对于JavaScript动态渲染的页面,一般可以分析Ajax来获取数据,但是很多网页的Ajax接口含有很多加密参数,很难找到规律,很难分析Ajax来抓取数据。
------->直接使用模拟浏览器运行的方式,做到在浏览器中看到是什么样,抓取的源码就是什么样,也就是可见即可爬。不用管Ajax接口的参数!
Python提供了许多模拟浏览器运行的库,如Selenium 、Splash 、PyV8 , Ghost 等。本帖主要介绍Selenium的使用。
注:本帖以Chrome为例来讲解Selenium的用法。在开始之前,请确保已经正确安装好了Chrome 浏览器并配置好了ChromeDriver。另外,还需要正确安装好Python的Selenium 库。
1、小例子:--->大致看下Selenium的功能
from selenium import webdriver from selenium.webdriver.common.by import By #用于选择元素 from selenium.webdriver.common.keys import Keys #用于文本框的输入 from selenium.webdriver.support import expected_conditions as EC #用于错误的提示 from selenium.webdriver.support.wait import WebDriverWait #用于等待 browser=webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe') try: browser.get('https://www.baidu.com/') input=browser.find_element(By.ID,'kw') #有很多种方法,下面介绍 input.send_keys('pansy_nuist') input.send_keys(Keys.ENTER) #相当于点击回车键 wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_left'))) print(browser.current_url) #当前网页的url print(browser.get_cookies()[0]) #当前网页的Cookies【部分】 print(browser.page_source[:100]) #当前网页的源代码【部分】 finally: browser.quit() #或者browser.close()
运行代码后发现,会自动弹出一个Chrome 浏览器。浏览器首先会跳转到百度,然后在搜索框中输入pansy_nuist, 接着跳转到搜索结果页,如下图:
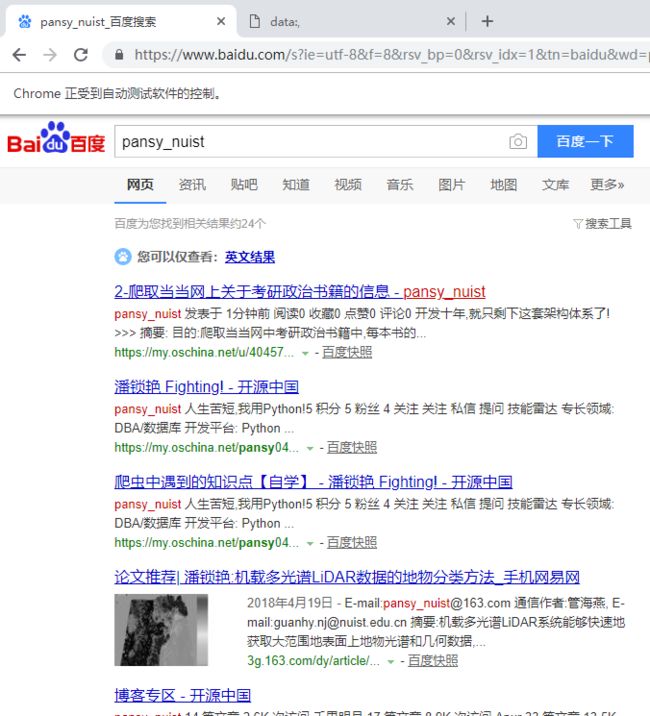
"""结果显示:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=pansy_nuist&rsv_pq=fb580c99000617f7&rsv_t=f7453fNhfB3Mmg7BbV3ZOLs%2FkSmEcJ1anK%2BOzEpvtwzTe4Hg5esxU7o46SI&rqlang=cn&rsv_enter=1&rsv_sug3=11&rsv_sug2=0&inputT=126&rsv_sug4=126
{'httpOnly': False, 'path': '/', 'secure': False, 'domain': '.baidu.com', 'name': 'H_PS_PSSID', 'value': '1447_21127_28132_28267_27245_22159'}
所以说,如果用Selenium来驱动浏览器加载网页的话,可以直接拿到JavaScript渲染的结果了,不用担心使用的是什么加密系统。
2、申明浏览对象
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。【注:与无界面浏览器PhantomJS已经分手!】。
使用如下方式初始化:【注:需要在其中传入executable_path,就是各个浏览器的驱动】
from selenium import webdriver
browser=webdriver.Chrome()
browser=webdriver.Firefox()
browser=webdriver.Edge()
browser=webdriver.Safari()
这样就完成了浏览器对象的初始化并将其赋值为browser对象。接下来,我们要做的就是调用browser对象,让其执行各个动作以模拟浏览器操作!
