目标:爬取https://www.imdb.com/chart/top网页上面的电影top20

直接上main.py代码:
1 #!/usr/bin/python35 2 # -*- coding:utf-8 -*- 3 # author: "Keekuun" 4 5 import requests 6 from lxml import html 7 from download import download_url #download.py 8 9 # 传入网址 10 url = 'https://www.imdb.com/chart/top' 11 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'} 12 13 # 下载网页 14 req = download_url(url, headers) 15 tree = html.fromstring(req) 16 xpath_x = '//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr' 17 18 def info(x): 19 # 下载排行 #strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)。后面加上“text()”获取内容 20 rank = tree.xpath(xpath_x + '[{}]/td[2]/text()'.format(x))[0].strip().strip('.') 21 # print(rank) 22 23 # 下载电影名 24 name = tree.xpath(xpath_x + '[{}]/td[2]/a/text()'.format(x))[0] 25 # print(name) 26 27 # 下载电影评分 28 score = tree.xpath(xpath_x + '[{}]/ td[3]/strong/text()'.format(x))[0] 29 30 # print(score) 31 32 # 下载电影海报链接。后面加上“@src”获取内容 33 img_url = tree.xpath(xpath_x + '[{}]/td[1]/a/img/@src'.format(x))[0] 34 # print(img_url) 35 36 info = { 37 'movie_rank':rank, 38 'movie_name':name, 39 'movie_score':score, 40 'movie_img_url':img_url 41 } 42 return info 43 44 with open('top_movie.txt','a',encoding='utf-8') as f: 45 for x in range(1,21): 46 movie = info(str(x)) 47 print(movie) 48 movie_str ='Rank:{}\t Name:{}\t Score:{}\t ImgUrl:{}'.format( 49 movie['movie_rank'], 50 movie['movie_name'], 51 movie['movie_score'], 52 movie['movie_img_url'] 53 ) 54 f.write(movie_str + '\n')# 不可直接写入字典,必须为str
download.py代码部分:
#!/usr/bin/python35 # -*- coding:utf-8 -*- # author: "Keekuun" import requests def download_url(url,headers): req = requests.get(url,headers) return req.content def download_img(url,path): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'} img = download_url(url,headers) with open(path,'wb') as f: # “wb”方式打开文件 f.write(img)
img.py保存图片:
1 #!/usr/bin/python35 2 # -*- coding:utf-8 -*- 3 # author: "Keekuun" 4 from download import download_img 5 import os 6 7 path = 'Movie_img' 8 if not os.path.isdir(path): 9 os.mkdir(path) 10 11 # 打开main.py保存的top_movie.txt,从中获取图片现在地址 12 with open('top_movie.txt','r',encoding='utf-8') as f: 13 for x in f.readlines(): 14 rank = x.split(' ')[0].strip('Rank:').strip('\t') 15 print(rank) 16 img = x.split(' ')[-1].strip('ImgUrl:').strip() 17 path = os.path.join('Movie_img/','{}.jpg'.format(rank)) 18 download_img(img, path)
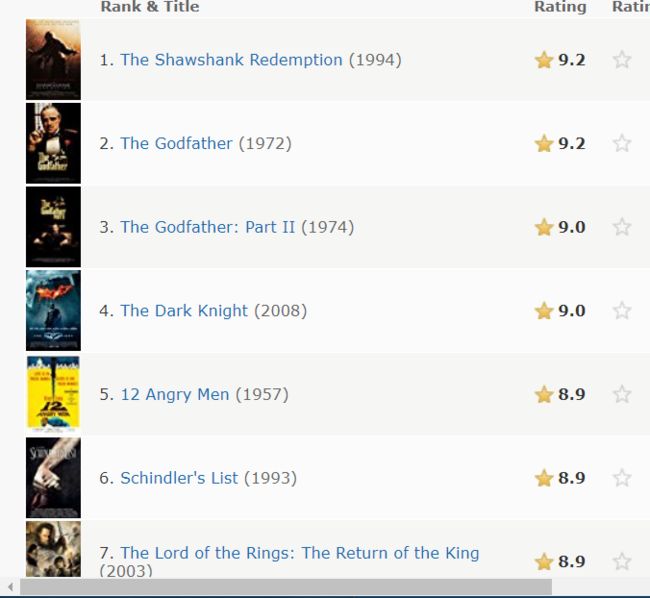
结果:
top_movie.txt:
Rank:1 Name:The Shawshank Redemption Score:9.2 ImgUrl:https://ia.media-imdb.com/images/M/MV5BMDFkYTc0MGEtZmNhMC00ZDIzLWFmNTEtODM1ZmRlYWMwMWFmXkEyXkFqcGdeQXVyMTMxODk2OTU@._V1_UY67_CR0,0,45,67_AL_.jpg
Rank:2 Name:The Godfather Score:9.2 ImgUrl:https://ia.media-imdb.com/images/M/MV5BM2MyNjYxNmUtYTAwNi00MTYxLWJmNWYtYzZlODY3ZTk3OTFlXkEyXkFqcGdeQXVyNzkwMjQ5NzM@._V1_UY67_CR1,0,45,67_AL_.jpg
Rank:3 Name:The Godfather: Part II Score:9.0 ImgUrl:https://ia.media-imdb.com/images/M/MV5BMWMwMGQzZTItY2JlNC00OWZiLWIyMDctNDk2ZDQ2YjRjMWQ0XkEyXkFqcGdeQXVyNzkwMjQ5NzM@._V1_UY67_CR1,0,45,67_AL_.jpg
Rank:4 Name:The Dark Knight Score:9.0 ImgUrl:https://ia.media-imdb.com/images/M/MV5BMTMxNTMwODM0NF5BMl5BanBnXkFtZTcwODAyMTk2Mw@@._V1_UY67_CR0,0,45,67_AL_.jpg
Rank:5 Name:12 Angry Men Score:8.9 ImgUrl:https://ia.media-imdb.com/images/M/MV5BMWU4N2FjNzYtNTVkNC00NzQ0LTg0MjAtYTJlMjFhNGUxZDFmXkEyXkFqcGdeQXVyNjc1NTYyMjg@._V1_UX45_CR0,0,45,67_AL_.jpg
Rank:6 Name:Schindler's List Score:8.9 ImgUrl:https://ia.media-imdb.com/images/M/MV5BNDE4OTMxMTctNmRhYy00NWE2LTg3YzItYTk3M2UwOTU5Njg4XkEyXkFqcGdeQXVyNjU0OTQ0OTY@._V1_UX45_CR0,0,45,67_AL_.jpg
Rank:7 Name:The Lord of the Rings: The Return of the King Score:8.9 ImgUrl:https://ia.media-imdb.com/images/M/MV5BNzA5ZDNlZWMtM2NhNS00NDJjLTk4NDItYTRmY2EwMWZlMTY3XkEyXkFqcGdeQXVyNzkwMjQ5NzM@._V1_UY67_CR0,0,45,67_AL_.jpg
........
Movie_img:电影海报
1.jpg
2.jpg
3.jpg
.....
结果如下:
