重磅 | 京东云区块链数据服务(BDS)正式开源!


作者 | 京东云BDS团队
区块链由很多区块按时间顺序串联起来构成的,在每个区块中存储交易、账号等相关信息。每个区块就像一本纸账本,上面记录了很多人每天的流水账。如果我们想查看最近一年有多少笔大额支出,那我们需要将最近一年的所有账本搬出,一本一本从头到尾进行翻看,找出相应的记录。也可以说每个区块就像一本纸质书,如果我们想从一堆纸质书中按某些关键字进行查找,除了从头到尾进行翻看之外,就别无它法了。区块链上数据都是离散化的数据,需要更加有效的数据组织方式以便于做进一步的查询与分析。
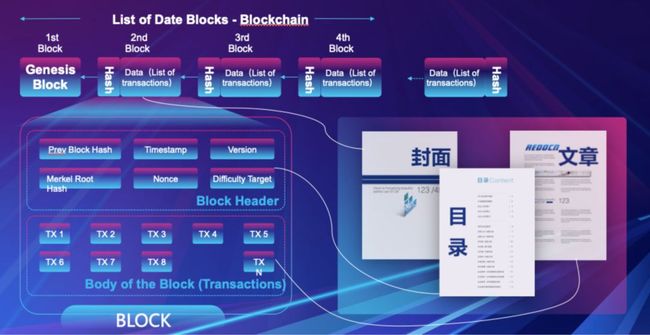
随着区块链技术的火爆,整个行业可谓是百家争鸣,有诸如BTC、ETH、XRP等耳熟能详的公有链项目,也有Fabric、Enterprise Ethereum Alliance、Corda R3等众所周知的联盟链项目,当然还有一些私有链项目。不管是公有链也好,联盟链、私有链也罢,每个链都是一个一个独立的信息孤岛,它们在技术上各有特色,在底层数据模型上也有很多相同之处。每个区块链项目就像一个一个手机App,我们可以统计分析出每个项目用户总量、日活、月活、留存、使用率、用户余额、平均交易金额等通用指标。
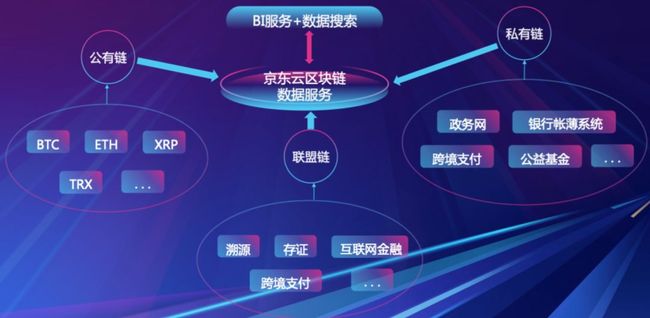
如何将多个区块链项目的信息孤岛连接起来,将无序、离散的区块数据整合成有序、可方便查询的关系型数据,将链上透明、共识、可信的数据和信息聚合在一起,提供分析、建模服务,赋能产业互联网发展,是区块链技术产业价值的重要体现。
当下,京东云区块链数据服务正在打造一个行业标准的区块链的BI+数据搜索服务,但是区块链项目的底层区块存储结构各不相同,需要对不同的项目的数据进行解析与整理,基于此,京东云开源了区块链数据服务(BDS),以望让更多的开发者与社区可以参与其中,接入更多公有链、联盟链、私有链等区块链项目。区块链数据服务将以区块链数据搜索引擎形式聚合所有区块链相关的内容,最大化区块链上可信数据价值,方便社区能在BDS上进行区块链数据的一站式查询。
GitHub 地址:https://github.com/jdcloud-bds/。

BDS 架构图
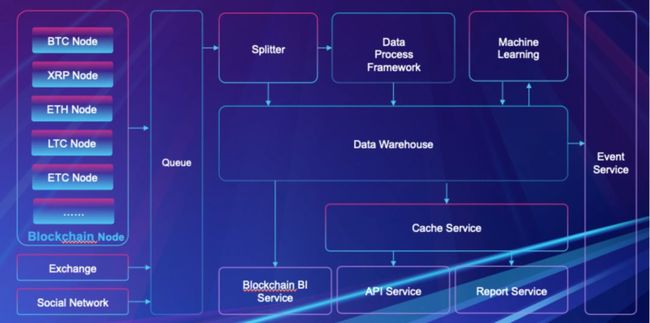
Blockchain Node:改造后的全节点服务,可将新块数据同步到 Queue 中;
Exchange:交易所上区块链相关数据;
Social Network:社交媒体上区块链相关数据;
Queue:消息队列服务;
Splitter:负责从 Queue 读取区块链数据,并将数据结果写入到 Data Warehouse 中;
Data Process Framework:实时数据分析模块,会进行一些实时数据指标计算,并将计算结果写入到 Data Warehouse 中;
Machine Learning:机器学习模块,会针对区块链地址信息通过机器学习技术进行训练,分析,并将分析结果写入到 Data Warehouse 中;
Data Warehouse:数据仓库服务,负责结构化存储区块链相关数据;
Cache Service:数据缓存服务,存储一些热数据,提高响应速度;
Event Service:事件订阅服务,支持针对特殊的事件进行订阅设置,发送邮件或短信;
Blockchain BI Service:数据可视化服务;
API Service:API 接口服务,支持通过 API 方式获取数据;
Report Service:数据报告服务,自动生成数据报表;

