前端面试题JS原理部分(四)异步,eventloop
1、 对JS单线程的理解
- JS的runtime
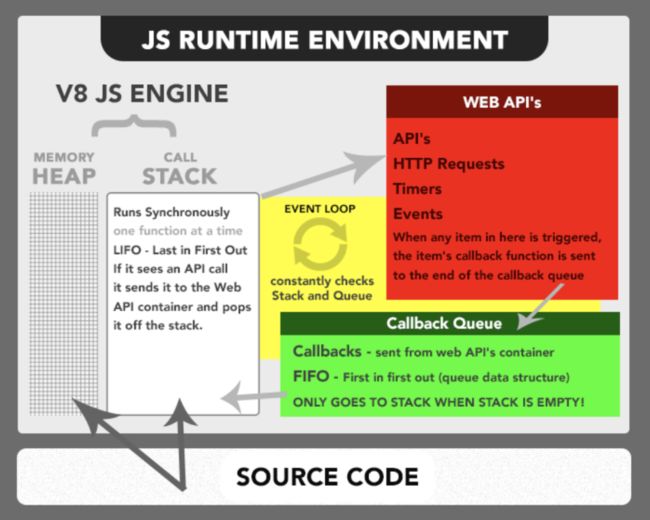
JS运行环境(run time)指的是,你的代码将在什么浏览器环境下运行。JS的编译是在浏览器中完成的。可把运行环境,比较粗暴的分成JS引擎(图中的V8 JS Engine)和web API两部分,如果我们不了解这个基本框架,将难以理解异步和同步的区别。
同步(或者单线程)的理解是JS引擎下的编码规范:每次运行一个函数,遵循后进先出的原则。
console.log("Start")
function sayHello(name){
console.log(`Hello $ {name}!`))
}
sayHello("world");
console.log("end");
\\运行结果
\\start
\\Hello world
\\end
[注]对于后进先出不了解的,可以模拟一下recursion函数是怎么运行的
[注]可以读一下这篇博文,写的非常好。
2、 以setTimeout为例谈一谈异步,以及event Loop。
首先要理解JS引擎没有异步,异步是由webAPI提供的的功能,带时序的都是异步如XHRhttp和setTimeout。一旦代码请求调用异步API,那么异步代码会屏蔽掉,接着顺序执行后面的代码。屏蔽掉的代码,在browser得到返回许可后,在Callback/Task/Event queue(都是一种东西,有不同的叫法)中等待。通过Event loop时刻查询JS的call stack情况,等到栈为空的时候,进栈执行。

setTimeout(function(){
console.log("Start")
},0);
function sayHello(name){
console.log(`Hello $ {name}!`))
}
sayHello("world");
console.log("end");
\\运行结果
\\Hello world
\\end
\\start
3、 什么promise函数?怎样执行异步操作?
Promise函数为JS提供了异步处理的框架。它可以(未必是最优选)处理网络请求和动画。ajax和axios的底子都是promise。
- Promise执行步骤
promise执行之后,会立刻返回一个对象。对象包含三部分,状态,值,和如果有结果了继续执行的函数。
然后接着执行接下来的代码,需要异步执行的部分,例如发送一个XHR请求,发送给web browser执行就好。等到value返回,status为resolve的时候返回的对象:
onfulfillment里面附加的then传入的函数队列依次进入microtask queue中,当call stack为空的时候,再依次进入call stack执行。- 这里出现了一个新的概念什么是miscrotask queue?
细究起来可以写一篇小论文了,这里为了快速方面理解可以粗浅的理解:
- microtask queue是与task/callback/event queue并列的存在
- microtask queue优于task/callback/event queue优先进栈



setTimeout(function(){
console.log("Start")
},0);
function sayHello(name){
console.log(`Hello $ {name}!`))
}
new Promise((resovle,reject)=>{
//do something like send a XHRrequest
}).then(()=>{sayHello("world"); });
console.log("end");
\\运行结果
\\end
\\Hello world
\\start
[注]promise在IE浏览器上支持的不好,如果XHRhttp好的大神可以自己写,使用ES5的语法貌似可以在IE11上支持,我这种懒人会选择直接用axios或ajax。
4、 如果给a,b,c,d四个时间,执行时间分别为1,2,3,4,怎么样做才能在abc都执行完后再执行d
最土的方法就是用嵌套setTimeout来完成
这是最典型的callback hell的案例
使用递归会把代码写的漂亮一些,但本质改变不了callback hell
上面介绍那么多,最好的方案使用promise来做。