3、访问页面
get()方法来请求网页,参数传入链接URL即可。
#例:用get()方法访问淘宝,然后打印出源代码。
from selenium import webdriver
browser=webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.taobao.com')
print(browser.page_source[:100])
browser.close()
4、查找节点【很重要!】
Selenium提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
4-1 单个节点
比如,想要从淘宝页面中提取搜索框这个节点,首先要观察它的源代码,如图:

可以发现,它的id是q, name也是q。此外,还有许多其他属性,此时我们就可以用多种方式获取它了。
比如,find element_by_name()是根据name值获取, find element_by_id()是根据id获取。另外,还有根据XPath、css选择器等获取的方式。
from selenium import webdriver
browser=webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.taobao.com')
input1=browser.find_element_by_id('q') #根据id获取节点
input2=browser.find_element_by_name('q') #根据name获取节点
input3=browser.find_element_by_xpath('//*[@id="q"]') #根据Xpath获取节点
input4=browser.find_element_by_css_selector('#q') #根据CSS选择器获取节点
print(input1)
print(input2)
print(input3)
print(input4)
结果显示:这3 个节点都是Web Element 类型。
这里列出所有获取单节点的方法:【重要!】
find_element_by_id
find_element_by_name
find_element_by_xapth
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
Selenium还提供了通用方法find_element(),它需要传入两个参数: 查找方式By和值。通用函数版本。
比如find_element _by_id(id)就等价于find_element(By.ID, id)。二者得到的结果完全一致。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser=webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.taobao.com')
input1=browser.find_element_by_id('q') #find_element_by_id
input2=browser.find_element(By.ID,'q') #函数版本
print(input1)
print(input2)
"""结果显示:
"""
注:函数版本的查找单个节点----->参数更加灵活!
4-2 多个节点
对于多个节点,采用find_elements()这样的方法。比上述element多了一个s。
比如,要查找淘宝左侧导航条的所有条目,如图:


发现这些条目存放在所有li标签下:
from selenium import webdriver
browser=webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.taobao.com')
lis=browser.find_elements_by_css_selector('.service-bd li')
print(lis)
print(len(lis))
browser.close()
结果显示:
[, ......, ] #省略写的
16
用find_elements()方法,则结果是列表类型,列表中的每个节点是Web Element 类型
这里列出所有获取多个节点的方法:【重要!】
find_elements_by_id
find_elements_by_name
find_elements_by_xapth
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
Selenium还提供了通用方法find_elements(),它需要传入两个参数: 查找方式By和值。通用函数版本。
比如上述:lis=browser.find_elements(By.CSS_SELECTOR,'.service-bd li') 结果相同!
5、节点交互
Selenium 可以让浏览器模拟执行一些动作。
比较常见的用法有:输入文字时用send_keys()方法,清空文字时用clear()方法,点击按钮时用click()方法。
from selenium import webdriver
import time
browser=webdriver.Chrome(r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.taobao.com')
shuru=browser.find_element_by_id('q')
shuru.send_keys('iPhone') #输入:IPhone
time.sleep(1)
shuru.clear() #清空输入
shuru.send_keys('iPad')
button=browser.find_element_by_class_name('btn-search') #找到“搜索”
button.click() #点击“搜索”
说明:这里首先驱动浏览器打开淘宝,然后用find_element_by_id()方法获取输入框,然后用send_keys()方法输入iPhone 文字,等待一秒后用clear()方法清空输入框,再次调用send_keys ()方法输入iPad文字,之后再用find_element_by_class_name()方法获取搜索按钮,最后调用click()方法完成搜索动作。
6、动作链
有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
#实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url='http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame ('iframeResult')
source=browser.find_element_by_css_selector('#draggable')
target=browser.find_element_by_css_selector('#droppable')
actions=ActionChains(browser)
actions.drag_and_drop(source,target)
actions.perform()
 【执行前】
【执行前】  【执行后】
【执行后】
说明:首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明ActionChains对象并将其赋值为actions变量,然后通过调用actions变量的drag_and_drop()方法,再调用perform()方法执行动作,此时就完成了拖曳操作,
7、执行JavaScript----->【比如:下拉进度条】
#下拉进度条,它可以直接模拟运行JavaScript,此时使用execute_script()方法即可实现:
from selenium import webdriver
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
说明:这里就利用execute_script ()方法将进度条下拉到最底部,然后弹出alert提示框。
8、获取节点信息
通过page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup 、pyquery 等)来提取信息了。
Selenium已经提供了选择节点的方法,返回的是Web Element 类型,那么它也有相关的方法和属性来直接提取节点信息,如属性、文本等。
8-1 获取属性 get_attribute()
使用get_attribute()方法来获取节点的属性,但是其前提是先选中这个节点。
from selenium import webdriver
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.zhihu.com/explore')
logo=browser.find_element_by_id('zh-top-link-logo') #选中logo节点
print(logo)
print(logo.get_attribute('class')) #获取class属性对应的值
结果显示:
zu-top-link-logo
说明:运行之后,程序便会驱动浏览器打开知乎页面,然后获取知乎的logo 节点,最后打印出它的class。
通过get_attribute()方法,然后传人想要获取的属性名,就可以得到它的值了。
8-2 获取文本值 .text
from selenium import webdriver
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.zhihu.com/explore')
logo=browser.find_element_by_id('zh-top-link-logo')
print(logo.text) #知乎
这里依然先打开知乎页面,然后获取知乎logo这个节点,再将其文本值打印出来。
8-2 获取id、位置、标签名和大小 .id .location .tag_name .size
Web Element节点还有一些其他属性,比如id属性可以获取节点id, location属性可以获取该节点在页面中的相对位置,tag_name 属性可以获取标签名称,size属性可以获取节点的大小,也就是宽高......
