一文掌握GO语言实战技能(三)
Go 接口
Go 反射详解
Go 并发编程
Go Channel介绍
Go Worker池的实现
Go Select语义介绍和使用
Go 互斥锁介绍
Go 读写锁介绍
Go 读写锁和互斥锁性能比较
Go 原子操作
GO 接口
接口的介绍和定义
接口定义了一个对象的行为规范
a. 只定义规范,不实现
b. 具体的对象需要实现规范的细节
Go 中接口定义
a. type 接口名字 interface
b. 接口里面是一组方法签名的集合,后面的调用参数和返回值都要和接口中的方法一模一样
c. 接口是引用类型(指针);注意:函数传递接口类型参数时,一定不要加*,因为接口本身就是引用类型,如果加*就报错了
type Animal interface {
Talk()
Eat() int
Run()
}
接口的实现
a. 一个类只要实现了接口要求的所有函数,我们就说这个类实现了该接口
b. 接口类型的变量可以保存实现该接口的任何具体类型的实例。
package main
import (
"fmt"
)
type Animal interface { //定义了动物的规范(接口定义的一组方法)
Talk()
Eat()
Name() string
}
type Dog struct { //狗如果能够满足了动物的规范(接口方法),那其就是动物
}
func (d Dog) Talk() { //目前狗还不是动物,因为其只实现了Eat,还需要实现Eat和Name,其才算是动物
fmt.Println("汪汪汪")
}
func (d Dog) Eat() {
fmt.Println("我在吃骨头")
}
func (d Dog) Name() string {
fmt.Println("我的名字叫旺财")
return "旺财"
}
type Pig struct {
}
func (d Pig) Talk() {
fmt.Println("坑坑坑")
}
func (d Pig) Eat() {
fmt.Println("我在吃草")
}
func (d Pig) Name() string {
fmt.Println("我的名字叫猪八戒")
return "猪八戒"
}
func testInterface1() {
var d Dog
var a Animal
a = &d //dog满足了接口所有方法,所以我们可以直接将其复制给Animal,对应的理论就是接口类型的变量可以保存实现该接口的任何具体类型的实例。
// fmt.Printf("a:%v dog:%v\n", a, dog) //接口底层就是指针,指向的就是一个空对象,如果字节调用就会panic
a.Eat()
a.Talk()
a.Name()
var pig Pig
a = &pig
a.Eat()
a.Talk()
a.Name()
fmt.Printf("%T %v\n", a, a)
}
func main() {
testInterface1()
//testInterface2()
}
// 我在吃骨头
// 汪汪汪
// 我的名字叫旺财
// 我在吃草
// 坑坑坑
// 我的名字叫猪八戒
// *main.Pig &{}
空接口
a. 空接口没有定义任何方法
b. 任何类型都实现了空接口, 空接口可以存储 任何类型,就是一个容器
package main
import (
"fmt"
)
func describe(a interface{}) {
fmt.Printf("%T %v\n", a, a)
}
func testInterface1() {
var a interface{}
var b int = 100
a = b
fmt.Printf("%T %v\n", a, a)
var c string = "hello"
a = c
fmt.Printf("%T %v\n", a, a)
var d map[string]int = make(map[string]int, 100)
d["abc"] = 1000
d["eke"] = 30
a = d
fmt.Printf("%T %v\n", a, a)
}
type Student struct {
Name string
Sex int
}
func main() {
a := 65
describe(a)
str := "hello"
describe(str)
var stu Student = Student{
Name: "user01",
Sex: 1,
}
describe(stu)
// testInterface1
}
// int 65
// string hello
// main.Student {user01 1}
类型断言
a. 如何获取接口类型里面存储的具体的值呢?
