python面试指南
1. a is b 和 a==b一样吗?
首先要了解对于Python对象而言,一般存在三个属性:type 类型, value 值 以及 地址id
a==b是一个比较运算符,用于比较两个对象的value(值)是否相同;相同则返回True 否则返回False
a is b是一个同一性运算符。用于比较两个对象的物理id。如果相同则返回True;否则返回False
综上:1 数值相同时 a == b 返回True,否则返回False。
2 数值相同时 a is b 未必返回True。
3.is 运算符比 == 效率高,在变量和None进行比较时,应该使用 is。
例如:
a = -5 # a, b 数值类型
b = -5
print(a is b)
print(id(a))
print(id(b))
a = -6
b = -6
print(a is b)
print(id(a))
print(id(b))
输出:
True
2009956240
2009956240
False
41870896
41870864
例如:
a = (1,2,3) # a, b 元组类型
b = (1,2,3)
print(a is b)
print(a==b)
print(id(a))
print(id(b))
输出:
False
True
42106456
42187368
复杂类型的都是false,list,dict,tuple这些,判断a is b时都是false,但是判断等于是true。
2.复制,深拷贝,浅拷贝
https://www.cnblogs.com/Jacck/p/7790049.html
复制:b=a以后,a怎么变,b都跟着变
a = [1, 2, 3, 4, [‘a’, ‘b’]]
b = a
a.append(5)
a[4].append(‘c’)
print('a = ', a)
print('b = ', b)
输出
a = [1, 2, 3, 4, [‘a’, ‘b’, ‘c’], 5]
b = [1, 2, 3, 4, [‘a’, ‘b’, ‘c’], 5]
浅拷贝:c = copy.copy(a)以后,c一部分跟着a变
import copy
a = [1, 2, 3, 4, [‘a’, ‘b’]]
c = copy.copy(a)
a.append(5)
a[4].append(‘c’)
print('a = ', a)
print('c = ', c)
输出
a = [1, 2, 3, 4, [‘a’, ‘b’, ‘c’], 5]
c = [1, 2, 3, 4, [‘a’, ‘b’, ‘c’]]
深拷贝:d = copy.deepcopy(a),d完全不跟着a变,还是原来的a
import copy
a = [1, 2, 3, 4, [‘a’, ‘b’]]
d = copy.deepcopy(a)
a.append(5)
a[4].append(‘c’)
print('a = ', a)
print('d = ', d)
指针id上也可以证明,=之后,两个变量指向同一个id,而copy和deepcopy不是相同的id
import copy
a = [x for x in range(5)]
b=a
print(id(a))
print(id(b))
print(’…’)
a = [x for x in range(5)]
b=copy.copy(a)
print(id(a))
print(id(b))
print(’…’)
a = [x for x in range(5)]
b=copy.deepcopy(a)
print(id(a))
print(id(b))
输出
42286728
42286728
…
42286664
42286536
…
42286728
42286664
3.什么是lambda函数?它有什么好处?python 使用 lambda 来创建匿名函数。
lambda 函数是一个可以接收任意多个参数并且返回单个表达式值的函数。 允许你快速定义单行的函数。lambda 函数不能包含命令,它们所包含的表达式不能超过一个。
def f(x):
return x*2f(3)
6g = lambda x: x*2
g(3)
6
max2=lambda x,y:y if x<=y else x
print(max2(8, 12))
transtime = lambda m: (m / 60, m % 60)
print(transtime(70))
f = [lambda x:x*i for i in range(4)]
print(f[1](1)) #(1)代表f函数传入的x=1;[1]表示里边用到的i=1,但这个1在此处不起作用。因为在每次循环中 lam函数都未绑定 i 的值,所以直到循环结束,i 的值为2,因此真正调用的时候 i 值保持不变(为2)
print(f[2](1))
print(f[1](5))
f = [lambda :i*i for i in range(4)]
print(f[0]())
print(f[1]())
print(f[2]())
输出
12
(1.1666666666666667, 10)
3
3
15
9
9
9
4.如何用Python输出一个Fibonacci数列?
a,b=0,1
while b<=100:
a,b=b,a+b
return a
5.解释一下python的and-or语法
a = “first”
b = “second”
print(1 and a or b) ##第一部分将在布尔环境中进行计算,它可以是任意Python表达式。如果计算为真,整个表达式的值为 a
print(0 and a or b) ## 如果第一部分计算为假,整个表达示的值为 b。
输出:
first
second
特殊情况(当a为假时直接输出b):
a = “”
b = “second”
print(1 and a or b)
print(0 and a or b)
输出
second
second
这里的空字符串被认为成false,1 and a 是false,假 or b输出b
封装成一个函数比较好
def choose(bool, a, b):
return (bool and [a] or [b])[0]
6.序列反转
for i in range(len(sequence)-1, -1, -1):
x = sequence[i]
7.Python是如何进行类型转换的?