5、 ES6 generator
理解generator一般是要和iterator放在一起理解的。这两个都是数据流处理的操作符。如果使用过github,形象一点比喻的话,iterator是就是pull数据的过程,而generator就是push和pull数据的过程。
- iterator的底层核心
\\自己写一个iterator函数
function createFunction(array){
let i = 0;
function inner(){
const element = array[i];
i++;
return element;
}
return inner;
}
const nextElement = createFunction([4,5,6]);
nextElement();//4
nextElement();//5
nextElement();//6
- generator的yield
generator最核心的底层理解是yield的部分,它可以在iterator执行next的过程中变更数据。
function *createFlow(){
const num = 10;
const newNum = yield num;
yield 5+newNum;
yield 6;
}
const nextElement = createFlow();
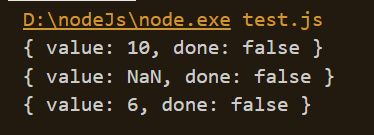
nextElement.next();//10
nextElement.next(2);//7
yield的级别要高于赋值,为什么第二个nextElement.next(2)的结果为7,是因为newNum没有赋上10的值,而是直接通过yield流出去了,此时整个程序处于暂停的状态,newNum为undefined, 第二次nextElement.next(2),重新开始播放,流入的数据2正好给空位的newNum赋上了值,此时newNum = 2。如果我不给第二个赋值,就会使NaN了。
6、 ES6 async await
async await的本质是promise+generator
function *createFlow(){
let data = yield fetch(...)
console.log(data);
}
const nextElement = createFlow();
function recieveData(value){
nextElement.next();
}
const futureData = nextElement.next();//yield抛出一个promise,data为undefined
futureData.then(recieveData)//data值成功返回,启动下一步console.log(data);
上面的就是async await的底层逻辑,使用async await简化为
async function createFlow() {
console.log("Me first!");
let data = fetch("...");//返回"I'am the data"
console.log(data);
}
createFlow();
console.log("Me second!");
//打印结果
//Me first!
//Me second!
//I'am the data!
注async await浏览器的支持度不高,使用面不广。比较成熟的方案是使用Observable来处理网络并行。
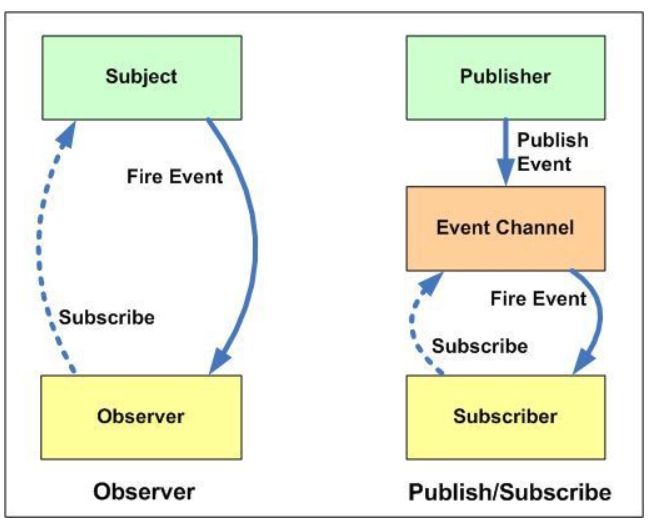
7、 观察者模式和订阅者模式如何实现
我之前有专门的写过观察者模式的实现
观察者模式的本质是observer的集合this.observer = [], observer可以理解成我需要对观察的events做什么操作(observer.push(f))集合。
pub-sub模式多了一步publisher,它动态的接受着event
function pubSub() {
const subscribers = {}
function publish(eventName, data) {
if (!Array.isArray(subscribers[eventName])) {
return
}
subscribers[eventName].forEach((callback) => {
callback(data)
})
}
function subscribe(eventName, callback) {
if (!Array.isArray(subscribers[eventName])) {
subscribers[eventName] = []
}
subscribers[eventName].push(callback)
}
return {
publish,
subscribe,
}
}
pub-sub最核心的代码就是这段,和observer的区别如下:
- 明显看出来和observer收集的数据结构就是不一样的,observer收集的是function,eventbus收集的是个object,{eventName:callback}
- pubsub通过publish增加了一个动态的添加入口,observer是hardcore好的集合是死的。
注这部分有点深,后面有时间在写一篇专门将清除pub-sub的,有能力的同学可以先参考我找到的资料。
pub-sub参考文献1
pub-sub参考文献2
pub-sub参考文献3
pub-sub参考文献4