五、Sharding-JDBC 垂直分库
1、简介
前面已经介绍过,垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。接下来看一下如何使用 Sharding-JDBC 实现垂直分库。
2、实现
2.1 创建数据库和表
/*
SQLyog Ultimate v12.08 (32 bit)
MySQL - 8.0.11 : Database - order_db
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`user_db` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `user_db`;
/*Table structure for table `t_user` */
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`user_id` bigint(20) NOT NULL COMMENT '用户id',
`username` varchar(20) NOT NULL COMMENT '用户名',
`user_type` char(1) DEFAULT NULL COMMENT '用户类型',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='用户表';
/*Data for the table `t_user` */
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
2.2 修改 application.properties
在原来的项目的基础上添加如下配置,如果没看之前章节请移步到 Sharding-JDBC 快速入门。
完整的 application.properties 如下:
server.port = 9095
server.servlet.context-path = /sharding-jdbc
spring.application.name = sharding-jdbc
spring.http.encoding.charset = utf-8
spring.http.encoding.enabled = true
spring.http.encoding.force = true
# 针对bean被重复定义,重复则覆盖
spring.main.allow-bean-definition-overriding = true
# 和数据库字段进行印射,最终成为驼峰命名
mybatis.configuration.map-underscore-to-canel-case = true
## Sharding-jdbc 分片规则配置
# 定义多个数据源
spring.shardingsphere.datasource.names = m0,m1,m2
# 数据库连接池
spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
# MySQL 8.0x (driver-class-name = com.mysql.cj.jdbc.Driver)
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
# MySQL 8.0x (url = jdbc:mysql://localhost:3306/weizhang2?useSSL=false&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&zeroDateTimeBehavior=CONVERT_TO_NULL&serverTimezone=Asia/Shanghai)
spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/user_db?useSSL=false&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = host
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db_1?useSSL=false&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = host
spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/order_db_2?useSSL=false&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = host
# 分库策略,以 user_id 为分片键,分片策略为 user_id % 2 + 1,user_id 为偶数操作 m1 数据源,某则操作 m2
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression = m$->{user_id % 2 + 1}
# 指定t_order表的数据分布情况配置数据节点
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m$->{1..2}.t_order_$->{1..2}
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes = m0.t_user
# 指定t_order表的主键生成策略为SNOWFLAKE(雪花算法,实现全局主键自增)
spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression = t_user
# 打开sql输出日志
spring.shardingsphere.props.sql.show = true
user_db 没有进行分库,所以不需要配置分库策略,不过需要配置数据结点;因为我们对 t_user 表没有分表,因此主键生成策略可配可不配;而分片策略也要配置
通过之前的学习,我们大致熟悉了分库分表的配置。
- (1)首先配数据源
- (2)然后看是否分库,分库了则配分库策略
- (3)接着是不管什么情况都要配置数据节点
- (4)查看是否需要配置主键生成策略
- (5)分片策略也要配置,防止后期需要分表
2.3 添加 mapper 接口
添加 userMapper 接口,代码如下:
package com.pky.shardingjdbc.mapper;
import com.alibaba.druid.sql.visitor.functions.Char;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Repository;
import java.math.BigDecimal;
import java.util.List;
import java.util.Map;
@Repository
public interface UserMapper {
/**
* 插入用户
* @param userId 用户
* @param username 用户名
* @param userType 用户类型
*/
@Insert("insert into t_user(user_id, username, user_type) values (#{userId}, #{username}, #{userType})")
void insert(@Param("userId") Long userId, @Param("username") String username, @Param("userType") Character userType);
/**
* 根据id查询用户
* @param userIds id集合
* @return
*/
@Select("")
List2.4 添加测试方法
package com.pky.shardingjdbc;
import com.pky.shardingjdbc.mapper.UserMapper;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJDBCApplication.class})
public class UserTest {
@Autowired
UserMapper userMapper;
@Test
public void testInsert() {
for(long i = 0; i < 20; i++) {
userMapper.insert(i, "姓名" + i , '1');
}
}
@Test
public void testSelectByUserIds() {
List userIds = new ArrayList<>();
userIds.add(1L);
userIds.add(11L);
List 2.5 测试结果
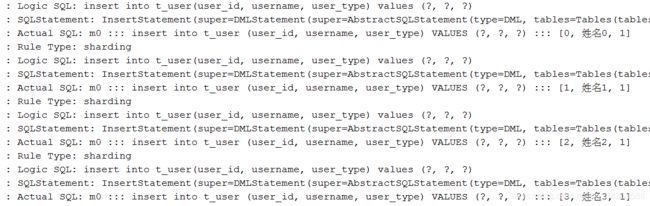
-
插入测试
-
查询测试

从结果上看,我们并没有对 user_db 数据库进行水平分库和对 t_user 表进行水平分表,因此插入和查询都指向了 m0 和 t_user。