序列操作:
| 操作 | 描述 |
|---|---|
| s + r | 序列连接 |
| s * n , n * s | s的 n 次拷贝,n为整数 |
| s % d | 字符串格式化(仅字符串) |
| s[i] | 索引 |
| s[i :j ] | 切片 |
| x in s , x not in s | 从属关系 |
| for x in s : | 迭代 |
| len(s) | 长度 |
| min(s) | 最小元素 |
| max(s) | 最大元素 |
| s[i ] = x | 为s[i]重新赋值 |
| s[i :j ] = r | 将列表片段重新赋值 |
| del s[i ] | 删除列表中一个元素 |
| del s[i :j ] | 删除列表中一个片段 |
数值操作:
| 操作 | 描述 |
|---|---|
| x << y | 左移 |
| x >> y | 右移 |
| x & y | 按位与 |
| x | y |
| x ^ y | 按位异或 (exclusive or) |
| ~x | 按位翻转 |
| x + y | 加 |
| x - y | 减 |
| x * y | 乘 |
| x / y | 常规除 |
| x // y | 地板除 |
| x ** y | 乘方 (xy ) |
| x % y | 取模 (x mod y ) |
| -x | 改变操作数的符号位 |
| +x | 什么也不做 |
| ~x | ~x=-(x+1) |
| abs(x ) | 绝对值 |
| divmod(x ,y ) | 返回 (int(x / y ), x % y ) |
| pow(x ,y [,modulo ]) | 返回 (x ** y ) x % modulo |
| round(x ,[n]) | 四舍五入,n为小数点位数 |
| x < y | 小于 |
| x > y | 大于 |
| x == y | 等于 |
| x != y | 不等于(与<>相同) |
| x >= y | 大于等于 |
| x <= y | 小于等于 |
8.Python里面如何实现tuple和list的转换?什么是tuple
iplist=1,5.6989,563,3.265,0.3596
l = tuple(iplist)
print (l)
t = list(l)
print(t)
输出:
(1, 5.6989, 563, 3.265, 0.3596)
[1, 5.6989, 563, 3.265, 0.3596]
9.请写出一段Python代码实现删除一个list里面的重复元素
l = [1,1,2,3,4,5,4]
print(list(set(l)))
d = {}
for x in mylist:
d[x] = 1
mylist = list(d.keys())
print(mylist)
输出
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
10.介绍一下except的用法和作用?
Python的捕捉异常可以使用try/except语句,每次错误都会抛出一个异常,所以每个程序的错误都被当作一个运行时错误。
try-finally 语句无论是否发生异常都将执行finally的代码。
例如:
try:
fh = open(“testfile”, “w”)
fh.write(“这是一个测试文件,用于测试异常!!”)
print(’‘写入’’)
except IOError:
print “Error: 没有找到文件或读取文件失败”
else:
print “内容写入文件成功”
fh.close()
正确执行时输出:
写入
内容写入文件成功
发生IOError错误时输出:
Error: 没有找到文件或读取文件失败
发生其他类型的错误时程序报错
除非改成以下这样,这样可以捕获所有异常,所有的错误类型都输出Error: 没有找到文件或读取文件失败
try:
fh = open(“testfile”, “w”)
fh.write(“这是一个测试文件,用于测试异常!!”)
