递归进行检查直至只有简单表达式或是因子。
4. 三次作业缺点总结
个人认为前两次作业中还有一点面向对象的影子,但第三次完全走回了C语言的老路。第三次可以说完全是C语言的代码,没有任何对象的思维。总体而言,自己面向对象的能力还是需要加强。
在三份代码中可以看出,个人还是不适应面向对象的编程方式。在主类里还是有着大量的静态函数,这些静态函数都可以由一个类或是一个接口来完成。
同时对于表达式中的各种因子,个人还是应该要去多建几个类来对他们进行存储,并对其设置各中相应的方法。总之还是应该要去适当运用类的继承与接口的实现等等思维。
针对第三次代码,个人为了应对表达式嵌套的问题而使用了递归函数,因此简化了问题。但同时代码的复杂度也大大地提高了,并且因为递归的使用,代码的结构也变得杂乱,最终使得代码让人难以理解。
二、 程序Bug的分析
1. 第一次作业Bug分析
因为第一次作业内容较为简单,所以公测与互测环节都未出现Bug,因此跳过此次作业。
2. 第二次作业Bug分析
第二次作业的难度在第一次作业的基础上有所增加,但坡度较缓。个人的代码在互测中没有出现bug,但在强测中错误了一个测试点。
错误的原因在于个人设置了,如果项的系数为0则输出空串的情况。因此如果测试数据最终可以合并同类项使得结果为0的话,则代码会输出空串。
对于bug的修复,只要加入特判即可。如果最终结果为空串,则输出字符串"0"。相关代码如下:
if (result.toString().equals("")) { result.append("0"); } //如果result中没有任何项则输出0
这个bug的出现原因在于自己忽略了在输出函数中的特殊情况。
3. 第三次作业Bug分析
第三次作业的难度是三次作业中最难的,因此在代码中个人放弃了优化,为保障正确性而牺牲了性能分。也正因为这样,个人在强测中并没有出现bug。但在互测中还是被hack了两次。
错误的原因在于个人进行表达式形式判断时的不正确替换。在对表达式进行形式判断时个人会将sin(因子)转换为sin@因子@,之后提取因子进行递归的形式判断,遍历完整个表达式后再次替换为sin@(仅以sin为例,cos同理)。因此,在某些特殊情况下会出现形如sin@+cos@这样的表达式,之后进行替换,成为sin,之后形式判断错误,出现bug。
对于此bug的修复,只需要在代码中加入一个标志位,来记录此时需不需要替换即可。
这个bug的出现原因还是在于递归时出现了错误判断。
三、 发现他人bug的策略
个人对于没有使用自动评测的方法,因此只能手动构成测试样例。
1. 使用特殊形式的数据
在代码编写时,大家都会注意到一些特殊形式的数据,例如--x、---1*x、0*0等。但因为这类数据过于简单,大家写代码都有考虑,因此有效性不高。
2. 使用边界数据
根据指导书的定义去寻找边界数据,以此去测试他人代码。当然此种方法的有效性也不高,难以成功hack他人代码。
3. 根据他人代码构造测试数据
第三种方法是个人进行互测hack他人代码时使用的主要方法,大多数的bug都是通过此方法被找出。对我而言,这种方法的有效性最高,只要能找到他人代码的漏洞,基本就可以hack成功。但是这种方法也有极其明显的缺点,它十分耗费人的时间与精力,因此其性价比很低。
四、应用对象创建模式
关于这里的对象创建模式,以下说明仅限于工厂模式。
对于本单元的作业,个人认为可以采用简单工厂模式。
首先我们需要创建多个不同的类,幂函数类、正弦函数类、余弦函数类等等作为因子,并且每个类都需要实现一个接口(可以是求导接口,也可以是其他)以便于归一化管理。之后建立一个工厂类,根据给定的字符串生产不同的因子类。至于给定的字符串则需要对表达式进行两次分割后才可以得到(一次由表达式分为项,二次由项分为因子)。之后可以对生产出来的因子进行归一化管理。
五、 对比与心得体会
在看完他人优秀代码后,个人有了相当多的体会。
1. 面向对象的思维
与他人的代码对比,最突出的差距还是在于面向对象的思维。很多类的封装、接口的实现思维都值得我去学习。以及很多函数做的事情都可以交给相应的类或接口去做,这样也会有助于之后作业的迭代。
2. 工厂模式的使用
使用工厂模式在作业要求增加后也可以迅速适应,且更符合面向对象的思维方式,有助于简化代码的结构。
3. 代码结果的简化
总体上代码可以总结为几部分,读取表达式、判断表达式是否合法、储存表达式信息、求导、化简、输出。以上部分很多可以结合到一起,简化代码的结构,让主类中的程序更加清晰整洁且封装性更好。
4. 类的继承与接口的实现
个人在类的继承与接口的实现这个方面的能力还是太弱,需要继续增强。毕竟只有在这基础上才能去使用多态、归一化等等java的特性,才能更好地去学习面向对象这门课程。