Python数据清洗--类型转换和冗余数据删除
还没关注?

快动动手指!
前言
数据分析过程中最头疼也是工作量最大的部分算是探索和清洗了,探索的目的是了解数据,了解数据背后隐藏的规律,清洗的目的则是为了让干净的数据进入分析或建模的下一个环节。作者将通过三篇文章,详细讲解工作中常规的数据清洗方法,包括数据类型的转换,重复数据的处理,缺失值的处理以及异常数据的识别和处理。这是第一篇文章,主要分享的内容包括,文中涉及到的数据可以至文末查看下载链接:
数据类型的转换
冗余数据的识别和处理
数据类型的判断和转换
如下表所示,为某公司用户的个人信息和交易数据,涉及的字段为用户id、性别、年龄、受教育水平、交易金额和交易日期。从表面上看,似乎没有看出数据背后可能存在的问题,那接下来就将其读入到Python中,并通过探索的方式发现数据中的问题。

读取数据,以及查看数据规模、查看数据中各变量的数据类型的代码如下:
# 导入第三方包import pandas as pd# 读入外部数据data3 = pd.read_excel(io=r'C:\Users\Administrator\Desktop\datas\data3.xlsx')# 查看数据的规模data3.shapeout:(3000, 6)# 查看表中各变量的数据类型# data3.dtypesout:表中各变量的数据类型如表下表所示:

上述代码利用shape“方法”返回了数据集的规模,即该数据包含3000行6列;通过dtypes“方法”则返回了数据集中各变量的数据类型——除id变量和age变量为数值型,其余变量均为字符型。直观上能够感受到一点问题,即数据类型不对,例如用户id应该为字符型,消费金额custom_amt为数值型,订单日期为日期型。如果发现数据类型不对,如何借助于Python工具实现数据类型的转换呢?可参照如下代码的实现。
# 数值型转字符型data3['id'] = data3['id'].astype(str)# 字符型转数值型data3['custom_amt'] = data3['custom_amt'].str[1:].astype(float)# 字符型转日期型data3['order_date'] = pd.to_datetime(data3['order_date'], format = '%Y年%m月%d日')# 重新查看数据集的各变量类型data3.dtypesout:这些数据经过处理后,各个字段的数据类型如下表所示:

如上结果所示,三个变量全都转换成了各自所期望的数据类型。astype“方法”用于数据类型的强制转换,可选择的常用转换类型包括str(表示字符型)、float(表示浮点型)和int(表示整型)。由于消费金额custom_amt变量中的值包含人民币符号“¥”,所以在数据类型转换之前必须将其删除(通过字符串的切片方法删除,[1:]表示从字符串的第二个元素开始截断)。对于字符转日期问题,推荐使用更加灵活的to_datetime函数,因为它在format参数的调节下,可以识别任意格式的字符型日期值。
需要注意的是,Python中的函数有两种表现形式,一种是常规理解下的函数(语法为func(parameters),如to_datetime函数),另一种则是“方法”(语法为obj.func(parameters),如dtypes和astype“方法”)。两者的区别在于 “方法”是针对特定对象的函数(即该“方法”只能用在某个固定类型的对象上),而函数并没有这方面的限制。
基于如上类型的转换结果,最后浏览一下数据的展现形式:
# 预览数据的前5行data3.head()
冗余数据的判断和处理
如上过程是对数据中各变量类型的判断和转换,除此还需要监控表中是否存在“脏”数据,如冗余的重复观测和缺失值等。可以通过duplicated“方法”进行 “脏”数据的识别和处理。仍然对上边的data3数据为例进行操作,具体代码如下所示。
# 判断数据中是否存在重复观测data3.duplicated().any()out:False如上结果返回的是False,说明该数据集中并不存在重复观测。假如读者利用如上的代码在数据集中发现了重复观测,可以使用drop_duplicates“方法”将冗余信息删除。
需要说明的是,在使用duplicated“方法”对数据行作重复性判断时,会返回一个与原数据行数相同的序列(如果数据行没有重复,则对应False,否则对应True),为了得到最终的判断结果,需要再使用any“方法”(即序列中只要存在一个True,则返回True)。
duplicated“方法”和drop_duplicates“方法”都有一个非常重要的参数,就是subset。默认情况下不设置该参数时,表示对数据的所有列进行重复性判断;如果需要按指定的变量做数据的重复性判断时,就可以使用该参数指定具体的变量列表。举例如下:
# 构造数据df = pd.DataFrame(dict(name = ['张三','李四','王二','张三','赵五','丁一','王二'], gender = ['男','男','女','男','女','女','男'], age = [29,25,27,29,21,22,27], income = [15600,14000,18500,15600,10500,18000,13000], edu = ['本科','本科','硕士','本科','大专','本科','硕士']))# 查看数据df
目测有两条数据完全一样,就是用户张三,如果直接使用drop_duplicates“方法”,而不做任何参数的修改时,将会删除第二次出现的用户张三。代码如下:
# 默认情况下,对数据的所有变量进行判断df.drop_duplicates()
假设在数据清洗中,用户的姓名和年龄相同就认为是重复数据,那么该如何基于这两个变量进行重复值的删除呢?此时就需要使用subset参数了,代码如下:
df.drop_duplicates(subset=['name','age'])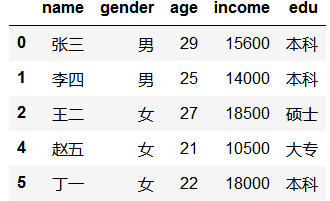
需要注意的是,使用drop_duplicates“方法”删除重复数据,并不能直接影响到原始数据,即原始数据中还是存在重复观测的。如需使drop_duplicates“方法”的删除功能作用在原始数据中,必须将inplace参数设置为True。
结语
本期的内容就介绍到这里,下一期将分享缺失值的识别和处理技术,如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。
每天进步一点点:数据分析1480

长按扫码关注我
链接:https://pan.baidu.com/s/1tK1zDSwQ7K5o5D69727pGQ
提取码:kgv2