TensorFlow学习记录:GoogleNet模型
GoogleNet最核心的亮点就是它的Inception,最大的特点就是去除了最后的全连接层,用全局平均池化层(即使用与特征图尺寸相同的过滤器来做平均池化)来取代它。
这么做的原因是:在以往的AlexNet和VGGNet网络中,全连接层几乎占据90%的参数量,占用了过多的运算量内存使用率,而且还会引起过拟合。
GoogleNet的做法是去除全连接层,使得模型训练更快并且减轻了过拟合。之后GoogleNet的Inception还在继续发展,目前己经有v2、v3和v4版本,主要针对解决深层网络的以下3个问题产生的。
(1)参数太多,容易过拟合,训练数据集有限 。
(2)网络越大计算复杂度越大,难以应用。
(3)网络越深,梯度越往后传越容易消失(梯度弥散),难以优化模型 。
Inception的核心思想是通过增加网络深度和宽度的同时减少参数的方法来解决问题。例如,Inception v1有22层深,比AlexNet的8层或者VGGNet的19层更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却有着更高的准确率。
下面将沿着Inception的进化来一步步了解Inception。
1.1 Inceptinon原始Moudle
Inception的原始Module相对于MLP卷积层更加稀疏,它采用了MLP卷积层的思想,将中间的全连接层换成了多通道卷积层。Inception与MLP在卷积网络中的作用一样,把封装好的Inception Module作为一个卷积单元,堆叠起来形成了原始的GoogleNet网络。
Inception Module的结构是将1*1,3*3,5*5的卷积核对应的卷积操作和3*3的滤波器对应的池化操作堆叠在一起,一方面增加了网络的宽度,另一方面增加了网路对尺度的适应性,结构如下图所示:
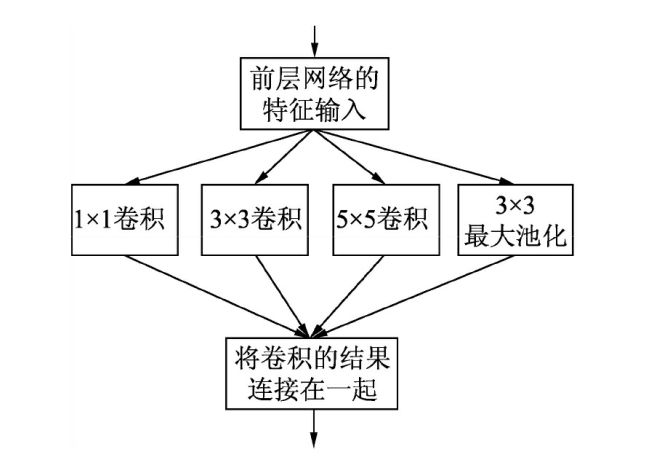
Inception Module中包含了3种不同尺寸的卷积和一个最大池化,增加了网络对不同尺度的适应性,这和Multi-Scale的思想类似。早期计算机视觉的研究中,受灵长类神经视觉系统的启发,Serre使用不同尺寸的Gabor滤波器处理不同尺寸的图片,Inception v1借鉴了这种思想。Inception V1的论文中指出,Inception Module可以让网络的深度和宽度高效率地扩充,提升了准确率且不致于过拟合。
形象的解释就是Inception Module本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成更大网络。
1.2 Inception V1 Module
Inception V1 Module在原有的Inception Module基础上做了一些改进,原因是由于Inception的原始Module是将所有的卷积核都在上一层的输出来做,那么5*5的卷积核所需的计算量就比较大,造成了特征图很厚大。
为了避免这一现象,Inception V1 Module在3*3前,5*5前,最大池化层后分别加上了1*1的卷积核,起到了降低特征图厚度的作用(其中1*1卷积主要用来降维),Inception V1 Module结构如下图所示
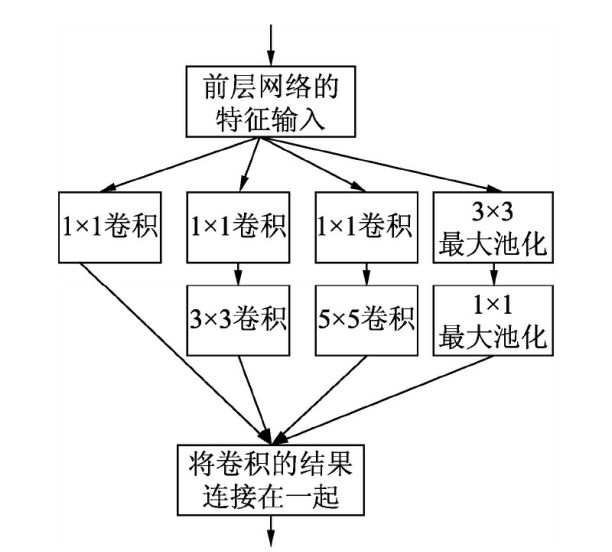
Inception V1Moudle中有以下4个分支:
(1)第1个分支对输入进行1*1卷积,这其实也是NIN中提出的一种重要结构。1*1卷积可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道进行升维和降维。
(2)第2个分支先使用了1*1卷积,然后连接3*3卷积,相当于进行了两次特征变换。
(3)第3个分支与第2个分支类似,先是1*1卷积,然后连接5*5卷积。