使用a.(类型的值),ok用来判断是否正确,引入 ok判断机制! v, ok := i.(T)。如果没有ok,程序会挂掉。
package main
import (
"fmt"
)
func test(a interface{}) {
// s := a.(int)
s, ok := a.(int)
if ok {
fmt.Println(s)
return
}
str, ok := a.(string)
if ok {
fmt.Println(str)
return
}
f, ok := a.(float32)
if ok {
fmt.Println(f)
return
}
fmt.Println("can not define the type of a")
}
func testInterface1() {
var a int = 100
test(a)
var b string = "hello"
test(b)
}
type switch。转换为2次,解决办法是 v:=a.(type)
func testSwitch(a interface{}) {
switch a.(type) {
case string:
fmt.Printf("a is string, value:%v\n", a.(string))
case int:
fmt.Printf("a is int, value:%v\n", a.(int))
case int32:
fmt.Printf("a is int, value:%v\n", a.(int))
default:
fmt.Println("not support type\n")
}
}
func testSwitch2(a interface{}) {
switch v := a.(type) {
case string:
fmt.Printf("a is string, value:%v\n", v)
case int:
fmt.Printf("a is int, value:%v\n", v)
case int32:
fmt.Printf("a is int, value:%v\n", v)
default:
fmt.Println("not support type\n")
}
}
func testInterface2() {
var a int = 100
testSwitch(a)
var b string = "hello"
testSwitch(b)
}
func testInterface3() {
var a int = 100
testSwitch2(a)
var b string = "hello"
testSwitch2(b)
}
func main() {
testInterface1()
//testInterface2()
}
指针接收
package main
import "fmt"
type coder interface {
code()
debug()
}
type Gopher struct {
language string
}
//值接收
func (p Gopher) code() {
fmt.Printf("I am coding %s language\n", p.language)
}
//指针接收
func (p *Gopher) debug() {
fmt.Printf("I am debuging %s language\n", p.language)
}
func main() {
// var c coder = &Gopher{"Go"} //这种写法没有问题
var c coder = Gopher{"Go"} //这种写法会报错,因为Gopher没有全部实现coder接口。表面上看, *Gopher类型也没有实现code方法,但是因为Gopher类型实现了code方法,所以让*Gopher类型自动拥有了code方法
c.code()
// c.debug()
}
使用指针作的理由:
方法能够修改指向的值。
避免在每次调用方法时复制该值,在值的类型为大型结构体时,这样做会更加高效。
是使用值接收还是指针接收,不是由该方法是否修改了调用者(也就是接收者)来决定,而是应该基于该类型的本质。
如果类型具备“原始的本质”,也就是说它的成员都是由 Go 语言里内置的原始类型,如字符串,整型值等,那就定义值接收者类型的方法。像内置的引用类型,如 slice,map,interface,channel,这些类型比较特殊,声明他们的时候,实际上是创建了一个 header, 对于他们也是直接定义值接收者类型的方法。这样,调用函数时,是直接 copy 了这些类型的header,而header本身就是为复制设计的。
如果类型具备非原始的本质,不能被安全地复制,这种类型总是应该被共享,那就定义指针接收者的方法。比如 go 源码里的文件结构体(struct File)就不应该被复制,应该只有一份实体。
// 方式一: 值类型实现
// 值类型实现了Dog, (d Dog) Eat() 形式,那么我们既可以把Dog以值类型( var d Dog a = d a.Eat())给Animal,也可以以指针类型给 d,那么这时候在调用时候接口做了转化(*(&Dog).Eat(),&Dog为指针类型,加*转换为值类型)
package main
import (
"fmt"
)
type Animal interface {
Talk()
Eat()
Name() string
}
type Dog struct {
}
// 值类型实现
func (d Dog) Talk() {
fmt.Println("汪汪汪")
}
// 值类型实现
func (d Dog) Eat() {
fmt.Println("我在吃骨头")
}
// 值类型实现
func (d Dog) Name() string {
fmt.Println("我的名字叫旺财")
return "旺财"
}
func main() {
var a Animal
var d Dog
//如果一个变量存储在接口类型的变量中之后,那么不能获取这个变量的地址
a = d
a.Eat()
// 值类型实现了一个接口,指针类型可以存储进去
// 指针类型实现了一个接口,值类型存储存储不进去
fmt.Printf("%T %v\n", a, a)
var d1 *Dog = &Dog{}
a = d1
//*(&Dog).Eat() // 指针类型存入调用方法 会做这种转换
a.Eat()
fmt.Printf("*Dog %T %v\n", a, a)
}
// 方式一: 指针类型实现
// 如果指针类型实现了接口,a存的是值类型的Dog,那么调用a.Eat(),首先取&Dog.Eat(),但是一个变量存储在接口变量,那么就不能获取这个变量地址,所以就调取不到这个接口,所以,此时我们如果是指针类型实现了这个接口,我们只能存指针的Dog
// 值类型实现了一个接口,指针类型可以存储进去
// 指针类型实现了一个接口,值类型存储存储不进去
package main
import (
"fmt"
)
type Animal interface {
Talk()
Eat()
Name() string
}
type Dog struct {
}
func (d *Dog) Talk() {
fmt.Println("汪汪汪")
}
func (d *Dog) Eat() {
fmt.Println("我在吃骨头")
}
func (d *Dog) Name() string {
fmt.Println("我的名字叫旺财")
return "旺财"
}
func main() {
var a Animal
var d Dog
a = &d // 存的指针类型的Dog
a.Eat()
// 值类型实现了一个接口,指针类型可以存储进去
// 指针类型实现了一个接口,值类型存储存储不进去
fmt.Printf("%T %v\n", a, a)
var d1 *Dog = &Dog{}
a = d1
//*(&Dog).Eat() 使用的是指针类型那么定义时候使用
a.Eat()
fmt.Printf("*Dog %T %v\n", a, a)