print(’‘写入’’)
except:
print “Error: 没有找到文件或读取文件失败”
else:
print “内容写入文件成功”
fh.close()
11.触发异常:raise语句自己定义触发异常的类型。
class FooError(ValueError):
pass
def foo(s):
n = int(s)
if n==0:
raise FooError('invalid value: %s' % s) ##自定义错误时,要定义一个错误类
return 10 / n
foo('0')
12.说一下enumerate函数的用法
seasons = [‘Spring’, ‘Summer’, ‘Fall’, ‘Winter’]
list(enumerate(seasons))
[(0, ‘Spring’), (1, ‘Summer’), (2, ‘Fall’), (3, ‘Winter’)]list(enumerate(seasons, start=1))
[(1, ‘Spring’), (2, ‘Summer’), (3, ‘Fall’), (4, ‘Winter’)]
13.range函数的用法
range(stop)
range(start, stop[, step])
14.Python里面search()和match()的区别
match需要从头匹配才算;而search不需要从头
import re
print(re.match(“func”, “function”))
print(re.match(“tion”, “function”))
print(re.match(“func1”, “function”))
输出
<_sre.SRE_Match object; span=(0, 4), match=‘func’>
None
None
print(re.search(“tion”, “function”))
print(re.search(“tion1”, “function”))
输出
<_sre.SRE_Match object; span=(4, 8), match=‘tion’>
None
15. 列表和元祖有什么不同?
列表可变,元组不可变
ls=[1,2,3]
ls[1]=5
tuple=(1,2,3)
tuple[1]=5
报错
File “D:/deeplearning/CNN/chengxu/ti.py”, line 4, in
tuple[1]=5
TypeError: ‘tuple’ object does not support item assignment
16.解释 Python 中的三元表达式
[on true] if [expression]else [on false]
17.解释继承
18. 解释 Python 中的 help() 函数和 dir() 函数。
help() 函数返回帮助文档和参数说明:
dir() 函数返回对象中的所有成员 (任何类型):
19. 能否解释一下*args 和 **kwargs?
单个星号用来接受任意多个参数并将其放在一个元组中。
两个星号用来接受任意多个关键参数并将其放在一个元组中(即把该函数的参数转换为字典)。
为什么提这个问题?有时候,我们需要往函数中传入未知个数的参数或关键词参数。
def demo(*p):
print(p)
demo(1, 2, 3) ##不能给变量名字,只能给值。因为存成tuple
输出
(1, 2, 3)
def demo(**p):
for i in p.items():
print(i)
demo(a=1, b=2) ##必须给变量名字,因为存成字典
输出
(‘a’, 1)
(‘b’, 2)
20.解释 Python 中的 join() 和 split() 函数
join() 函数可以将指定的字符添加到多个字符串中,把每个字符串连接起来,连成一个。
split() 函数可以用指定的字符分割字符串
s='a bc dek dy j'
s1=s.split(' ')
print(s1)
str = "f"
seq = ("a", "b", "c")
print(str.join( seq ))
输出
[‘a’, ‘bc’, ‘dek’, ‘dy’, ‘j’]
afbfc
21.请解释 Python 中的闭包
函数的return是它内部定义的函数,这个内部函数引用了外部变量,那么内部函数就是一个闭包。
优点:我们可以修改外部的变量,闭包根据这个变量展现出不同的功能.
def add(x):
def adder(y):
return x + y
return adder
c = add(8) ##执行完这句c就是adder函数了,而且x=8
print(c)
print(c.__name__)
print(c(10))
输出
adder
18
22.下面这些是什么意思:@classmethod, @staticmethod, @property?
