实战篇 | 22 C++ 高性能计算—运算加速
小知识:如何取存在数组中的元素指针
怎么样处理需要放在一个容器里放在元素的指针,那个指针该怎么取出来?
我们先来看一段代码

咋看起来没什么问题,可是当程序运行之后,你会发现输出来的东西完全不是你想用的,为什么
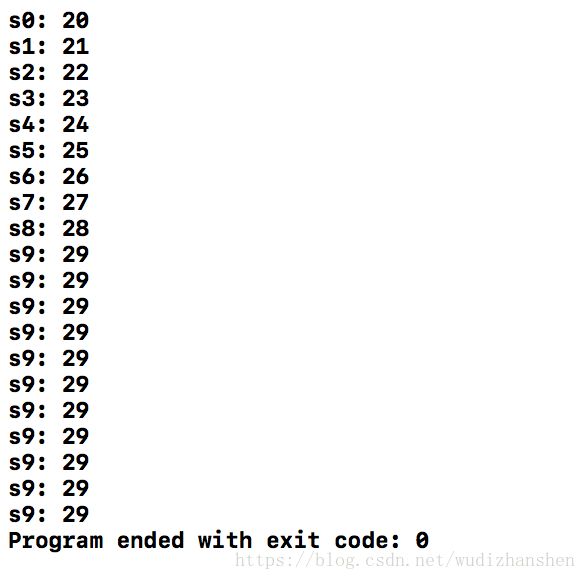
在上面这个for循环中,我创建了一个局部变量student,然后我把这个student push到一个vector里,这其实是一次拷贝。然后我把这个指针的地址存到另一个vector studentPointer里面。
可是当这个循环结束,局部变量student就会被释放,所以当我们用指针访问这个地址的时候,它就是野指针,输出的内容是不确定的,因为我们不知道这块内存被如何利用。
所以,其实我们是没有办法实现保存局部变量的指针的,是不能这样做的。
那我们的目的是把每一个元素的数组的指针保存到另外一个数组里面去,我怎么做呢?


可是打印出来并不是我们想要的内容,这里面有一个坑,
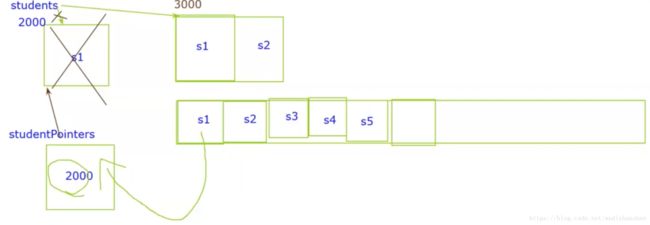
因为vector他是自动伸缩的,当我们向students里面存第一个元素的时候,它的内容是s1,地址是2000,所以我把2000这个地址存到studentsPointer里面,这是没有问题的。
可是当我在存第二个元素的时候,students发现空间不够了,所以他会再找一块能存两个元素的内存,把我们这两个元素放进去,把原来的那块内存删除,可是我们studentPointers里面还是存的那块元素的地址呀,于是就会出现野指针,找不到真正的元素。
那么如何解决这个问题呢,申请一块空间足够的内存,这样,vector就不会寻找新的内存了。

此时打印的结果是正确的。

完整代码示例:
#include 并行编程
为什么多个线程可以让程序的性能得到提升
现在的CPU都是多核的,每个核都是可以独立执行代码的。这样我就可以在不同的核同时执行代码,就是所谓的并行。
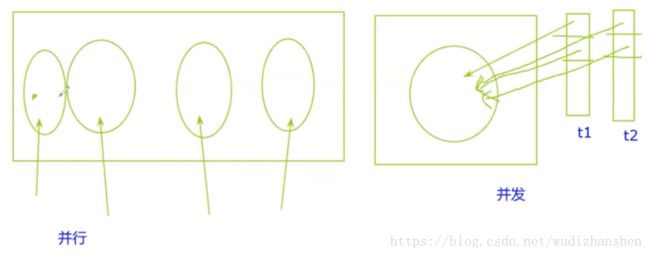
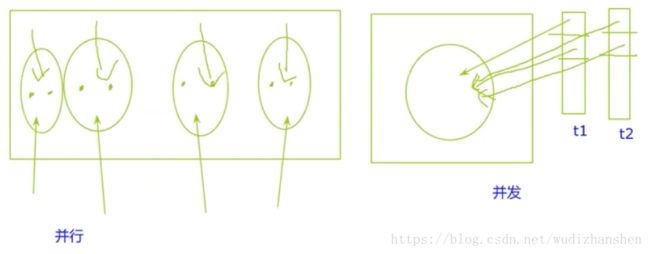
并发与并行
很早以前CPU是单核的,他也支持多线程、多进程这个概念,它怎么做呢?比如有两个线程t1,t2.它先执行t1线程的一部分,再执行t2线程的一部分,然后再执行t1的一部分,再执行t2的一部分,如此交替往复,直到执行完毕。所以那时多线程是一个基于时间片的一个轮转的过程。这个轮转的过程就是所谓的并发。并不是真正的同时执行,只不过说在我们肉眼看起来这两个线程好像是同时执行的,只不过是因为轮换速度比较快,比如一个任务执行100毫秒我就跳另一个任务了。在我们肉眼看来我们其实看不出这两个任务它其实是在交替进行,但这只是欺骗我们的眼睛。在单核的情况下,如果两个线程都用来做计算的话,它其实得不到什么性能提升。但在多核的情况下,每个核都可以同时独立执行不同指令。我有四核的情况下,我去执行我的代码,我就可以放四个线程。四个核每个核执行一个线程,这样执行完之后我就可以达到一个线程真正的并行执行。
超线程的概念
还有个概念是超线程, 它可以达到什么效果呢,一个核里面甚至可以开两个独立的硬线程,这两个独立的硬线程也可以看成是独立执行的,这样我就可以在我的计算机里面创建出更多的线程,比如你是四核八线程的处理器,那我就可以在我的电脑里面去开八个线程,让八个线程同时执行,这样就可以加快我们计算速度。
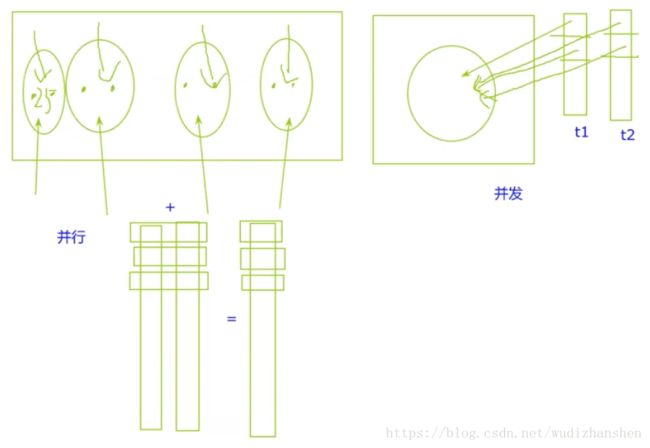
计算思路:Map/Reduce
这样计算往往有一种思路是Map/Reduce,这是一种计算模型。它先把数据切割,在每个核里面单独运算。运算完之后,再把它做一个总的合计。一会我们会演示一下这个过程是怎么回事,它这样的优点是我把数据切割在不同的处理器执行,以前我可能在同一个处理器里面去处理100条数据,现在我用Map/Reduce的思想先把数据切成4份,每一份25条数据,每个核只处理25条数据就行了。假定我每个核的性能是一样的,那么我的处理时间就可以降到原来的四分之一。这样子就可以真实的提高我的运算速度。
线程同步
存在一个问题,有时候我们没办法保证我们的数据是完全不相交的,一个线程计算完之后需要等待另外一个线程,这个时候,我们就需要去做一个线程同步。这个线程同步的具体方案,就是互斥锁,信号亮等,这些方案的目的就是让你一个线程可以去等待另外一个线程。它可能要等待另外一个线程完成什么事情,我才能继续向下跑。这其实就是一个线程同步的过程。
编程实践
如何用并行编程去实际解决问题。
正常的加法运算
#include
#include
#include
int main(int argc, const char * argv[]) {
std::vector<int> v1 = {1, 2, 3, 4, 5};
std::vector<int> v2 = {10, 11, 12, 13 ,14};
std::vector<int> v3(v1.size());
size_t count = v1.size();
for (int i = 0; i != count; ++ i) {
int a = v1[i];
int b = v2[i];
v3[i] = a + b;
}
for (int v : v3) {
std::cout << v << " ";
}
std::cout << std::endl;
return 0;
}
// Prints
11 13 15 17 19
Program ended with exit code: 0以上是正常的思路,但是由于v1、v2每个元素加法是互不相关的,独立计算的,所以我们可以同时启用多个线程来帮我们处理加法这件事情。
#include // 引入shared_ptr,智能指针
/**
单个线程计算和的函数
@param src1 输入数据的起始指针
@param src2 输入数据的起始指针
@param dst 计算完和之后的目标指针
@param count 一次计算多少个数
*/
void ThreadSumMain(int* src1, int* src2, int* dst, size_t count) {
for (int i = 0; i != count; ++ i) {
int a = src1[i];
int b = src2[i];
dst[i] = a + b;
}
};
int main(int argc, const char * argv[]) {
std::vector<int> v1 = {1, 2, 3, 4, 5};
std::vector<int> v2 = {10, 11, 12, 13 ,14};
std::vector<int> v3(v1.size());
std::vector<std::shared_ptr<std::thread>> threads;
size_t count = v1.size();
for (int i = 0; i != count; i++) {
std::shared_ptr<std::thread> addr (new std::thread(ThreadSumMain,v1.data() + i, v2.data() + i, v3.data() + i, 1));
threads.push_back(addr);
}
// 遍历线程,等待五个线程结束,再执行下面的语句
for (std::shared_ptr<std::thread> adder : threads) {
adder->join();
}
// 求两个数组里每个元素之和
for (int v : v3) {
std::cout << v << " ";
}
std::cout << std::endl;
// 求所有元素之和
int sum = 0;
for (int v : v3) {
sum += v;
}
std::cout << sum << std::endl;
return 0;
}这里我们开辟了五个线程,来分别计算两个数组的每个元素之和,最后求总和。
这就是多线程计算的一个基本思路,它是通过切割数据,一起计算来提高我的速度,说白了它是更充分的利用CPU,那如果说你一个程序已经占了100%的CPU,你再开多个线程也是没有什么用处的,有时候反而会拖慢我们的计算。
注意:
在Windows底下,如果你是用一个核去做运算,就是你只用主线程去做运算,一般来说程序只能占到一个核或一个硬线程,如果你是四核机器,那么你的CPU的单程序,如果你没有开启多个线程的话,那么你的CPU最多只能占到四分之一,25%。只有你在开启多线程的情况下,它才能够超过程序规定的CPU负荷的瓶颈,更充分的去利用CPU。
OpenMP
刚刚我们的这个过程,假如我们有100万条数据,把们把它切割成10份,再开辟10个线程分别计算,其实是非常麻烦的,而它看起来是有套路的,我们有什么办法可以让编译器自动把一个串行的for循环这种代码转成一个多线程的并行代码呢, 这个时候就有一个工具,这个工具叫OpenMP (Open Multi-Processing)即共享存储并行计算。
- 由OpenMP Architecture Review Board 牵头提出的
- 用于共享内存并行系统的多处理器程序设计
- 提供了对并行算法的高层的抽象描述
- 程序员通过在源代码中加入专用的pragma来指明自己的意图
- 编译器可以自动将程序进行并行化
适用于电脑里面有多个CPU,或多个核,我就可以让你的代码从串行计算自动转换为并行计算。它和我们用的线程不一样,它提供了对并行算法的高层抽象描述,一会看一下代码就知道了什么是高层抽象描述。
代码实现OpenMP
- 包含头文件
omp.h

- 使用
pragma编译指示来做,写一个omp,表示他是一个omp的预处理指令;
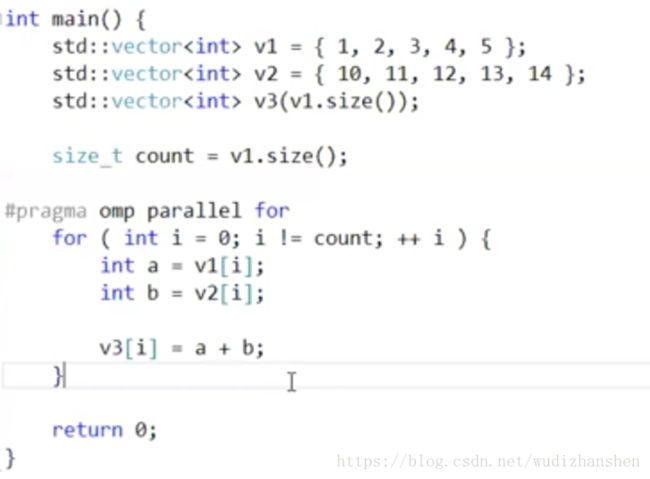
parallel:表示并行,它会自动讲后面的for语句块并行化;怎么并行化呢,我再指定一个并行化方法for,自动并行的循环;这样子它就会把我串行的循环变成一个并行的循环。
也相当于pragma编译指示的这句话套在我的for上,让我简单的串行的for变成并行的for。
OpenMP实现思路
那么omp怎么实现呢,它是一个简单的编译器+一个简单的运行库。它的实现思路和我们上面是一样的,它看你循环里面有五次,他就创立五个独立的线程。让每个线程去独立执行里面的运算。omp它的实质只是把我们手工切割线程这种过程给自动化了。但这种自动化方案它的优点是它会自动根据你的CPU和你的比如循环次数、里面计算的量自动计算我要产生多少个线程。比如你有1万条数据,在我的八核电脑上开发。那我就开八个线程,这样如果我把我的程序放在另外一台电脑上,那台电脑是4个线程。如果我在那个四台电脑上开八个线程的话就会把速度拖慢。那omp它有个效果就是可以自动识别你的CPU的核数。你到底是多少个并发,自动调节说创建多少个线程。当然,你也有一些方式去操纵它,比如限制最大线程数量。限制缓冲区大小,这些都是可以去限制的。
我们讲了两种并行编程的方式,一个是怎么用线程去实现一个并行编程。第二个是怎么通过OpenMP这种手段把我们的并行编程自动化。到这里为止是我们用CPU来做并行编程的一个部分。我教大家怎么用CPU来做并行编程主要是考量这两块内容。其他的并行编程的方法和共享数据的方法,大家感兴趣可以自己去查。我现在主要说在程序内部处理的方法主要是这两种。OpenMP只是把我们手动的过程变为自动的过程而已,其实没有什么深奥的东西。
注意:

如果你是Linux系统,你用的是GCC的话,如果你想去编译一个带OpenMP的程序,你需要自己去加一个编译参数-gomp。使得我的编译器支持OpenMP这个特性。OpenMP的计算之间不可互相依赖:
如果刚刚上面那个for里面的东西不能并行呢,不如我第二个循环的 i是依赖于第一个循环的计算结果的。
这种情况下,OpenMP不能帮你去做并行化的。所以你用OpenMP之前呢,要好好规划一下自己的计算过程。要尽量把你的计算过程划分为几个完全独立的计算过程。至于怎么取变换,需要你自己去做一个变换。它不是一个非常智能的自动化的并行化过程,它只是帮我们简化一些手动操作而已。
OpenCL

刚刚这两个方法的思路是一样的,尽量把我的CPU的核同时用起来。让我的代码可以同时在CPU上执行,把CPU吃满。但是呢,我的CPU的处理能力是有极限的。比如你是八核CPU,那你的极限是最多开八个线程。我如果再多线程的话,那我的性能可能也提不了,可能被你多加的线程拖慢。
那么,我们有什么办法在把我们的CPU吃满的情况下,继续提升我们的计算能力呢。
异构计算
这个时候就出现了一种概念,这种概念叫异构计算。
如果你从硬件的角度来看我们的计算机,你就会发现我们的计算机可以运算的部位不只用CPU。比如我们现在最流行的可以独立运算的部件就是我们的显卡GPU,比如你是做硬件的,你自己去独立设计一个电路板,为提升性能你可能还会在板上放一些独立的处理器,比如mips处理器,ARM处理器。现在非常流行的是用fpga去完成一些特定的操作。
一个以计算机为核心的硬件系统里面,它可以有相当多的独立运算的这些组件。那我如果可以根据我的实际需求去设计这个电路,或这说可以把现有的这些可以独立运算的部件都同时利用起来。这种思路就是异构计算。所谓异构运算就是用不同的硬件都用来完成我们同一个目标,完成最后的计算。只不过我们为了节约成本或提高速度,我们会使用不同的硬件。
异构运算的工具
为了做这个异构运算呢,我们就需要有一些工具来帮助我们去做它。因为我们直接写出来的代码它肯定在CPU上跑。那如果我们想用其他部件的情况下呢,我们就必须使用开发包或这其他接口来供我们使用。比如说我们现在最主要的除CPU之外的运算部件就是我们的GPU;无论是游戏图形渲染也好,设计软件渲染也好,还是说我们的机器学习也好。他们很多时候都会非常依赖GPU,为什么GPU可以提升那么的性能呢,这个我在后面讲英伟达Nvidia的时候再去讲一下。
现在先讲一下,如果想做异构运算,我们用什么方案。现在最通用的方案就是OpenCL(全称Open Computing Language,开放运算语言),它是一个开放和免费的标准,就是你无论是CPU或GPU的厂商,你都可以实现OpenCL,它只要保证你不同的处理器在处理OpenCL代码的时候都能正常执行就好了。OpenCL它使用C语言做了一个改版,加一些关键字,做一些限制,基础是一个C语言。它同时支持使用CPU或GPU,它可以在CPU上跑,也可以在GPU上跑,它也支持在其他任何设备上跑。只要你去支持它这种编程的模式和方法就可以。
OpenCL的基本思路
它的基本运算方法是一种基于Cell的架构。也就是说它把运算分成一个又一个的网格 ,每一个运算网格我都认为他们是一个可以独立运算的单位。我就可以把我的运算任意挑选几个,比如挑选十个cell来帮我们进行运算处理。它会把你所有的计算单元抽象成一个又一个的单元格,每个单元格都视为一个可以独立运算的单位,然后你再把你的cell放到这些任务里进行运算。
它的内存是独立的,这种架构每一个设备都有自己的一块存储空间,比如CPU直接接内存,而GPU有自己的显存。同样呢,他们之间有一种简单的数据交换方式。所以他们的一个基本思想就是说,我就可以把我的运算拆成几个部分,不同的支持OpenCL的组件拿出几个cell去做一个并行的计算。计算完之后,我再通过共享内存的方式把我的数据传到一个地方去做一个汇总。这是OpenCL的基本思路。
但是,说实话,除非我们去做Android上的一些特殊的加速,否则其实我们现在OpenCL其实用的非常少。
为什么?
OpenCL虽然看起来很漂亮,它是一个通用的标准,但由于它过于通用了,实际上在我的那些具体的硬件上的性能其实并不是特别好。至少我们后面去介绍的东西在实际使用过程中比OpenCL好上非常多。所以,OpenCL虽然是一个通用标准,它的应用场景并没有它刚出来的时候想想的那么广。
最主要的原因是英伟达它提出了一个自己的计算的框架,它也提出了一个工具包,这个工具包就是CUDA。
CUDA
- Compute Unified Device Architecture
- NVIDIA提出
- 支持C/C++/Fortran
- 性能优异
- 更多的库
cuBLAS
cuFFT
cuRAND
cuSPARSE
cuDNN
CUDA把对自己最好的优化全放在自己私有的工具包cuda toolkit里。openCL这种通用的东西相对来说就显得有点鸡肋。
什么是CUDA
它是由Nvida(英伟达)提出,实现这种架构也是英伟达。现在无论是游戏卡,还是计算卡,机器学习的计算卡,基本都已经完全被英伟达给垄断了。因为它提供的CUDA性能好,它提供了一个CUDA的工具包cuda toolkit。 这个工具包支持C/C++ Fortran.基本主流计算语言还是支持的。性能非常好,好到什么程度,快结束的时候给大家看一组数据对比。除了这个cuda toolkit的基本工具以外,还提供了非常多的库,cuBLAS,cuFFT(做一个傅里叶变换的),cuRAND(做随机数生成的),cuSPASE(做稀疏矩阵运算的库),cuDNN。
cuBLAS是一个基于cuda的极致BLAS库,和openBLAS功能是一样的,只不过openBLAS它是用CPU去做运算,而cuBLAS是以英伟达GPU去做运算,它是基于cuda实现的。
如果你用了toolKit,前四个库都再里面了,而cuDNN是需要你自己去下载的一个库,这个库是英伟达专门为深度神经网络定制的一个库。它在里面实现好了我们常用的一些卷积、池化操作,它的性能绝对比你手动去实现来的强。
所以我们在实际的机器学习框架基本全部是基于cuBLAS,还有cuDNN做的,尤其是现在的深度学习框架,基本都是基于cuBLAS和cuDNN这些东西来做的。
CUDA的基本计算思路
首先,cuda这种计算架构它为什么能够提供非常高的一个性能呢。
它之所以能够提供高性能的核心原因还在于GPU和CPU关键不同。
CPU:它的关键除了计算以外,它的最关键是逻辑处理,CPU里面有计算单元,逻辑处理单元,它有不同的单元。所以CPU里面的资源并不是完全用来做计算的。哪怕是一个多核的处理器,它每个核里都有一个独立的计算单元而已。
GPU:生来就是做图像浮点运算的。所以它会弱化我的逻辑性能,它是一个极致优化的计算架构。而逻辑处理能力就要比我们CPU弱很多。它和我们的CPU不同,CPU可能是一个核、两个核、三个核、四个核。而我们的GPU是什么架构呢,比如你去看一个显卡的性能的时候,都会关注里面有几个流处理器,比如说我们GPU里面会有非常多的流处理器。每个流处理器都是一个独立的计算单元。比如说你的流处理器可能有几百上千个流处理器。如果说我的流处理器越多的话,我可以同时执行的任务就越多。每个流处理器都会专注于我们的浮点运算。那也就是说假设我有一个非常大的计算。
我GPU会干嘛呢,可以把我的运算拆成很多小部分,把不同小部分交给不同的流处理器去做执行。我可以让我的不同的流处理器去执行不同的小的任务。我把我的大任务拆成小任务让不同的流处理器去执行。所以这个并行度是非常高的,GPU最大的特点就是它是一个高并行度的计算模型。这就使得我们的计算速度得到一个极大的提升。

所以说GPU它在计算上性能更好的非常关键的问题是在两部分,第一,它本身的计算器件是专门为我们浮点运算去做优化的,第二个,它本身的架构适合做一个大批量的并行处理。所以当我一次性送入的数据量越大,可并行的单位越多的时候呢,我GPU表现出来的性能就可以越好。
需要什么型号的英伟达显卡
如果不差钱,一般是K系列的,比如K40,K80,它是专门用来做计算的卡,但是价格贵,为了节约成本,会用GTX的卡,性能更好一点的话,我们会用泰坦卡,如果是用机器专门跑训练的话,我们那边都建议至少应该做到泰坦级别的卡,GTX970系列的也可以,如果是10系列的话,可以去买个GTX1070,或GTX1080性能相对来说也比较好的,Linux底下有CUDA的安装包,如果你是用Linux跑训练的话,个人建议不要装图形界面,因为CUDA的程序驱动很有可能和你系统自带的驱动会有冲突。到时候很有可能搞得你连系统都进不去,Linux底下驱动配置可能会稍微麻烦一点,大家可以去下载和看安装指南(CUDA下载地址),里面都讲的非常清楚。MAC也可以配CUDA,只要你用的是N卡也有。 非常可惜,AMD的显卡不能用CUDA,只能用openCL,计算用的显卡强烈不推荐AMD,业界标准,只要你做科学计算,用英伟达配CUDA。
性能比较
以下是在windows平台下,使用NVIDIA GeForce GTX 970的显卡型号,分别通过三种方式实现矩阵乘法运算:C = A * B的计算速度对比(分别为自己用C代码实现的三重for循环、用openBLAS实现的矩阵运算、CUDA的cuBLAS实现)。
三种计算性能的比较

性能差距非常巨大,用CUDA这种GPU去做运算,它提升的性能确实非常非常多。而openBLAS已经是在开源的解决方案里面最好的解决方案了。哪怕你是MKL,它也只是比openBLAS稳定一些。哪怕你用MKL的解决方案,它耗时也要20秒左右吧,GPU的提速是非常明显的,有GPU的大家都可以去试一下。