}
同一类型实现多接口,Animal 和PuruDongWu 都可以实现d,Dog即实现可taisheng的接口,也实现animal接口
package main
import (
"fmt"
)
type Animal interface {
Talk()
Eat()
Name() string
}
type PuruDongWu interface {
TaiSheng()
}
type Dog struct {
}
func (d Dog) Talk() {
fmt.Println("汪汪汪")
}
func (d Dog) Eat() {
fmt.Println("我在吃骨头")
}
func (d Dog) Name() string {
fmt.Println("我的名字叫旺财")
return "旺财"
}
func (d Dog) TaiSheng() {
fmt.Println("狗是胎生的")
}
func main() {
var d Dog
var a Animal
// 开始时 是nil
fmt.Println("%v %T %p", a, a, a) // nil nil nil
if a == nil {
//a.Eat()
fmt.Println("a is nil")
}
a = d
a.Eat()
var b PuruDongWu
b = d
b.TaiSheng()
}
接口嵌套,和结构体嵌套类似
package main
import "fmt"
type Animal interface {
Eat()
Talk()
Name() string
}
type Describle interface {
Describle() string
}
type AdvanceAnimal interface {
Animal
Describle
}
type Dog struct {
}
func (d Dog) Eat() {
fmt.Println("dog is eating")
}
func (d Dog) Talk() {
fmt.Println("dog is talking")
}
func (d Dog) Name() string {
fmt.Println("my name is dog")
return "dog"
}
func (d Dog) Describle() string {
fmt.Println("dog is a dog")
return "dog is a dog"
}
func main() {
var d Dog
var a AdvanceAnimal
a = d
a.Describle()
a.Eat()
a.Talk()
a.Name()
}
Go 反射详解
反射: 动态获取运行时信息
变量的介绍
变量的内在机制
a. 类型信息,这部分是元信息,是预先定义好的
b. 值类型,这部分是程序运行过程中,动态改变的
var arr [10]int
arr[0] = 10
arr[1] = 20
arr[2] = 30
arr[3] = 40
arr[4] = 50
type Animal struct {
Name string
age int
}
var a Animal
反射与空接口
a. 空接口可以存储任何类型的变量
b. 那么给你一个空接口,怎么判断存储的是什么东西? 类型断言判断
c. 在运行时动态的获取一个变量的类型信息和值信息,就叫反射
怎么分析?
a. 内置包 reflect
b. 获取类型信息: reflect.TypeOf
c. 获取值信息: reflect.ValueOf
d. 获取变量的类型: Type.Kind()

通过反射设置变量的值




获取结构体类型相关信息
package main
import (
"fmt"
"reflect"
)
type S struct {
A int
B string
}
func main() {
s := S{23, "skidoo"}
v := reflect.ValueOf(s)
t := v.Type()
for i := 0; i < v.NumField(); i++ {
f := v.Field(i)
fmt.Printf("%d: %s %s = %v\n", i,
t.Field(i).Name, f.Type(), f.Interface())
} }
// 0: A int = 23
// 1: B string = skidoo
设置结构体相关字段的值
v.Elem() 获取的是结构体
v.Elem().Field(0) 获取的就是第一个值 A
v.FieldByName("SetA") 也可以获取对应的值
package main
import (
"fmt"
"reflect"
)
type S struct {
A int
B string
}
func main() {
s := S{23, "skidoo"}
v := reflect.ValueOf(&s)
t := v.Type()
v.Elem().Field(0).SetInt(100)
// 等价 v.Elem().FieldByName("A").SetInt(100)
for i := 0; i < v.Elem().NumField(); i++ {
f := v.Elem().Field(i)
fmt.Printf("%d: %s %s = %v\n", i,t.Elem().Field(i).Name, f.Type(), f.Interface())
} }
获取结构体的方法信息
package main
import (
"fmt"
"reflect"
)
type S struct {
A int
B string
}
func (s *S) Test() {
fmt.Println("this is a test")
}
func main() {
s := S{23, "skidoo"}
v := reflect.ValueOf(&s)
t := v.Type()
v.Elem().Field(0).SetInt(100)
fmt.Println("method num:", v.NumMethod())
for i := 0; i < v.NumMethod(); i++ {
// t获取结构体方法信息,如果调用就是v.method
f := t.Method(i)
fmt.Printf("%d method, name:%v, type:%v\n", i, f.Name, f.Type)
}
}
获取结构体中tag信息
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string `json:"name" db:"name"`
Sex int
Age int
Score float32
//xxx int
}
func (s *Student) SetName(name string) {
s.Name = name
}
func (s *Student) Print() {
fmt.Printf("通过反射进行调用:%#v\n", s)
}
func main() {
var s Student
s.SetName("xxx")
//SetName(&s, "xxx")
v := reflect.ValueOf(&s)
t := v.Type()
//t := reflect.TypeOf(s)
field0 := t.Elem().Field(0)
fmt.Printf("tag json=%s\n", field0.Tag.Get("json"))
fmt.Printf("tag db=%s\n", field0.Tag.Get("db"))
//json.UnMa
var s string
}
反射总结: 反射是在运行时动态的获取一个变量的类型信息和值信息
应用场景
a. 序列化和反序列化,比如json, protobuf等各种数据协议
b. 各种数据库的ORM, 比如gorm,sqlx等数据库中间件
c. 配置文件解析相关的库, 比如yaml、ini等
总之一句话,在一些场景,实现都不知道数据的具体类型,用反射.