这些都是装饰器(decorator),增加函数的功能。
装饰器的本质就是一个闭包函数;
装饰器的功能就是在不改变原函数及原调用方式的前提下,对原函数的功能进行扩展。


@property的作用是增加返回函数值的功能
import math
class Circle:
def __init__(self,radius): #圆的半径radius
self.radius=radius
def area(self):
return math.pi * self.radius**2 #计算面积
def perimeter(self):
return 2*math.pi*self.radius #计算周长
c=Circle(10)
print(c.radius)
print(c.area) #可以向访问数据属性一样去访问area,会触发一个函数的执行,动态计算出一个值
print(c.perimeter) #同上
输出结果:
10
import math
class Circle:
def __init__(self,radius): #圆的半径radius
self.radius=radius
@property
def area(self):
return math.pi * self.radius**2 #计算面积
@property
def perimeter(self):
return 2*math.pi*self.radius #计算周长
c=Circle(10)
print(c.radius)
print(c.area) #可以向访问数据属性一样去访问area,会触发一个函数的执行,动态计算出一个值
print(c.perimeter) #同上
输出结果:
10
314.1592653589793
62.83185307179586
在类里边定义函数要用到self。除此之外还有两种常见的方法:静态方法和类方法,二者是为类量身定制的,但是实例非要使用,也不会报错。
@classmethod是类方法,不需要实例化,也不需要self参数,需要一个cls参数,可以用类名调用,也可以用对象来调用。
@staticmethod是静态方法,不需要实例化,不需要self和cls等参数,就跟使用普通的函数一样,只是封装在类中。
class Foo(object):
@classmethod
def cls_fun(cls):
return "hello world"
@staticmethod
def static_fun():
return "hello python"
foo = Foo()
print(Foo.cls_fun())
print(foo.cls_fun())
print(Foo.static_fun())
输出
hello world
hello world
hello python
23.print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="":
24.sys模块(只用过一个,记住一个就行了)
import sys
sys.path.append(“自定义模块路径”)
25.Python3 中有六个标准的数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Set(集合)
Dictionary(字典)
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合,使用大括号 { } 或者 set() 函数创建)。
不可变的数组可以通过+连接,通过del删除,其他的操作好像不可以。
字典中的键必须不可变,所以可以用数字,字符串或元组充当,而不能用列表。
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
集合:
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'};
print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
set('abracadabra')
print(a)
{'a', 'r', 'b', 'c', 'd'}
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用:tup1 = (50,)
26.python用del删除
27.说一下python的迭代器与生成器。节省大量空间,每次用的时候取一个,而不是一下全取出来浪费空间。
迭代器:包含iter()(用来创建迭代器) 方法和 next()(用来输出迭代器的下一个元素)方法的类称为迭代器
字符串,列表或元组对象都可用于创建迭代器:
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
print(it)
print (next(it)) # 输出迭代器的下一个元素
print (next(it))
输出:
1
2
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
输出:
1 2 3 4
判断一个变量是否为可迭代对象用isinstance([11,22,33],collections.Iterable)
判断一个东西是否为迭代器用isinstance(it,collections.Iterator)
import collections
print(isinstance([11,22,33],collections.Iterable)) ##输出True
it=iter([11,22,33])
print(isinstance(it,collections.Iterator)) ##输出True
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
以下实例使用 yield 实现斐波那契数列:
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
print(f)
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
输出:
0 1 1 2 3 5 8 13 21 34 55
简单的生成器:
generator_ex = (x*x for x in range(10))
for i in generator_ex:
print(i)
生成器表达式:print((x ** 3 for x in range(5))) 是
列表解析式:print([ x ** 3 for x in range(5)]) 是[0, 1, 8, 27, 64]
yield是一个类似return 的关键字,迭代一次遇到yield的时候就返回yield后面或者右面的值。而且下一次迭代的时候,从上一次迭代遇到的yield后面的代码开始执行
yield就是return返回的一个值,并且记住这个返回的位置。下一次迭代就从这个位置开始。
28.列表推导式,字典推导式,集合推导式
列表推导式:从序列创建列表。每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
vec = [2, 4, 6]
[[x, x**2] for x in vec] ##输出 [[2, 4], [4, 16], [6, 36]]
