Python Pandas因其基本功能而广受欢迎。熊猫库具有许多必不可少的基本功能和功能,使您的日常工作变得更加轻松。强烈建议初学者掌握Pandas的基本功能。
熊猫的基本功能
在启动Pandas基本功能之前,您必须学习导入库配套课程请点击这里:
>>>将numpy导入为np
>>>将熊猫作为pd导入
在这里,我们将创建在Pandas中工作的4个主要数据结构。
指数
>>> dataflair_index = pd。date_range ('1/1/2000' ,period = 8 )
系列
>>> dataflair_s1 = pd。系列(np.random。randn (5 ),指数= [ 'A' ,'B' ,'C' ,'d' ,'E' ] )
数据框
>>> dataflair_df1 = pd。数据帧(np.random。randn (8 ,3 ),指数= dataflair_index,列= [ 'A' ,'B' ,'C' ] )
面板
>>> dataflair_wp1 = pd。面板(np.random。randn (2 ,5 ,4 ),项= [ '的Item1' ,'项目2' ] ,major_axis = PD。DATE_RANGE ('1/1/2000' ,时段= 5 ),minor_axis = [ ' A' ,'B' ,'C' ,'D' ] )
输出-
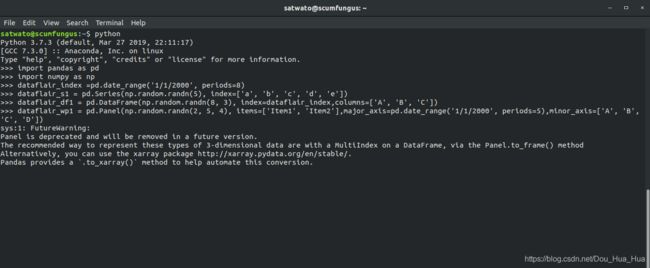
在熊猫中导入图书馆
在深入研究Pandas基本功能之前,让我们发现Pandas中的文件层次结构
现在我们可以从熊猫的基本功能开始。
1.head()函数
2.tail()函数
3.属性
4.灵活的二进制运算
要查看一个长序列的开始或结尾,我们可以使用head()或tail()函数。
1. head()函数
让我们创建一个具有1000个随机值的序列
>>> dataflair = pd。系列(np.random。randn (1000 ))
使用head()函数-
>>> dataflair。头()
输出-
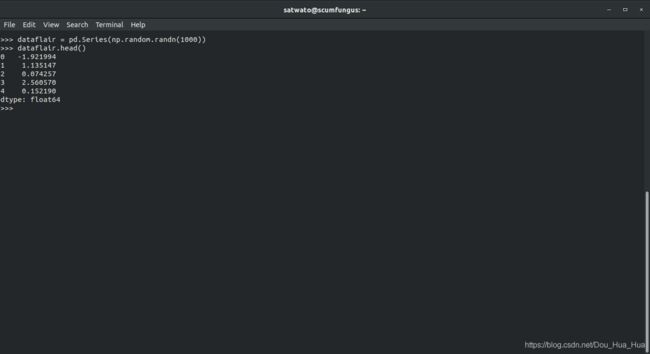
熊猫头功能
2. tail()函数
现在,我们使用tail函数并将元素数设置为3:
>>> dataflair。尾巴(3 )
输出-
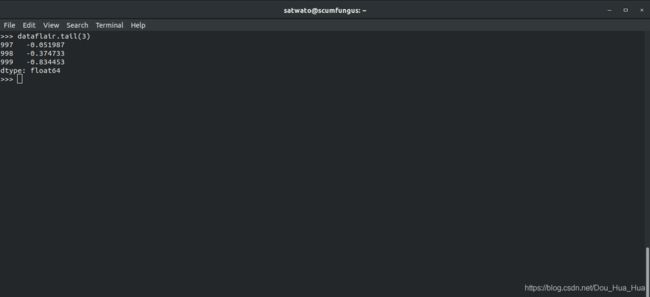
是什么使Python Pandas与其他库不同?