Go 并发编程
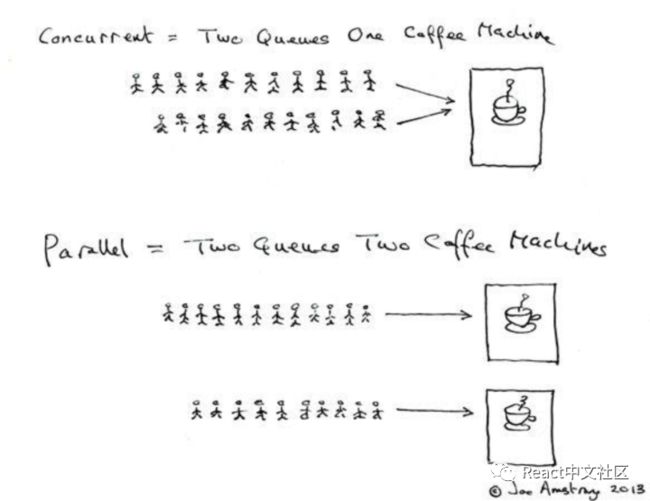
并发与并行
a. 并发:同一时间段内执行多个操作。
b. 并行:同一时刻执行多个操作。
多线程
a. 线程是由操作系统进行管理,也就是处于内核态。
b. 线程之间进行切换,需要发生用户态到内核态的切换。
c. 当系统中运行大量线程,系统会变的非常慢。
d. 用户态的线程,支持大量线程创建。也叫协程或goroutine。
创建goroutine
package main
import (
"fmt"
"time"
)
func hello() {
fmt.Println("hello goroutine")
}
func main() {
go hello()
fmt.Println("main thread terminate")
time.Sleep(time.Second)
}
这个例子中很少会打印出 fmt.Println("hello goroutine"),因为 hello 是单个线程,开了单个线程
所以是和 main 打印一起进行的
修复后:
package main
import (
"fmt"
"time"
)
func hello(i int) {
fmt.Println("hello goroutine", i)
}
func main() {
for i := 0; i < 10; i++ {
go hello(i)
}
time.Sleep(time.Second)
}
// hello goroutine 8
// hello goroutine 7
// hello goroutine 9
// hello goroutine 0
// hello goroutine 3
// hello goroutine 1
// hello goroutine 6
// hello goroutine 4
// hello goroutine 2
// hello goroutine 5
// 每次打印出来都不一样,说明多线程执行是不一致的
启动多个goroutine
主线程退出,子线程也会相应的退出
package main
import (
"fmt"
"time"
)
func numbers() {
for i := 1; i <= 5; i++ {
time.Sleep(250 * time.Millisecond)
fmt.Printf("%d ", i)
}
}
func alphabets() {
for i := 'a'; i <= 'e'; i++ {
time.Sleep(400 * time.Millisecond)
fmt.Printf("%c ", i)
}
}
func main() {
go numbers()
go alphabets()
time.Sleep(3000 * time.Millisecond)
fmt.Println("main terminated")
}
// 1 a 2 3 b 4 c 5 d e main terminated

多核控制
a. 通过runtime包进行多核设置
b. GOMAXPROCS设置当前程序运行时占用的cpu核数
c. NumCPU获取当前系统的cpu核数
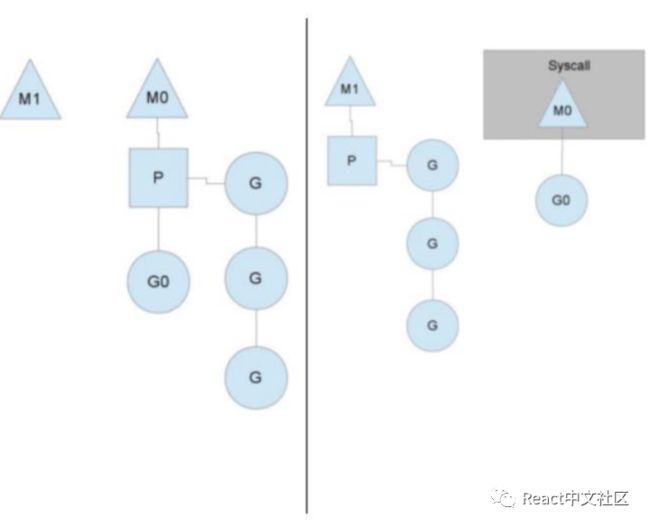
Goroutine原理浅析
a. 一个操作系统线程对应用户态多个goroutine
b. 同时使用多个操作系统线程
c. 操作系统线程对goroutine是多对多关系,即M:N
模型抽象
a. 操作系统线程: M
b. 用户态线程(goroutine): G
c. 上下文对象:P
goroutine调度

系统调用怎么处理
Go channel介绍
a. 本质上就是一个队列,是一个容器
b. 因此定义的时候,需要只定容器中元素的类型
c. var 变量名 chan 数据类型
goroutine调度 之间的通信通过channel进行通信, 定义完chan要进行初始化,不然会是nil,初始化后就可以进行插入元素了
package main
import (
"fmt"
)
func main() {
var c chan int
fmt.Printf("c=%v\n", c)
c = make(chan int, 1)
fmt.Printf("c=%v\n", c)
c <- 100
/*
data := <-c
fmt.Printf("data:%v\n", data)
*/
<-c
}
c=
c=0xc00005a070