[3*x for x in vec if x > 3] ##输出 [12, 18]
[3*x for x in vec if x < 2] ##输出 []
vec1 = [2, 4, 6]
vec2 = [4, 3, -9]
[x*y for x in vec1 for y in vec2] ##输出[8, 6, -18, 16, 12, -36, 24, 18, -54]
[x+y for x in vec1 for y in vec2] ##输出[6, 5, -7, 8, 7, -5, 10, 9, -3]
[vec1[i]*vec2[i] for i in range(len(vec1))] ##输出[8, 12, -54]
f=[[0 for _ in range(5)] for _ in range(7)] #f里边包含7个list,这7个list中每个list里边包含5个0
字典推导式:
ma={'a':10,'b':20}
var={v:k for v,k in ma.items()}
集合推导式:
var={x**2 for x in [1,1,2]}
29.zip函数,把list组合在一起。
questions = [‘name’, ‘quest’, ‘favorite color’]
answers = [‘lancelot’, ‘the holy grail’, ‘blue’]
for q, a in zip(questions, answers):
… print(‘What is your {0}? It is {1}.’.format(q, a))
…
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
30.python中类的继承和多态。
class people:
# 定义基本属性
name = ''
age = 0
# 定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
# 定义构造方法
def __init__(self, n, a, w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" % (self.name, self.age))
# 单继承示例
class student(people): ###这里继承父类以后,下边就可以用people里边的函数了
grade = ''
def __init__(self, n, a, w, g):
# 调用父类的构函
people.__init__(self, n, a, w)
self.grade = g
people.speak(self) ##相当于把上边定义的这个speak函数又在这里定义了一遍
# 覆写父类的方法
def spe(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级" % (self.name, self.age, self.grade))
s = student('ken', 10, 60, 3)
s.speak()
s.spe()
执行以上程序输出结果为:
ken 说: 我 10 岁。
ken 说: 我 10 岁。
ken 说: 我 10 岁了,我在读 3 年级
当子类和父类都存在相同的方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run()。这就是多态。
class MiniOS(object):
"""MiniOS 操作系统类 """
def __init__(self, name):
self.name = name
self.apps = [] # 安装的应用程序名称列表
def __str__(self):
return "%s 安装的软件列表为 %s" % (self.name, str(self.apps))
def install_app(self, app):
# 判断是否已经安装了软件
if app.name in self.apps:
print("已经安装了 %s,无需再次安装" % app.name)
else:
app.install()
self.apps.append(app.name)
class App(object):
def __init__(self, name, version, desc):
self.name = name
self.version = version
self.desc = desc
def __str__(self):
return "%s 的当前版本是 %s - %s" % (self.name, self.version, self.desc)
def install(self):
print("将 %s [%s] 的执行程序复制到程序目录..." % (self.name, self.version))
class PyCharm(App):
pass
class Chrome(App):
#######这里实现多态
def install(self):
print("正在解压缩安装程序...")
super().install() ##super() 函数是用于调用父类(超类)的一个方法。
linux = MiniOS("Linux")
print(linux)
pycharm = PyCharm("PyCharm", "1.0", "python 开发的 IDE 环境") ##先进入app类里的__init__函数
chrome = Chrome("Chrome", "2.0", "谷歌浏览器") ##先进入app类里的__init__函数
linux.install_app(pycharm) ##先进入MiniOS类里的install_app函数,执行到app.install()语句时,因为此时的app是传入的上边定义的PyCharm对象。这个PyCharm继承了父类的install函数,所以这句话App类的install函数
linux.install_app(chrome) ##先进入MiniOS类里的install_app函数,执行到app.install()语句时,因为此时的app是传入的上边定义的Chrome对象。这个Chrome虽然继承了父类的install函数,但是自己里边有install函数,这时执行自己类里的install函数
linux.install_app(chrome)
print(linux)
31.python两个下划线开头的变量是什么变量
两个下划线开头的是类的私有变量,只能在该类里边使用。两个下划线开头的可以是一个函数,也可以是一个变量。
class Site:
def __init__(self, name, url):
self.name = name # public
self.__url = url #私有变量,只能在该类里边使用。
def who(self):
print('name : ', self.name)
print('url : ', self.__url)
def __foo(self): # 私有函数,只能在该类里边使用,在外边调用时报错。
......
def foo(self): # 公共方法
.....