3.属性配套课程请点击这里:
属性在熊猫的基本功能中起着重要作用,它可以帮助数据科学家快速分析,清理和准备数据。Pandas对象具有许多属性,使您可以访问元数据。
形状:给出轴尺寸
轴标签:
系列:索引(仅一个轴)
DataFrame:索引(行)和列
面板:长轴,短轴和项目
您可以安全地分配这些属性。
>>> dataflair_df1 [ :2 ]
输出-
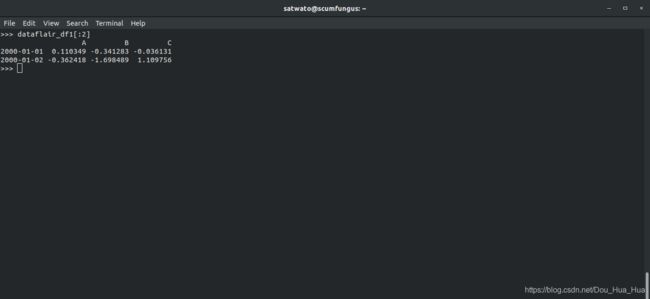
这将打印DataFrame的最后两个值
>>> dataflair_df1.columns = [ x。下()用于dataflair_df1.columns X ]
>>> dataflair_df1
输出-
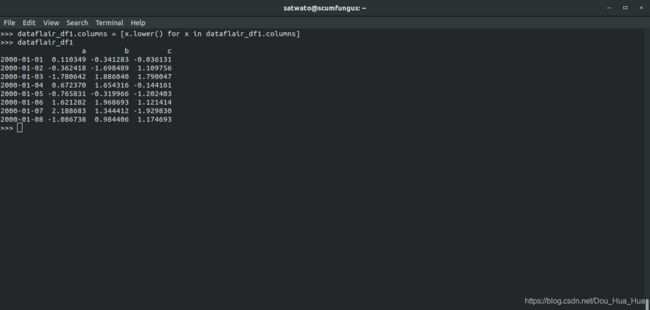
使用此函数,我们将大写的列名更改为小写。
如果必须获取Pandas数据结构内部的实际数据,则只需使用values属性。
>>> dataflair_s1.values
输出-
输入-
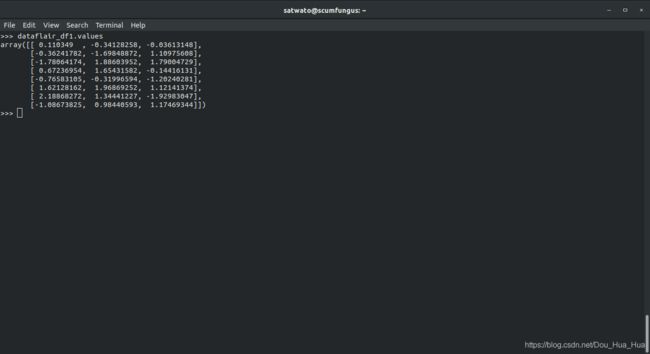
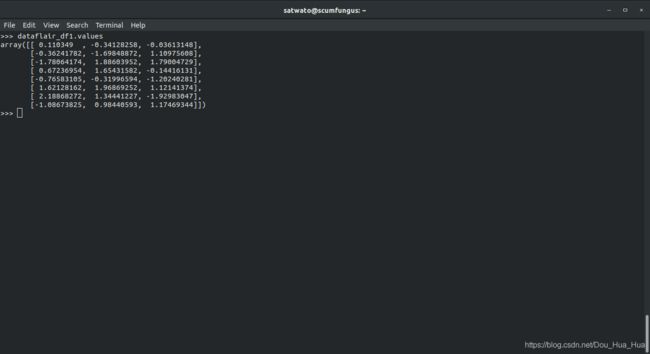
>>> dataflair_df1.values
输出-
熊猫的上到下列名
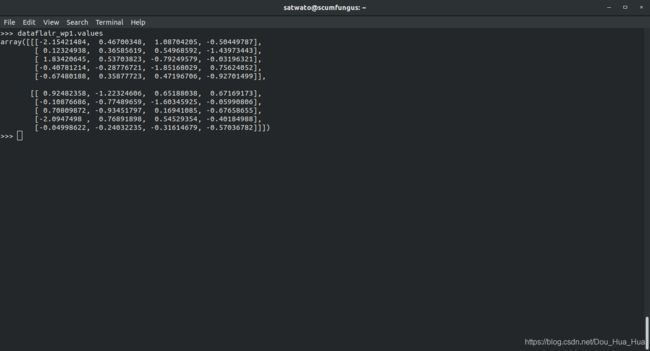
>>> dataflair_wp1.values
输出-
4.灵活的二进制运算配套课程请点击这里:
在熊猫数据结构之间的二进制操作中,有两个重要的关注点:
低维对象与高维对象之间的广播行为
计算时丢失数据
我们将学习如何独立处理这两个问题。它们可以同时处理。
4.1广播行为
对于广播行为,“ 系列”输入为主要输入。您可以使用axis()关键字来匹配索引或列。
>>> dataflair_df = pd。数据帧({ '一' :PD 系列(。np.random randn (3 ),指数= [ 'A' ,'B' ,'C' ] ),'2' :PD 系列(。np.random randn (4 ),index = [ 'a' ,'b' ,'c' ,'d' ] ),'3' :pd 系列(np.random。3 ),index = [ 'b' ,'c' ,'d' ] )} )
>>> dataflair_df
输出-
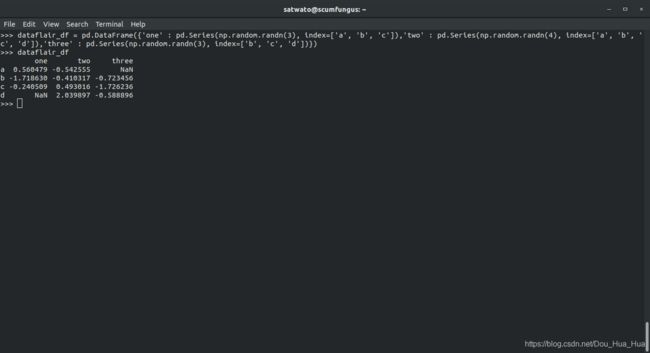
在熊猫中使用Axis关键字
输入-
>>>行= dataflair_df.iloc [ 1 ]
>>>列= dataflair_df [ 'two' ]
>>> dataflair_df。sub (row,axis = 'columns' )
输出-
熊猫在数据科学中很流行,但在其他领域也有不同的应用。
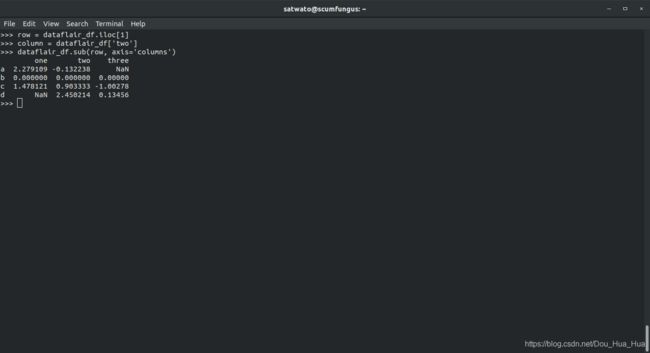
>>> dataflair_df。子(列,轴= '索引' )
输出-
熊猫的列明智索引
输入-
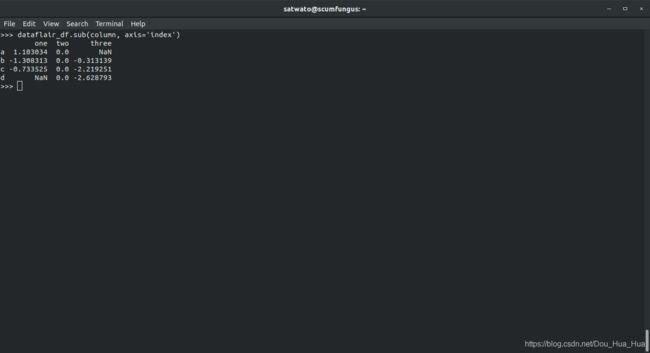