from selenium import webdriver
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.zhihu.com/explore')
shuru=browser.find_element_by_class_name('zu-top-add-question') #获取提问按钮
print(shuru.id) #0.9948624410389306-1
print(shuru.location) #{'y': 7, 'x': 675}
print(shuru.tag_name) #button
print(shuru.size) #{'width': 66, 'height': 32}
说明:这里首先获得“提问”按钮这个节点,然后调用其id、location、tag_name、size属性来获取对应的属性值。
9、切换Frame switch_to.frame()
我们知道网页中有一种节点叫作iframe,也就是子Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium打开页面后,它默认是在父级Frame里面操作,而此时如果页面中还有子Frame,它是不能获取到子Frame里面的节点的。这时就需要使用switch_to.frame()方法来切
换Frame。
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
url='http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult') #切换到子frame
try:
logo=browser.find_element_by_class_name('logo') #尝试获取父级frame中的logo节点
except NoSuchElementException: #注:子frame里面找不到,∴打印‘NO LOGO’
print('NO LOGO')
browser.switch_to.parent_frame() #切换回父级frame中获取logo节点
logo=browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
结果显示:
NO LOGO
RUNOOB.COM
当页面中包含子Frame时,如果想获取子Frame中的节点,需要先调用switch_to.frame()方法切换到对应的Frame,然后再进行操作。
10、延时等待------>【常用显示等待】
需要延时等待一定时间,确保节点已经加载出来。
10-1 隐式等待 .implicitly_wait()
此时:如果Selenium 没有在DOM中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0。
from selenium import webdriver
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.implicitly_wait(10) #隐式等待
browser.get('https://www.zhihu.com/explore')
shuru=browser.find_element_by_class_name('zu-top-add-question')
print(shuru) #
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。
10-2 显示等待 from selenium.webdriver.support.ui import WebDriverWait
此时:它指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点; 如果到了规定时间依然没有加载出该节点,则抛出超时异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.taobao.com/')
wait=WebDriverWait(browser,10) #显示等待
shuru=wait.until(EC.presence_of_element_located((By.ID,'q')))
button=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search')))
print(shuru) #
print(button) #
说明:首先引人WebDriverWait 这个对象,指定最长等待时间,然后调用它的until()方法,传人要等待条件expected_conditions。比如,这里传入了presence_of_element located这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框。
这样可以做到的效果就是,在10 秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。
对于按钮,可以更改一下等待条件,比如改为element_to_be_clickable,也就是可点击,所以查找按钮时查找css选择器为.btn-search的按钮,如果10秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过10 秒还不可点击,也就是没有加载出来,就抛出异常。
下表是所有的等待条件及含义:
| 等待条件 | 含义 |
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出来,传入定位元祖,如(By.ID,'p') |
| visibility_of_element_located | 节点可见,传入定位元祖 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出来 |
| text_to_be_present_in_element | 某个节点文本包含某文字 |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否仍在DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传入定位元祖 |
| element_selection_state_to_be | 传入节点对象以及状态,相等返回True,否则返回False |
| element_located_selection_state_to_be | 传入定位元祖以及状态,相等返回True,否则返回False |
| alert_is_present | 是否出现警告 |
11、前进和后退 forward() back()
平常使用浏览器时都有前进和后退功能, Selenium也可以完成这个操作,它使用back()方法后退,使用forward()方法前进。
from selenium import webdriver
import time
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.taobao.com/')
browser.get('https://www.baidu.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(3)
browser.forward()
browser.close()
说明:这里我们连续访问3个页面,然后调用back()方法回到第二个页面,接下来再调用forward()方法又可以前进到第三个页面。
12、Cookies
使用Selenium ,还可以方便地对Cookies 进行操作,例如获取、添加、删除Cookies等......