self.__foo()
32.python中的exec函数
作用:动态执行python代码。exec函数将字符串作为代码执行。
例1
def exec_code():
LOC = """
def factorial(num):
fact=1
for i in range(1,num+1):
fact = fact*i
return fact
print(factorial(5))
""" ##LOC里边是一整串字符串
exec(LOC) ##把一整串字符串执行
exec_code()
执行以上代码输出结果为:
120
例2:
x = 10
expr = """
z = 30
sum = x + y + z #一大包代码
print(sum)
"""
def func():
y=20
exec(expr) ##expr里边是一整串字符串,exec执行这一串字符串
exec(expr,{'x':1,'y':2}) ##执行这一串字符串,并且传入参数x=1;y=2
exec(expr,{'x':1,'y':2},{'y':3,'z':4}) #30+1+3,传入x=1;y=3;z=4;但是后来有z=30;所以z最终等于30
func()
执行以上代码输出结果为:
60
33
34
33.以下代码的输出是什么,not,and,or优先级问题。
x = True
y = False
z = False
if not x or y:
print(1)
elif not x or not y and z: ##优先级顺序为 NOT、AND、OR。所有这句是False
print(2)
elif not x or y or not y and x:
print(3)
else:
print(4)
结果输出:3
34.python线程和进程。
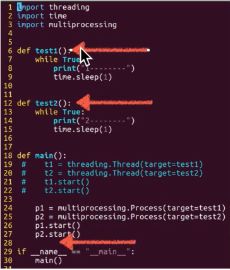
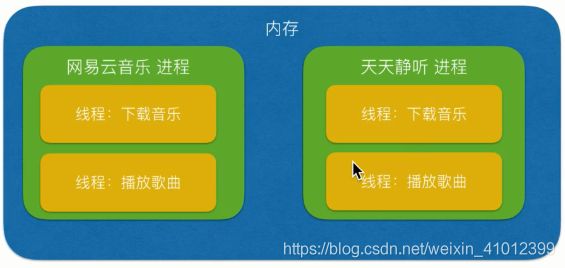
进程:双击运行一个程序就是进程,例如电脑上打开多个qq。多个资源,每个资源里有一个箭头。
线程:比较轻量级。例如一个qq打开多个界面。一个资源,这个资源里有多个箭头,同时运行。
代码—>进程,在进程里边可以实现线程(即一个进程里边的多个箭头)
多进程:
多线程:
多线程_方法一:
import threading
import time
def sing(n):
for i in range(n):
print('.....1........')
time.sleep(1)
def dance(n):
for i in range(n):
print('.....2.........')
time.sleep(1)
t1=threading.Thread(target=sing,args=(5,))
t2=threading.Thread(target=dance,args=(5,))
t1.start()
t2.start()
输出:
…1…
…2…
…1…
…2…
…1…
…2…
…1…
…2…
…1…
…2…
多线程_方法二(比方法一复杂,目前这样写不对,不知道正确的是什么):
import threading
import time
class MyThred(threading.Thread):
def sing(self,n):
for i in range(n):
print('....1....')
time.sleep(1)
def dance(self,n):
for i in range(n):
print('....2....')
time.sleep(1)
def run(self):
self.sing(5)
self.dance(5)
t=MyThred()
t.start()
输出:
…1…
…1…
…1…
…1…
…1…
…2…
…2…
…2…
…2…
…2…
查看线程数:
import threading
import time
def sing(n):
for i in range(n):
print('.....1........')
time.sleep(1)
def dance(n):
for i in range(n):
print('.....2.........')
time.sleep(1)
t1=threading.Thread(target=sing,args=(5,))
t2=threading.Thread(target=dance,args=(5,))
t1.start()
t2.start()
while True:
print(threading.enumerate())
time.sleep(1)
输出:
.....1........
.....2.........
[<_MainThread(MainThread, started 5332)>, , ]
[<_MainThread(MainThread, started 5332)>, , ]
.....1........
.....2.........
.....1........
[<_MainThread(MainThread, started 5332)>, , ]
.....2.........
.....2.........
.....1........
[<_MainThread(MainThread, started 5332)>, , ]
[<_MainThread(MainThread, started 5332)>, , ]
.....1........
.....2.........
[<_MainThread(MainThread, started 5332)>]
[<_MainThread(MainThread, started 5332)>]
[<_MainThread(MainThread, started 5332)>]
多进程(注:多进程必须在main函数中进行):
import multiprocessing
import time
def sing():
for i in range(5):
print('.....1........')
time.sleep(1)
def dance():
for i in range(5):
print('.....2.........')
time.sleep(1)
def main():
t1 = multiprocessing.Process(target=sing)
t2 = multiprocessing.Process(target=dance)
t1.start()
t2.start()
#t1.join() ###join()方法可以等待子进程(线程)结束后再继续往下运行,通常用于进程间的同步。
if __name__=='__main__':
main()
输出:
…1…
…2…
…1…
…2…
…1…
…2…
…1…
…2…
…1…
…2…
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。看起来A、B的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python对协程的支持是通过generator实现的。
在generator中,我们不但可以通过for循环来迭代,还可以不断调用next()函数获取由yield语句返回的下一个值。
但是Python的yield不但可以返回一个值,它还可以接收调用者发出的参数。
yield实现多任务(协程):
import time
def sing():
for i in range(3):
print('.....1........')
time.sleep(0.1)
yield
def dance():
for i in range(3):
print('.....2.........')
time.sleep(0.1)
yield
def main():
t1 = sing()
t2 = dance()
while True:
next(t1)
next(t2)
if __name__=='__main__':
main()
输出:
…1…
…2…
…1…
…2…
…1…
…2…
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。例如:;两个一起加起来保存,python是,拆开进行的,先加再保存啊什么的,有时候一个线程里边加完了还没保存就去另一个线程了,执行完另一个回来就执行保存,导致少加了一个值。
balance = balance + n
也分两步:
计算balance + n,存入临时变量中;
将临时变量的值赋给balance。
正常情况:
初始值 balance = 0
t1: x1 = balance + 5 # x1 = 0 + 5 = 5
t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0
t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8
t2: x2 = balance - 8 # x2 = 8 - 8 = 0
t2: balance = x2 # balance = 0
但是t1和t2是交替运行的,如果操作系统以下面的顺序执行t1、t2:
初始值 balance = 0
t1: x1 = balance + 5 # x1 = 0 + 5 = 5
t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8
t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0
t2: x2 = balance - 8 # x2 = 0 - 8 = -8
t2: balance = x2 # balance = -8
结果 balance = -8
这样是因为修改balance需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。两个线程同时一存一取,就可能导致余额不对,你肯定不希望你的银行存款莫名其妙地变成了负数,所以,我们必须确保一个线程在修改balance的时候,别的线程一定不能改。如果我们要确保balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,我们说,该线程因为获得了锁,因此其他线程不能同时执行change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过threading.Lock()来实现:
balance = 0
lock = threading.Lock()
def run_thread(n):
for i in range(100000):
# 先要获取锁:
lock.acquire()
try:
# 放心地改吧:
change_it(n)
finally:
# 改完了一定要释放锁:
lock.release()
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try…finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。

35.分类问题一般用交叉熵,而不是二次平方损失,交叉熵损失函数保证是凸函数,而且学习速度更快
使用交叉熵是因为逻辑回归在使用均方误差作为代价的情况下优化目标函数是非凸的,优化只能得到极小值,至于为何是非凸,我也没仔细研究过,很大可能是交叉熵代价的梯度约去了假设函数的梯度中的一个复杂项而使得优化目标函数变简单了。
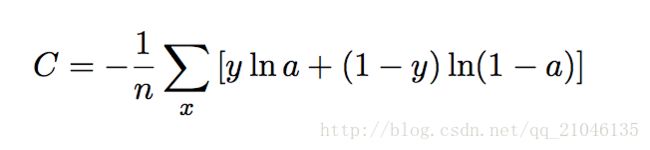
真实输出a与期望输出y
36.生成式模型:先学P(X,Y),再学P(Y|X)
判别式模型:直接学P(Y|X)
37.python中map()和reduce()函数的理解。
map()是一个高阶函数,函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’]
reduce()把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
from functools import reduce
def add(x, y):
return x + y
reduce(add, [1, 3, 5, 7, 9]) ##输出25
from functools import reduce
def fn(x, y):
return x * 10 + y
reduce(fn, [1, 3, 5, 7, 9]) ##输出13579
38.sorted()函数
sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower) ###输出['about', 'bob', 'Credit', 'Zoo']
sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) ###输出['Zoo', 'Credit', 'bob', 'about']
sorted([36, 5, -12, 9, -21], key=abs) ###输出[5, 9, -12, -21, 36]
39.python下划线开头,私有变量等
1、 _xx 以单下划线开头的表示的是protected类型的变量。即保护类型只能允许其本身与子类进行访问。若内部变量标示,如: 当使用“from M import”时,不会将以一个下划线开头的对象引入 。
2、 __xx 双下划线的表示的是私有类型的变量。只能允许这个类本身进行访问了,连子类也不可以用于命名一个类属性(类变量),调用时名字被改变(在类FooBar内部,__boo变成_FooBar__boo,如self._FooBar__boo)
3、 __xx__定义的是特列方法。用户控制的命名空间内的变量或是属性,如init , __import__或是file 。只有当文档有说明时使用,不要自己定义这类变量。 (就是说这些是python内部定义的变量名)
Python内置类属性
dict : 类的属性(包含一个字典,由类的数据属性组成)
doc :类的文档字符串
module: 类定义所在的模块(类的全名是’main.className’,如果类位于一个导入模块mymod中,那么className.module 等于 mymod)
bases : 类的所有父类构成元素(包含了一个由所有父类组成的元组)
40.python获取对象信息
使用type()函数判断对象类型;
对于class的继承关系来说,使用type()就很不方便。我们要判断class的类型,可以使用isinstance()函数。
如果要获得一个对象的所有属性和方法,可以使用dir()函数,它返回一个包含字符串的list。
print(type(123))
import types
def fn():
pass
print(type(fn)==types.FunctionType)
print(type(abs)==types.BuiltinFunctionType)
class Animal(object):
def run(self):
print('Animal is running...')
class Dog(Animal):
pass
a = Animal()
b = Dog()
print(isinstance(b, Animal))
print(isinstance(b, Dog))
print(dir('abc'))
输出:
True
True
True
True
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',......]
41.python类中特殊函数
python中__init__()、new()、call()、del()几个魔法方法的用法
https://www.cnblogs.com/zanjiahaoge666/p/7490824.html
如果要把一个类的实例变成 str,就需要实现特殊方法__str__()。
如果类把某个属性定义为序列,可以使用__getitem__()输出序列属性中的某个元素.
任何类,只需要定义一个__call__()方法,就可以直接对实例进行调用。
class Student(object):
def __init__(self, name):
self.name = name
print(Student('Michael'))
class Student(object):
def __init__(self, name):
self.name = name
def __str__(self):
return 'Student object (name: %s)' % self.name
print(Student('Michael'))
<main.Student object at 0x000000000285EC18>
Student object (name: Michael)
class Fib(object):
def __getitem__(self, n):
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
f = Fib()
print(f[0])
print(f[5])
1
8
class Student(object):
def __init__(self, name):
self.name = name
def __call__(self):
print('My name is %s.' % self.name)
s = Student('Michael')
s()
My name is Michael.
42.python调试debug的方法
print():直接打印结果,看哪里错了。assert A,B,表达式A应该是True,否则后面的代码肯定会出错。如果断言失败,assert语句本身就会抛出AssertionError
断言(assert):
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
foo('0')
Traceback (most recent call last):
File “D:/deeplearning/CNN/chengxu/ti.py”, line 6, in
foo(‘0’)
File “D:/deeplearning/CNN/chengxu/ti.py”, line 3, in foo
assert n != 0, ‘n is zero!’
AssertionError: n is zero!
43.python分布式进程(把程序分布到多台机器上)
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封装很好,不必了解网络通信的细节,可以很容易地编写分布式多进程程序。
举个例子:如果我们已经有一个通过Queue通信的多进程程序在同一台机器上运行,现在,由于处理任务的进程任务繁重,希望把发送任务的进程和处理任务的进程分布到两台机器上。怎么用分布式进程实现?
43.如何获取当前路径
import os
print(os.path.abspath(’.’))
如何获取当前模块的文件名
可以通过特殊变量__file__获取:
print(file)
如何获取命令行参数
可以通过sys模块的argv获取:
import sys
print(sys.argv)
如何获取当前Python命令的可执行文件路径
sys模块的executable变量就是Python命令可执行文件的路径:
import sys
print(sys.executable)
44.Python中的各种锁
一、全局解释器锁(GIL)
1、什么是全局解释器锁
每个CPU在同一时间只能执行一个线程,那么其他的线程就必须等待该线程的全局解释器。
全局解释器锁GIL 同一进程中的线程同一时间只能有一个拿到锁,可以运行, 其他的线程需要等待
1)、避免了大量的加锁解锁的好处
2)、使数据更加安全,解决多线程间的数据完整性和状态同步
3、全局解释器的缺点
多核处理器退化成单核处理器,只能并发不能并行。
4、GIL的作用:
多线程情况下必须存在资源的竞争,GIL是为了保证在解释器级别的线程唯一使用共享资源(cpu)。
1、什么是同步锁?
同一时刻的一个进程下的一个线程只能使用一个cpu,要确保这个线程下的程序在一段时间内被cpu执,那么就要用到同步锁。
1、什么是死锁?
指两个或两个以上的线程或进程在执行程序的过程中,因争夺资源或者程序推进顺序不当而相互等待的一个现象。