>>> dataflair_df。sub (列,轴= 0 )
输出-
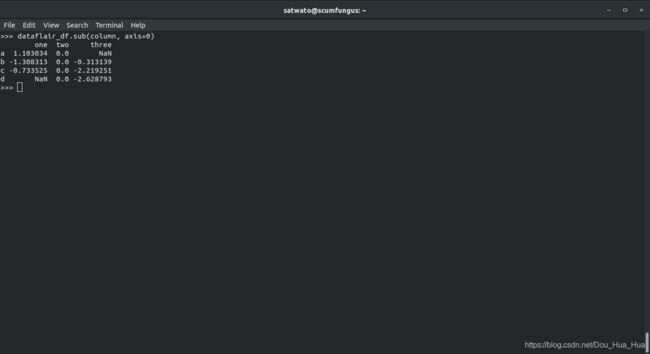
4.1.1多索引DataFrames级别
使用系列,可以对齐多索引DataFrame的级别。
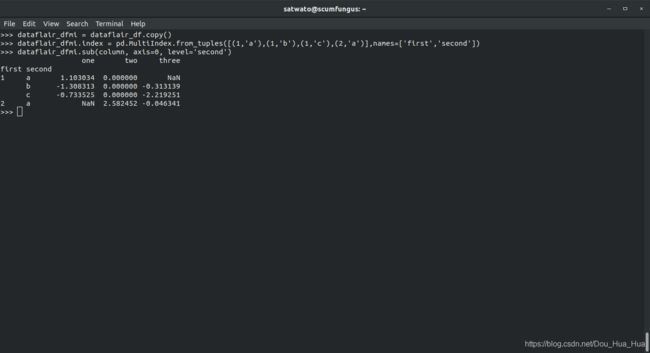
>>> dataflair_dfmi = dataflair_df。复制()
>>> dataflair_dfmi.index = pd.MultiIndex。from_tuples ([ (1 ,'a' ),(1 ,'b' ),(1 ,'c' ),(2 ,'a' )] ,名称= [ 'first' ,'second' ] ))
>>> dataflair_dfmi。子(列,轴= 0 ,级别= '秒' )
输出-
熊猫多索引数据框
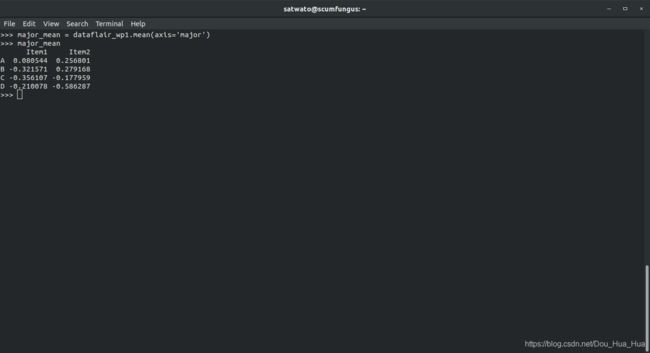
在面板中,匹配或广播行为有些困难。因此,将改为使用算术方法,从而为您提供了指定广播轴的选项。
>>> major_mean = dataflair_wp1。均值(axis = 'major' )
>>> major_mean
输出-
带有主轴的熊猫多索引DataFrame
>>> dataflair_wp1。子(major_mean,axis = 'major' )
输出-
Series和Index支持divmod()内置函数。它同时进行地板除法和模运算,并返回相同类型的二元组。它将其返回为左侧。
您知道Python Pandas提供的好处吗?
对于系列
>>> dataflair_s = pd。系列(NP。人气指数(10 ))
>>> dataflair_s
输出-

熊猫中divmod内置函数的示例
输入–
>>> div,rem = divmod (dataflair_s,3 )#除以3
>>> div
0 0
1 0
2 0
3 1
4 1
5 1
6 2
7 2
8 2
9 3
>>>雷姆
内置功能的熊猫Divmod的结果
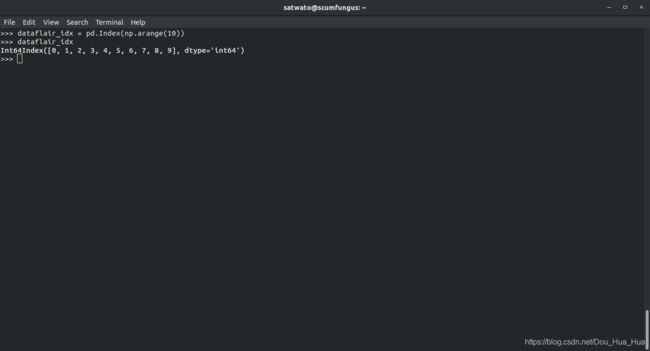
对于索引
>>> dataflair_idx = pd。指数(NP。人气指数(10 ))
>>> dataflair_idx
熊猫系列索引
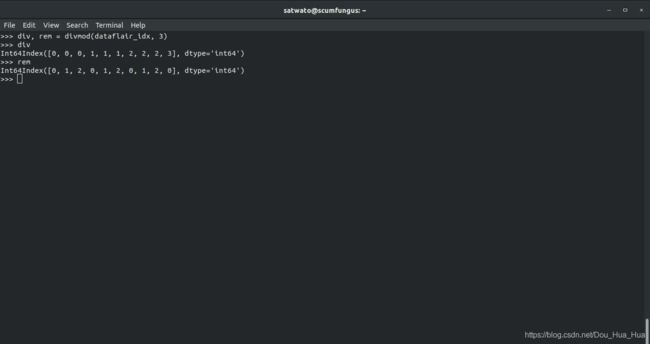
>>> div,rem = divmod (dataflair_idx,3 )
>>> div
Int64Index([0,0,0,1,1,1,2,2,2,3],dtype ='int64')
>>>雷姆
使用divmod()在熊猫里玩
我们也可以按元素进行divmod()。
div,rem = divmod(dataflair_s,[2,2,3,3,4,4,5,5,6,6])#第一个元素将被2除,第二个元素被3除,第三个元素被3依此类推
>>> DIV,REM = divmod (dataflair_s,[ 2 ,2 ,3 ,3 ,4 ,4 ,5 ,5 ,6 ,6 ] )
>>> div
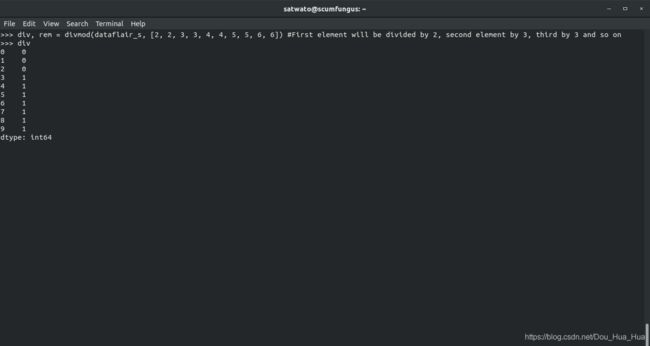
Divmod函数的示例
>>>雷姆
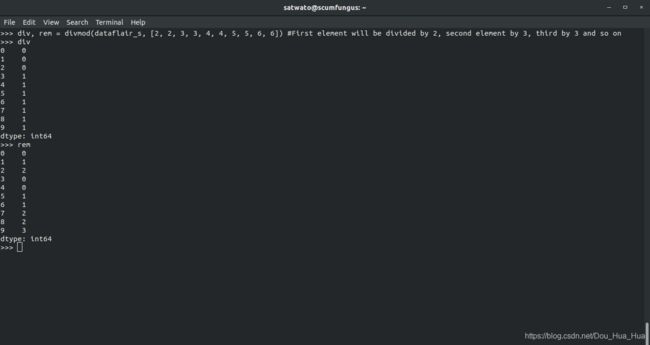
4.2熊猫缺失值
在DataFrame和Series中,算术函数为您提供了一个输入fill_value的选项,当位置中缺少某个值时,该方法基本上替代了一个值。当添加两个DataFrame对象时,可以将NaN视为0。但是,如果两个DataFrame都缺少该值,则结果将为NaN。您仍然可以稍后使用fillna函数将其替换为其他值。
>>> dataflair_df
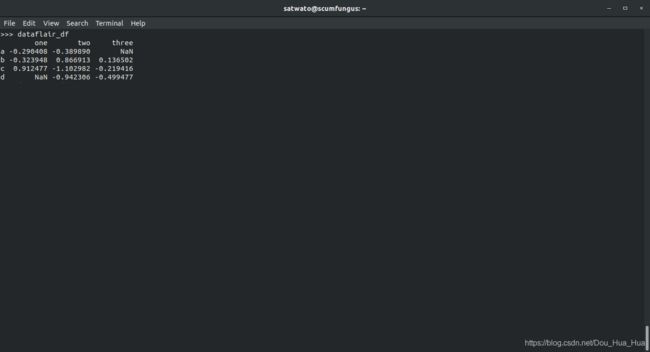
在熊猫中查找缺失值配套课程请点击这里:
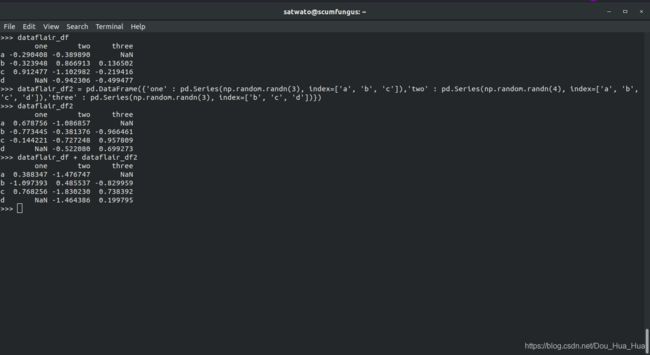
>>> dataflair_df2 = pd。数据帧({ '一' :PD 系列(。np.random randn (3 ),指数= [ 'A' ,'B' ,'C' ] ),'2' :PD 系列(。np.random randn (4 ),index = [ 'a' ,'b' ,'c' ,'d' ] ),'3' :pd 系列(np.random。3 ),index = [ 'b' ,'c' ,'d' ] )} )
>>> dataflair_df2
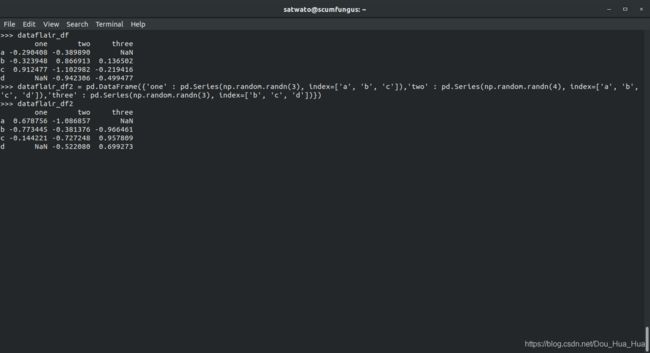
在熊猫中获取缺失值
>>> dataflair_df + dataflair_df2
熊猫值缺失的示例
输入项
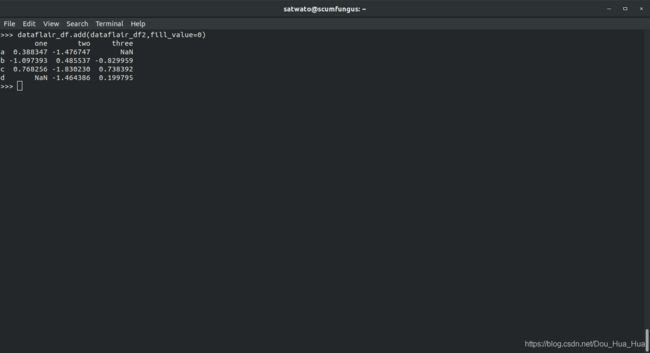
>>> dataflair_df。加(dataflair_df2,fill_value = 0 )#做与'+'运算符相同的操作
输入缺失值
摘要
总而言之,我们想说基本功能涵盖了许多Pandas,但是这些是主要功能以及一些灵活的比较和布尔归约。配套课程请点击这里:
更多文章和资料|点击下方文字直达 ↓↓↓
阿里云K8s实战手册
[阿里云CDN排坑指南]CDN
ECS运维指南
DevOps实践手册
Hadoop大数据实战手册
Knative云原生应用开发指南
OSS 运维实战手册