(4)第4个分支则是3*3最大池化后直接使用1*1卷积。
可以发现4个分支都用到了1*1卷积,有的分支只使用1*1卷积,有的分支在使用了其他尺寸的卷积的同时会再使用1*1卷积,这是因为1*1卷积的性价比很高,增加一层特征变换和非线性转化所需的计算量更小。
1*1的卷积作用:
- 可以进行跨通道的特征变换,把这些相关性很高的、在同一个空间位置但是不同通道的特征连接在一起,提高网络的表达能力;
- 同时可以对输出通道升维(拉伸)和降维(压缩),计算量小。
Inception V1 Module的4个分支在最后再通过一个聚合操作合并(使用tf.concat函数在输出通道数的维度上聚合)。
1.3 Inception V2 Module
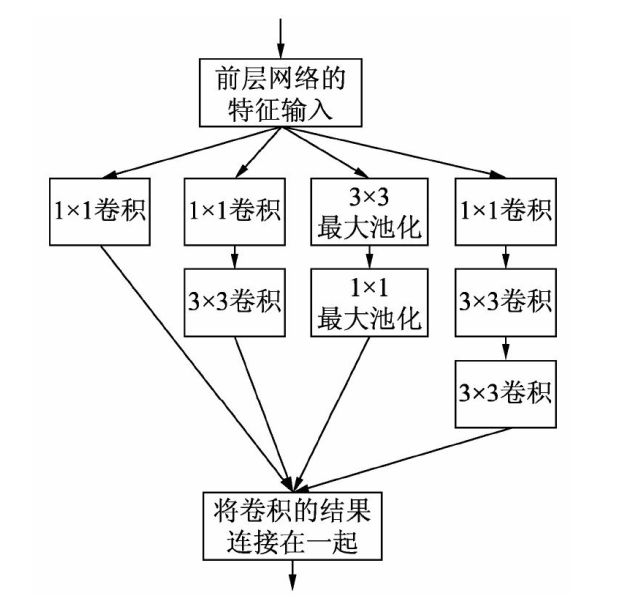
Inception v2模型在Inception v1模型基础上应用当时的主流技术,在卷积之后加入了BN层,使每一层的输出都归一化处理,减少了内变协变量的移动问题;同时还使用了梯度截断技术,增加了训练的稳定性。另外,Inception学习了VGG,用2个3*3的
conv替代Inception模块中的5*5,这既降低了参数量,也提升了计算速度。Inception V2 Module的结构如下图所示:
1.4 Inception V3 Module
Inception V3 Module没有再加入其它的技术,只是将原有的结构进行了调整,其最重要的一个改进是分解。
具体的计算方法是:将7*7分解成两个一维的卷积(1*7,7*1),3*3的操作也一样(1*3,3*1)。这种做法是基于线性代数的原理,即一个[n,n]的矩阵,可以分解成矩阵[n,1]*[1,n],得出的结构如下图所示:

在实际测试中,这种结构在前几层处理较大特征数据时的效果并不太好,但在处理中间状态生成的大小在12~20之间的特征数据时效果会非常明显,也可以大大提升运算速度。另外,Inception V3还做了其它变化,将网络的输入尺寸由224*224变为了299*299,并增加了卷积核为35*35/17*17/8*8的卷积模块。
2.1使用Slim工具包搭建Inception V3 的一个Module
Incpetion V3模型结构如下图所示:
Inception V3模型总共有46层,由11个Inception Module组成。仔细一数就会发现在Inception V3模型中共有96个卷积层,如果只是使用conv2d()函数创建卷积层,那么将产生冗长的代码。
下面以Inception V3 模型的最后一个Module 为例,通过Slim工具来完成对它的搭建。
Slim工具中的arg_scope()函数可以用于设置默认的参数值。slim.arg_scope()函数的第一个参数是需要提供默认值的函数,通常会被写成列表的形式,在这个列表中的函数将使用默认的参数值。
在slim工具中,同样也封装了构建卷积层与池化层的一些函数。在下面的代码中,将会用到的是slim.conv2d(),slim.max_pool2d()和slim.avg_pool2d()函数,它们的使用方法和平常用的tf.nn.conv2d(),tf.nn.max_pool()和tf.nn.avg_pool()差不多一致。在执行卷积和池化操作时,一般都会设置stride=1和padding=“SAME”,而这些取值相同的参数可以放到arg_scope()函数中声明。
比如,在程序中对 srg_scope()函数声明了 stride=1 和padding=“SAME”, 那么在接下来调用slim.conv2d(last_net,320,[1,1])函数时会自动加上而不必再对 stride 参数和 padding 参数赋值。如果在调用 slim.conv2d(last_net,320,[l,l]) 函数时指定了stride参数和padding参数,那么通过srg_scope()函数设置的 默认值就不会再使用。
