R语言数据清洗实验内容
在 R 语言中,可以使用函数 is.na()判断缺失值是否存在,缺失值通常以 NA 表示。另外 函数 complete.case()也可识别样本数据是否完整从而判断缺失情况。 在异常值处理之前需要对异常值进行识别,一般多采用单变量散点图或是箱状图进行表 示。在 R 中,使用函数 dotchart()、boxplot()实现绘制单变量散点图与箱形图。
实验目的 ① 掌握 R 语言中数据清洗的常用函数; ② 掌握数据的导入导出; ③ 熟悉 R 语言对数据清洗的一般思路。
实验内容 ① 将 bank-additional-full.csv 数据导入到 R; ② 对数据中的缺失值、异常值以及不一致值进行识别和处理。
> mydata<-read.csv("bank-additional-full.csv",sep=";")
> mydata$job[which(mydata$job=='unknown')]<-NA
> mydata$default[which(mydata$default=='unknown')]<-NA
> mydata$education[which(mydata$education=='unknown')]<-NA
> mydata$housing[which(mydata$housing=='unknown')]<-NA
> mydata_2<-is.na(mydata)
> head(mydata_2,3)
age job marital education default housing loan contact month
[1,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
day_of_week duration campaign pdays previous poutcome emp.var.rate
[1,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE
cons.price.idx cons.conf.idx euribor3m nr.employed y
[1,] FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE
> mydata_3<-complete.cases(mydata)
> head(mydata_3,5)
[1] TRUE FALSE TRUE TRUE TRUE
> mydata_4<-mydata[!complete.cases(mydata),]
> head(mydata_4,3)
age job marital education default housing loan contact month
2 57 services married high.school
6 45 services married basic.9y
8 41 blue-collar married
day_of_week duration campaign pdays previous poutcome emp.var.rate
2 mon 149 1 999 0 nonexistent 1.1
6 mon 198 1 999 0 nonexistent 1.1
8 mon 217 1 999 0 nonexistent 1.1
cons.price.idx cons.conf.idx euribor3m nr.employed y
2 93.994 -36.4 4.857 5191 no
6 93.994 -36.4 4.857 5191 no
8 93.994 -36.4 4.857 5191 no
> colSums(is.na(mydata))
age job marital education default
0 330 0 1731 8597
housing loan contact month day_of_week
990 0 0 0 0
duration campaign pdays previous poutcome
0 0 0 0 0
emp.var.rate cons.price.idx cons.conf.idx euribor3m nr.employed
0 0 0 0 0
y
0
> sum(!complete.cases(mydata))
[1] 10641
> mean(!complete.cases(mydata))
[1] 0.2583519
> mydata_5<-na.omit(mydata)
> head(mydata_5,3)
age job marital education default housing loan contact month
1 40 housemaid married basic.4y no no no telephone may
3 37 services married high.school no yes no telephone may
4 40 admin. married basic.6y no no no telephone may
day_of_week duration campaign pdays previous poutcome emp.var.rate
1 mon 261 1 999 0 nonexistent 1.1
3 mon 226 1 999 0 nonexistent 1.1
4 mon 151 1 999 0 nonexistent 1.1
cons.price.idx cons.conf.idx euribor3m nr.employed y
1 93.994 -36.4 4.857 5191 no
3 93.994 -36.4 4.857 5191 no
4 93.994 -36.4 4.857 5191 no
> mydata$age[which(mydata$age=='56')]<-NA
> mydata$age[is.na(mydata$age)]<-round(mean(mydata$age,na.rm = TRUE))
> head(mydata$age,5)
[1] 40 57 37 40 40
> mydata$job[which(mydata$job=='unknown')]<-NA
> mydata_clear1<-na.omit(mydata)
> mydata_clear2<-subset(mydata_clear1,select = -poutcome)
> set.seed(1)
> index<-sample(1:nrow(mydata_clear2),5)
> index
[1] 17401 24388 4775 26753 13218
> mydata_clear2$age[index]
[1] 36 36 46 32 39
> mydata_clear2$age[index]<-mydata_clear2$age[index]*3
> mydata_clear2$age[index]
[1] 108 108 138 96 117
> boxplot(mydata_clear2$age,boxwex=0.7)
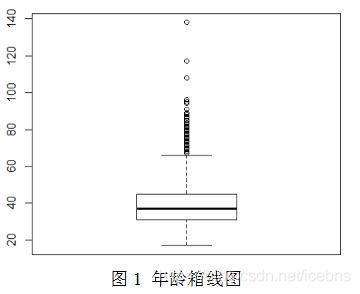
> index2<-which(mydata_clear2$age>=80)
> mydata_clear2<-mydata_clear2[-index2,]
> head(mydata_clear2,5)
age job marital education default housing loan contact
1 40 housemaid married basic.4y no no no telephone
3 37 services married high.school no yes no telephone
4 40 admin. married basic.6y no no no telephone
5 40 services married high.school no no yes telephone
7 59 admin. married professional.course no no no telephone
month day_of_week duration campaign pdays previous emp.var.rate
1 may mon 261 1 999 0 1.1
3 may mon 226 1 999 0 1.1
4 may mon 151 1 999 0 1.1
5 may mon 307 1 999 0 1.1
7 may mon 139 1 999 0 1.1
cons.price.idx cons.conf.idx euribor3m nr.employed y
1 93.994 -36.4 4.857 5191 no
3 93.994 -36.4 4.857 5191 no
4 93.994 -36.4 4.857 5191 no
5 93.994 -36.4 4.857 5191 no
7 93.994 -36.4 4.857 5191 no
> x<-list(a=1:10,beta=exp(-3:3),logic=c(TRUE,FALSE,FALSE,TRUE))
> x
$a
[1] 1 2 3 4 5 6 7 8 9 10
$beta
[1] 0.04978707 0.13533528 0.36787944 1.00000000 2.71828183 7.38905610
[7] 20.08553692
$logic
[1] TRUE FALSE FALSE TRUE
> probs<-c(1:3/4)
> rt.value<-c(0,0,0)
> vapply(x, quantile, FUN.VALUE = rt.value, probs=probs)
a beta logic
25% 3.25 0.2516074 0.0
50% 5.50 1.0000000 0.5
75% 7.75 5.0536690 1.0
> probs<-c(1:4/4)
> vapply(x, quantile, FUN.VALUE = rt.value, probs=probs)
Error in vapply(x, quantile, FUN.VALUE = rt.value, probs = probs) :
值的长度必需为3,
但FUN(X[[1]])结果的长度却是4
> rt.value<-c(0,0,0,0)
> vapply(x, quantile, FUN.VALUE = rt.value, probs=probs)
a beta logic
25% 3.25 0.2516074 0.0
50% 5.50 1.0000000 0.5
75% 7.75 5.0536690 1.0
100% 10.00 20.0855369 1.0
> rt.value<-c(0,0,0,"")
> vapply(x, quantile, FUN.VALUE = rt.value, probs=probs)
Error in vapply(x, quantile, FUN.VALUE = rt.value, probs = probs) :
值的种类必需是'character',
但FUN(X[[1]])结果的种类却是'double'