一、Datax简介
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。

二、框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三、简单的调研
前段时间,简单的调研了一下datax,主要通过抽取速度、抽取数据的稳定性,抽取日志,增量抽取等方面进行了datax和kettle之间的对比
3.1抽取速度
先后采用datax和kettle抽取382万左右的数据:从oracle抽取到mysql
datax需要2分30秒:

kettle需要21分钟:

而将数据量增加至千万级别时:大概1864万左右的数据
datax需要21分钟左右:

kettle需要2小时58分:
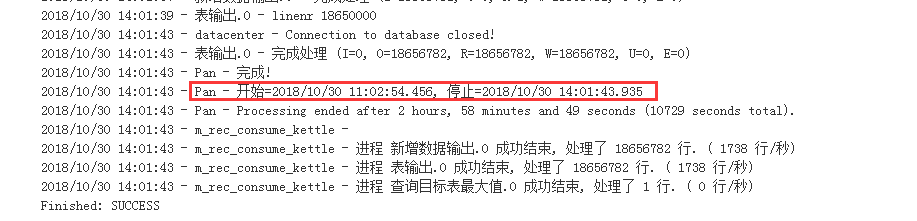
以上datax是在channel为1的情况下测试的,即单线程抽取
3.2抽取日志
日志方面,datax和kettle的日志都是比较好的。不过,当datax的job失败时,他的日志更加人性化一点:
提供了任务失败的可能原因:

3.3抽取稳定性
当我们使用kettle从mysql抽取数据导入到hdfs上时,存在丢数据的情况。
对于datax,目前我们处于调研阶段,只是运行了个demo,并不能确定是否存在丢数据的情况。目前未发现网上有说丢数据的情况
3.4增量抽取
增量抽取一般会先从我们自己的数据库中查询出最大的增量标识(一般为id或时间),再从数据源中抽取大于最大标识的数据。
在增量方面,kettle还是支持的很好,但datax缺乏对增量更新的内置支持
kettle可以使用工作流的形式,先查询出目标表的最大值,把这个值作为一个变量传入下一个阶段中。

datax:因为datax的job是一个json文件来描述的,增量抽取的where条件需要动态传入,动态修改json文件不是很方便。所以网上的解决办法是在json中的where条件使用占位符,并通过shell脚本来动态传入最大值。
具体可以参考以下两篇博文:
https://blog.csdn.net/quadimodo/article/details/82186788
http://ju.outofmemory.cn/entry/360202
3.5动态感知namenode的切换
使用kettle往hdfs上导数据时,namenode的地址是在kettle.properties配置文件中配的,所以当我们的集群重启时,namenode有可能发生切换,导致kettle导数据任务失败
而datax往hdfs上导数据时,可以配置namenode 的HA:

3.6其他
当然kettle还有一个优势是有一个可视化界面,我们在服务器中通过vnc可以界面化操作
四、增量更新的思路
网上提供了一种思路是通过shell脚本来实现的,当然,更重要的是我们已有的增量更新中,不仅有用时间来做增量的,还有通过自增id来抽取的,不同的任务不一样
所以最好是让用户直接配置他们想要的增量字段,通过用户的配置字段确认需要更新的数据范围,实现kettle的那一套。
我在网上找了一个开源项目,虽然跟我们的需求有点不一样,但改改就可以了
https://github.com/Jawf/DataX-Migration
这个项目我大致看了一下,它是将一个库中的表抽取到另一个库中,里面有些是需要改动的地方:
1.在配置文件中,他会取imformation.scheme库中,通过Table表和Column表去查询源数据库的对应表的元数据信息,但里面的查询sql语句是在配置文件中配的,所以在程序中需要动态维护需要导的表名,即执行sql时,需要replace对应的字符串
2.目标数据库中的表是不会自动创建的,需要手动提前创建好