这 种 使 用Slim工具的方式可以进一步减小冗余的代码 。下面的程代码展示了Inception V3 的最后一个Module的实现:
import tensorflow as tf
import tensorflow.contrib.slim as slim
# 使用Slim的arg_scope()函数设置一些会用到的卷积或池化函数的默认参数值,包括stride=1,padding="SAME"
with slim.arg_scope([slim.conv2d,slim.max_pool2d,slim.avg_pool2d],stride=1,padding="SAME"):
# 在这里为Inception Module创建一个统一的变量命名空间,模块中含有多条路径
# 每一条路径都会接收模块之前网络节点的输出,这里用last_net统一代表这个输出
with tf.variable_scope("Module"):
# 使用变量空间的名称标识模块的路径,这类似与"BRANCH_N"的形式
# 例如BRANCH_!表示这个模块里的第二条路径
with tf.variable_scope("BRANCH_0"):
branch_0 = slim.conv2d(last_net,320,[1,1],scope="Conv2d_0a_1x1")
with tf.variable_scope("BRANCH_1"):
branch_1 = slim.conv2d(last_net,384,[1,1],scope="Conv2d_1a_1x1")
# tf.concat()函数实现了拼接的功能,函数原型为tf.concat(values,axis,name)
# 第一个参数用于指定拼接的维度,对于InceptionModule来说,这个值一般为3,表示在第3个维度上进行拼接(串联);第二个参数是用于拼接的两个结果
branch_1 = tf.concat(3,[slim.conv2d(branch_1,384,[1,3],scope="Conv2d_1b_1x3"),slim.conv2d(branch_1,384,[3,1],scope="Conv2d_1c_3x1")])
with tf.variable_scope("BRANCH_2"):
branch_2 = slim.conv2d(last_net,448,[1,1],scope="Conv2d_2a_1x1")
branch_2 = slim.conv2d(branch_2,384,[3,3],scope="Conv2d_2b_3x3")
branch_2 = tf.concat(3,[slim.conv2d(branch_2,384,[1,3],scope="Conv2d_2c_1x3"),slim.conv2d(branch_2,384,[3,1],scope="Conv2d_2d_3x1")])
with tf.variable_scope("BRANCH_3"):
branch_3 = slim.avg_pool2d(last_net,[3,3],scope="AvgPool_3a_3x3")
branch_2 = slim.conv2d(branch_3,192,[1,1],scope="Conv2d_3a_1x1")
# 最后用concat()函数将InceptionModule每一条路径的结果进行拼接,得到最终结果
Module_output = tf.concat(3,[branch_0,branch_1,branch_2,branch_3])
参考书籍:
《深度学习之TensorFlow入门,原理与进阶实践》 李金洪 编著
《TensorFlow深度学习算法原理与编程实战》 蒋子阳 著