BDS 的开源计划
目前在开源项目组织 https://github.com/jdcloud-bds/ 中, 京东云BDS团队先后开源了Blochain Node 和 Splitter 两个服务模块, Blochain Node模块优先将BTC Node代码开源了出来,此后,京东云BDS团队表示,“还会不断开源其他的全节点服务,预计在 2019 年 Q3 季度会陆续将:ETH,XRP,ETC,LTC 等 20+ 条主流公有链开源出来。”
当然,除了开源 Blochain Node 和 Splitter 两个服务模块之外,其他的服务模块也将会陆续开源出来。不过当前仅是基于 Blochain Node 和 Splitter 两个服务模块,也能搭建出类似京东云区块链数据服务的效果。
通过上面的系统架构图可以发现,Blochain Node 和 Splitter 两个是整套服务的核心模块,其他模块都是基于这两个模块来设计的,所以开源了这两个核心模块,区块链数据库服务的基本架子就已经存在了,剩下的就是锦上添花的事情了。

本地搭建
接下来,让我们来一起看看,如果在本地搭建一套简易环境,达到类似京东云区块链数据服务的效果。
部署方式
confluent and Kafka - Queue
PostgreSQL - Data Warehouse
BTC Node
BDS(Splitter)
Grafana - Blockchain BI Service
安装 confluent 和 kafka
confluent 是一个 proxy 服务,提供了 restful 接口供外部调用,并将结果写入到 kafka 中。
安装 kafka
参考 kafka 官网文档进行搭建,运行 kafka 服务的时候需要修改下其配置文件:
message.max.bytes=1048576000
安装 confluent
参考 confluent 官网文档进行搭建,下载压缩包文件并解压运行 Confluent REST Proxy 服务,但是在运行之前需要修改下其配置文件:
max.request.size = 1048576000
buffer.memory = 1048576000
send.buffer.bytes = 1048576000
运行数据库服务
数据库这块其实可以不用自己本地搭建,其实可以直接使用云数据库服务,如京东云云数据库 RDS 服务。
当数据库服务运行起来之后,你需要手动创建一个库名,这个库名之后在运行 BDS(Splitter)服务的时候会用到。
安装 BTC 全节点
BTC 运行环境初始化,参见 build-unix
环境初始化好后,开始进行源码的编译、运行。
编译源码
1 ./autogen.sh2 ./configure3 make4 make install
2 ./configure
3 make
4 make install
运行 BTC 全节点
消息队列这里采用了 Kafka
1 ./usr/local/bin/bitcoind -kafka -kafkaproxyhost=[kafka 代理的ip地址] -kafkaproxyport=[kafka 代理的访问端口,默认是 8082] -kafkatopic=btc -datadir=[数据目录]当运行了 BTC 全节点,你可以发现在 Kafka 服务中你收到了一些数据,这就是区块链全节点的新块数据。
安装 BDS(Splitter)服务
BDS(Splitter) 运行环境初始化,需要安装 go 的运行环境,参见 go install
环境初始化好后,开始进行源码的编译、运行。
运行 BDS(Splitter)服务
设置项目的路径 $GOPATH/src/github.com/jdcloud-bds/bds/;
执行 go build -v github.com/jdcloud-bds/bds/cmd/bds-splitter 编译项目;
根据 /config/splitter_example.conf 配置模板新建一个配置文件splitter.conf,修改 splitter.conf 的内容,按提示设置对应的配置内容项,包括但不限于 btc 全节点信息,kafka 相关信息等;
执行 ./bds-splitter -c splitter.conf 运行 BDS(Splitter)服务;
当 BDS(Splitter)跑起来之后,你会发现在你的 PostgreSQL 数据库服务之前新建的库名下新建了一些表,过了一会,会发现这些表都有不同程度的新数据插入,这些数据就是 BDS(Splitter)服务从消息队列 Kafka 中消费的全节点的新块数据,进行解析之后插入的。
这样就完成了从非结构的区块链数据到结构化的数据转换,只需要整套服务一直运行着,那么在 PostgreSQL 数据库服务就实时存储着 BTC 全节点的所有数据信息。
安装 Garafna
如果要查询 PostgreSQL 数据库中的数据必须登录数据库服务,执行 SQL 命令来查询,不够直观。
所有推荐可以安装 Garafna 服务,安装教程参考 Garafna 官网 文档进行搭建。
通过 Garafna 服务就可以预置好查询 PostgreSQL 的 SQL 语句,实时查看你需要的数据结果,并以图表的形式来展现,更加形象,直观。

总结
一个新的区块链项目对接区块链数据服务开发只有两步:
修改相应对的全节点服务,能够将区块数据写入到消息队列。
从消息队列中取出相应的数据写入到数据仓库。
【End】


热 文 推 荐
☞北邮博导孙松林:5G 新物种开启新时代
☞Android 的替代品有哪些?
☞首批 8 款 5G 手机获 3C 认证;iPhone6 系列停产;Android Q Beta 5 发布 | 极客头条
☞《长安十二时辰》科技梗揭秘!唐朝就能看到 5G 踪影?
☞天才程序员: "开发 CryptoKitties 难不难? 只需掌握这3点..."
☞屡试不爽的互联网架构三大马车!
☞教你如何用Python实现文本摘要模型(附教程)
☞什么限制了GNN的能力?首篇探究GNN普适性与局限性的论文出炉!
☞中国第一程序员,微软得不到他就要毁了他!
 点击阅读原文,查看京东云区块链数据服务(BDS)。
点击阅读原文,查看京东云区块链数据服务(BDS)。
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