from selenium import webdriver
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.taobao.com/')
print(browser.get_cookies()) #获取Cookies
browser.add_cookie({'name':'pansy_nuist','domain':'www.taobao.com','value':'nuist'}) #增加Cookies
print(browser.get_cookies())
browser.delete_all_cookies() #删除Cookies
print(browser.get_cookies())
结果显示:
[{'secure': False, 'name': 'thw', 'httpOnly': False, 'value': 'cn', 'path': '/', 'expiry': 1578818757.298051, 'domain': '.taobao.com'}, ......, {'name': 'cookie2', 'secure': False, 'value': '157b9c5b5ebbd2240fb3a8eeb5d8007c', 'path': '/', 'httpOnly': True, 'domain': '.taobao.com'}]
[{'secure': False, 'name': 'thw', 'httpOnly': False, 'value': 'cn', 'path': '/', 'expiry': 1578818757.298051, 'domain': '.taobao.com'}, {'secure': True, 'name': 'pansy_nuist', 'httpOnly': False, 'value': 'nuist', 'path': '/', 'expiry': 2178002760, 'domain': 'www.taobao.com'}, ......., {'name': 'cookie2', 'secure': False, 'value': '157b9c5b5ebbd2240fb3a8eeb5d8007c', 'path': '/', 'httpOnly': True, 'domain': '.taobao.com'}]
[]
13、选项卡管理
在访问网页的时候,会开启一个个选项卡。在Selenium 中,我们也可以对选项卡进行操作。
from selenium import webdriver
import time
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
browser.get('https://www.baidu.com')
browser.execute_script('window.open()') #开启下一个选项卡
print(browser.window_handles) #['CDwindow-2B7ABC971623082D004F000001B1A73C', 'CDwindow-FC0C556915CF2E57AC1A13E407A2EF12']
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(3)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')
说明:首先访问了百度,然后调用了execute_script()方法,这里传入window.open()这个JavaScript语句新开启一个选项卡。接下来,我们想切换到该选项卡。这里调用window_handles属性获取当前开启的所有选项卡,返回的是选项卡的代号列表。要想切换选项卡,只需要调用switch_to_window()方法即可,其中参数是选项卡的代号。这里我们将第二个选项卡代号传人,即跳转到第二个选项卡,接下来在第二个选项卡下打开一个新页面,然后切换回第一个选项卡重新调用switch_to_window()方法,再执行其他操作即可。
14、异常处理
可以使用try except 语句来捕获各种异常。为了防止程序遇到异常而中断,我们需要捕获这些异常。
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException
browser = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Anaconda3\Scripts\chromedriver.exe')
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('NO ELEMENT')
finally:
browser.close()
说明:使用try except 来捕获各类异常。比如,我们对find_element_by_id()查找节点的方法捕获NoSuchElementException异常,这样一旦出现这样的错误,就进行异常处理,程序也不会中断了。
15、Chrome Headless模式 【无界面模式】
从Chrome59版本开始,已经开始支持Headless模式,也就是无界面模式,这样爬取的时候就不会弹出浏览器了。如果要使用此模式,请把Chrome升级到59版本及以上。
#启用Headless模式的方式如下:
chrome_options=webdriver.ChromeOptions()
chrome_options .add_argument('--headless')
browser=webdriver.Chrome(chrome_options=chrome_options)
ヾ(◍°∇°◍)ノ゙ヾ(◍°∇°◍)ノ゙ヾ(◍°∇°◍)ノ゙ヾ(◍°∇°◍)ノ゙完结撒花ヾ(◍°∇°◍)ノ゙ヾ(◍°∇°◍)ノ゙ヾ(◍°∇°◍)ノ゙ヾ(◍°∇°◍)ノ゙
现在,我们基本对Selenium 的常规用法有了大体的了解。使用Selenium,处理JavaScript 不再是难事。
selenium爬虫实例:18-使用Selenium爬取京东商品,链接:https://my.oschina.net/pansy0425/blog/3000645