元素入队和出队
var a chan int
a. 入队操作,a <- 100
b. 出队操作:data := <- a
初始化时候要进行制定chan的元素,不然会出现死锁的情况
package main
import (
"fmt"
)
func main() {
var c chan int
fmt.Printf("c=%v\n", c)
c = make(chan int, 1)
fmt.Printf("c=%v\n", c)
c <- 100
data := <-c
fmt.Printf("data:%v\n", data)
// <-c
}
不带缓存区的chan队列,入队时候就死锁了,只有消费者存在时候,才可以入队
package main
import (
"fmt"
"time"
)
func produce(c chan int) {
c <- 1000
fmt.Println("produce finished")
}
func consume(c chan int) {
data := <-c
fmt.Println(data)
}
func main() {
var c chan int
fmt.Printf("c=%v\n", c)
c = make(chan int)
go produce(c)
go consume(c)
time.Sleep(time.Second * 5)
}
// c=
// 1000
// produce finished
使用chan来进行goroutine同步 替代sleep函数
package main
import (
"fmt"
"time"
)
func hello(c chan bool) {
time.Sleep(5 * time.Second)
fmt.Println("hello goroutine")
c <- true
}
func main() {
var exitChan chan bool
exitChan = make(chan bool)
go hello(exitChan)
fmt.Println("main thread terminate")
<-exitChan
}
<-exitChan起到了额阻塞主线程的功能,只有在hello线程存入之后才可以会进行取出,
如果chan没有带缓存,存的时候会阻塞,还有,加入没有存,取得时候也会阻塞
单向chan
package main
import "fmt"
// 只可以存数据
func sendData(sendch chan<- int) {
sendch <- 10
//<-sendch
}
// 只可以取数据
func readData(sendch <-chan int) {
//sendch <- 10
data := <-sendch
fmt.Println(data)
}
func main() {
chnl := make(chan int)
go sendData(chnl)
readData(chnl)
}
chan关闭
package main
import (
"fmt"
)
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for {
v, ok := <-ch
if ok == false {
fmt.Println("chan is closed")
break
}
fmt.Println("Received ", v)
}
}
for range操作 程序关闭自动就会关闭,如果管道没有元素,自动阻塞
package main
import (
"fmt"
"time"
)
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
time.Sleep(time.Second)
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for v := range ch {
fmt.Println("receive:", v)
}
}
带缓冲区的chanel
Ch := make(chan type, capacity)
package main
import "fmt"
func main() {
ch := make(chan string, 2)
// var s string
// 如果空的chan 取出时候也会阻塞,死锁
// s = <-ch
ch <- "hello"
ch <- "world"
ch <- "!"
// 如果插入的超过缓存空间,那么久会阻塞
//ch <- "test"
s1 := <-ch
s2 := <-ch
// 先进先出
fmt.Println( s1, s2)
}
channel的长度和容量
Ch := make(chan type, capacity)
package main
import (
"fmt"
)
func main() {
ch := make(chan string, 3)
ch <- "naveen"
ch <- "paul"
fmt.Println("capacity is", cap(ch))
fmt.Println("length is", len(ch))
fmt.Println("read value", <-ch)
fmt.Println("new length is", len(ch))
}
// capacity is 3
// length is 2
// read value naveen
// new length is 1
如何等待一组goroutine结束?
a. 使用不带缓冲区的channel实现
package main
import (
"fmt"
"time" )
func process(i int, ch chan bool) {
fmt.Println("started Goroutine ", i)
time.Sleep(2 * time.Second)
fmt.Printf("Goroutine %d ended\n", i)
ch <- true
}
func main() {
no := 3
exitChan := make(chan bool, no) for i := 0; i < no; i++ {
go process(i, exitChan)
}
for i := 0; I < no;i++{
<-exitChan
}
fmt.Println("All go routines finished executing") }
b. 使用sync.WaitGroup实现
wg *sync.WaitGroup 要传地址,如果传副本,只会修改副本的
package main
import (
"fmt"
"sync"
"time"
)
func process(i int, wg *sync.WaitGroup) {
fmt.Println("started Goroutine ", i)
time.Sleep(2 * time.Second)
fmt.Printf("Goroutine %d ended\n", i)
wg.Done()
}
func main() {
no := 3
var wg sync.WaitGroup
wg.Wait()
fmt.Println("wait return")
for i := 0; i < no; i++ {
wg.Add(1)
go process(i, &wg)
}
wg.Wait()
Go Worker池的实现
a. 生产者、消费者模型,简单有效
b. 控制goroutine的数量,防止goroutine泄露和暴涨
c. 基于goroutine和chan,构建workerpool非常简单
计算一个数字的各个位数之和,比如123,和等于1+2+3=6 B. 需要计算的数字使用随机算法生成
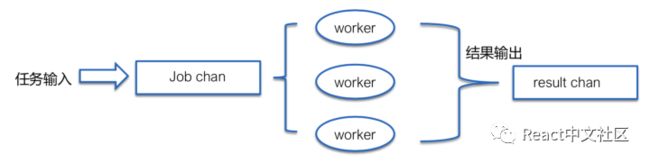
方案介绍
A. 任务抽象成一个个job
B. 使用job队列和result队列
C. 开一组goroutine进行实际任务计算,并把结果放回result队列
package main
import (
"fmt"
"math/rand"
)
type Job struct {
Number int
Id int
}
type Result struct {
job *Job
sum int
}
func calc(job *Job, result chan *Result) {
var sum int
number := job.Number
for number != 0 {
tmp := number % 10
sum += tmp
number /= 10
}
r := &Result{
job: job,
sum: sum,
}
result <- r
}
func Worker(jobChan chan *Job, resultChan chan *Result) {
for job := range jobChan {
calc(job, resultChan)
}
}
func startWorkerPool(num int, jobChan chan *Job, resultChan chan *Result) {
for i := 0; i < num; i++ {
go Worker(jobChan, resultChan)
}
}
func printResult(resultChan chan *Result) {
for result := range resultChan {
fmt.Printf("job id:%v number:%v result:%d\n", result.job.Id, result.job.Number, result.sum)
}
}
func main() {
jobChan := make(chan *Job, 1000)
resultChan := make(chan *Result, 1000)
startWorkerPool(128, jobChan, resultChan)
go printResult(resultChan)
var id int
for {
id++
number := rand.Int()
job := &Job{
Id: id,
Number: number,
}
jobChan <- job
}
}
// job id:1836371 number:1062421083552683812 result:67
// job id:1836372 number:6439169726753483267 result:98
// job id:1836373 number:4936444777724757493 result:103
// job id:1836374 number:596995741200900799 result:91
// job id:1836375 number:2319236362663578637 result:88
// job id:1836376 number:3956317946286456241 result:91
// job id:1836377 number:1555755986829607843 result:103
// job id:1836378 number:6569228944483682098 result:103
// job id:1836379 number:7038879116070115551 result:75
// job id:1836380 number:3382855905395583671 result:95
// job id:1836381 number:482521455470510672 result:68
// job id:1836382 number:6859849441952049848 result:107
Go select语义介绍和使用
多channel场景
多个channel同时需要读取或写入,怎么办?
串行操作? NONONO
package main
import (
"fmt"
"time"
)
func server1(ch chan string) {
time.Sleep(time.Second * 6)
ch <- "response from server1"
}
func server2(ch chan string) {
time.Sleep(time.Second * 3)
ch <- "response from server2"
}
func main() {
output1 := make(chan string)
output2 := make(chan string)
go server1(output1)
go server2(output2)
s1 := <-output1
fmt.Println("s1:", s1)
s2 := <-output2
fmt.Println("s2:", s2)
// select {
// case s1 := <-output1:
// fmt.Println("s1:", s1)
// case s2 := <-output2:
// fmt.Println("s2:", s2)
// default:
// fmt.Println("run default")
// }
}
s1 和s2 会在6s后同时输出
package main
import (
"fmt"
"time"
)
func server1(ch chan string) {
time.Sleep(time.Second * 6)
ch <- "response from server1"
}
func server2(ch chan string) {
time.Sleep(time.Second * 3)
ch <- "response from server2"
}
func main() {
output1 := make(chan string)
output2 := make(chan string)
go server1(output1)
go server2(output2)
// s1 := <-output1
// fmt.Println("s1:", s1)
// s2 := <-output2
// fmt.Println("s2:", s2)
select {
case s1 := <-output1:
fmt.Println("s1:", s1)
case s2 := <-output2:
fmt.Println("s2:", s2)
default:
fmt.Println("run default")
}
}
如果两个chanel 同时唤起,那么两个chanel就是随机的策略
select登场
A. 同时监听一个或多个channel,直到其中一个channel ready
B. 如果其中多个channel同时ready,随机选择一个进行操作。
C. 语法和switch case有点类似,代码可读性更好。
select {
case s1 := <-output1:
fmt.Println(s1)
case s2 := <-output2:
}
fmt.Println(s2)
default分支,当case分支的channel都没有ready的话,执行default
A. 用来判断channel是否满了
B. 用来判断channel是否是空的
package main
import (
"fmt"
"time"
)
func write(ch chan string) {
for {
select {
case ch <- "hello":
fmt.Println("write succ")
default:
fmt.Println("channel is full")
}
time.Sleep(time.Millisecond * 500)
}
}
func main() {
//select {}
output1 := make(chan string, 10)
go write(output1)
for s := range output1 {
fmt.Println("recv:", s)
time.Sleep(time.Second)
}
}
empty select
package main
func main() {
select {
} }
现实例子
A. 多个goroutine同时操作一个资源,这个资源又叫临界区
B. 现实生活中的十字路口,通过红路灯实现线程安全
C. 火车上的厕所,通过互斥锁来实现线程安全
实际例子, x = x +1
A. 先从内存中取出x的值
B. CPU进行计算,x+1
C. 然后把x+1的结果存储在内存中

Go 互斥锁介绍
A. 同时有且只有一个线程进入临界区,其他的线程则在等待锁
B. 当互斥锁释放之后,等待锁的线程才可以获取锁进入临界区
C. 多个线程同时等待同一个锁,唤醒的策略是随机的


读写锁介绍
A. 读写锁使用场景: 读多写少的场景
B. 分为两种角色,读锁和写锁
C. 当一个goroutine获取写锁之后,其他的goroutine获取写锁或读锁都会等待
D. 当一个goroutine获取读锁之后,其他的goroutine获取写锁都会等待, 但其他 goroutine获取读锁时,都会继续获得锁.
package main
import (
"fmt"
"sync"
"time"
)
var rwlock sync.RWMutex
var x int
var wg sync.WaitGroup
func write() {
rwlock.Lock()
fmt.Println("write lock")
x = x + 1
time.Sleep(10 * time.Second)
fmt.Println("write unlock")
rwlock.Unlock()
wg.Done()
}
func read(i int) {
fmt.Println("wait for rlock")
rwlock.RLock()
fmt.Printf("goroutine:%d x=%d\n", i, x)
time.Sleep(time.Second)
rwlock.RUnlock()
wg.Done()
}
func main() {
wg.Add(1)
go write()
time.Sleep(time.Millisecond * 5)
for i := 0; i < 10; i++ {
wg.Add(1)
go read(i)
}
wg.Wait()
}
// write lock
// wait for rlock
// wait for rlock
// wait for rlock
// wait for rlock
// wait for rlock
// wait for rlock
// wait for rlock
// wait for rlock
// wait for rlock
// wait for rlock
// write unlock
// goroutine:0 x=1
// goroutine:4 x=1
// goroutine:7 x=1
// goroutine:8 x=1
// goroutine:5 x=1
// goroutine:3 x=1
// goroutine:9 x=1
// goroutine:2 x=1
// goroutine:6 x=1
// goroutine:1 x=1
Go 读写锁和互斥锁性能比较
互斥锁:
package main
import (
"fmt"
"sync"
"time"
)
var rwlock sync.RWMutex
var x int
var wg sync.WaitGroup
var mutex sync.Mutex
func write() {
for i := 0; i < 100; i++ {
//rwlock.Lock()
mutex.Lock()
x = x + 1
time.Sleep(10 * time.Millisecond)
mutex.Unlock()
//rwlock.Unlock()
}
wg.Done()
}
func read(i int) {
for i := 0; i < 100; i++ {
//rwlock.RLock()
mutex.Lock()
time.Sleep(time.Millisecond)
mutex.Unlock()
//rwlock.RUnlock()
}
wg.Done()
}
func main() {
start := time.Now().UnixNano()
wg.Add(1)
go write()
for i := 0; i < 100; i++ {
wg.Add(1)
go read(i)
}
wg.Wait()
end := time.Now().UnixNano()
cost := (end - start) / 1000 / 1000
fmt.Println("cost:", cost, "ms")
}
// [Running] go run "/Users/zll/Desktop/gostudy/listen21/rw_vs_mutex/main.go"
// cost: 13627 ms
// [Done] exited with code=0 in 14.249 seconds
// [Running] go run "/Users/zll/Desktop/gostudy/listen21/rw_vs_mutex/main.go"
// cost: 13568 ms
// [Done] exited with code=0 in 14.03 seconds
读写锁:
package main
import (
"fmt"
"sync"
"time"
)
var rwlock sync.RWMutex
var x int
var wg sync.WaitGroup
var mutex sync.Mutex
func write() {
for i := 0; i < 100; i++ {
rwlock.Lock()
// mutex.Lock()
x = x + 1
time.Sleep(10 * time.Millisecond)
// mutex.Unlock()
rwlock.Unlock()
}
wg.Done()
}
func read(i int) {
for i := 0; i < 100; i++ {
rwlock.RLock()
// mutex.Lock()
time.Sleep(time.Millisecond)
// mutex.Unlock()
rwlock.RUnlock()
}
wg.Done()
}
func main() {
start := time.Now().UnixNano()
wg.Add(1)
go write()
for i := 0; i < 100; i++ {
wg.Add(1)
go read(i)
}
wg.Wait()
end := time.Now().UnixNano()
cost := (end - start) / 1000 / 1000
fmt.Println("cost:", cost, "ms")
}
// [Running] go run "/Users/zll/Desktop/gostudy/listen21/rw_vs_mutex/main.go"
// cost: 1251 ms
// [Done] exited with code=0 in 1.518 seconds
// [Running] go run "/Users/zll/Desktop/gostudy/listen21/rw_vs_mutex/main.go"
// cost: 1273 ms
// [Done] exited with code=0 in 1.477 seconds
Go 原子操作
A. 加锁代价比较耗时,需要上下文切换
B. 针对基本数据类型,可以使用原子操作保证线程安全
C. 原子操作在用户态就可以完成,因此性能比互斥锁要高
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
var x int32
var wg sync.WaitGroup
var mutex sync.Mutex
func addMutex() {
for i := 0; i < 500; i++ {
mutex.Lock()
x = x + 1
mutex.Unlock()
}
wg.Done()
}
func add() {
for i := 0; i < 500; i++ {
//mutex.Lock()
//x = x +1
atomic.AddInt32(&x, 1)
//mutex.Unlock()
}
wg.Done()
}
func main() {
start := time.Now().UnixNano()
for i := 0; i < 10000; i++ {
wg.Add(1)
go add()
//go addMutex()
}
wg.Wait()
end := time.Now().UnixNano()
cost := (end - start) / 1000 / 1000
fmt.Println("x:", x, "cost:", cost, "ms")
}
推荐阅读
(点击标题可跳转阅读)
RxJS入门
一文掌握Webpack编译流程
一文深度剖析Axios源码
Javascript条件逻辑设计重构
Promise知识点自测
你不知道的React Diff
你不知道的GIT神操作
程序中代码坏味道(上)
程序中代码坏味道(下)
学习Less,看这篇就够了
一文掌握GO语言实战技能(一)
一文掌握GO语言实战技能(二)
一文掌握Linux实战技能-系统管理篇
一文掌握Linux实战技能-系统操作篇
一文达到Mysql实战水平
一文达到Mysql实战水平-习题答案
从表单抽象到表单中台
vue源码分析(1)- new Vue
实战LeetCode 系列(一) (题目+解析)
一文掌握Javascript函数式编程重点
实战LeetCode - 前端面试必备二叉树算法
一文读懂 React16.0-16.6 新特性(实践 思考)
阿里、网易、滴滴、今日头条、有赞.....等20家面试真题
30分钟学会 snabbdom 源码,实现精简的 Virtual DOM 库
觉得本文对你有帮助?请分享给更多人
关注「React中文社区」加星标,每天进步
