深度学习(十七)——SSD, YOLOv2
https://antkillerfarm.github.io/
SSD
SSD是Wei Liu于2016年提出的算法。
论文:
《SSD: Single Shot MultiBox Detector》
代码:
https://github.com/weiliu89/caffe
Wei Liu,南京大学本科(2009)+北卡罗莱娜大学博士(在读)。
个人主页:
http://www.cs.unc.edu/~wliu/
网络结构
YOLO有一些缺陷:每个网格只预测一个物体,容易造成漏检;对于物体的尺度相对比较敏感,对于尺度变化较大的物体泛化能力较差。
针对YOLO中的这些不足,SSD在这两方面都有所改进,同时兼顾了mAP和实时性的要求。其思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。

上图是SSD的网络结构图。其特点为:
1.采用VGG16的基础网络结构,使用前面的前5层。
2.使用Dilated convolution将fc6和fc7层转化成两个卷积层。
3.再额外增加了3个卷积层,和一个average pool层。不同层次的feature map分别用于default box的偏移以及不同类别得分的预测。
4.通过NMS得到最终的检测结果。
这些增加的卷积层的feature map的大小变化比较大,允许能够检测出不同尺度下的物体:在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。

上图是从另一个角度观察SSD,可以看出SSD可检出8372个default box。这里沿用Faster R-CNN的Anchor方法生成default box。

和YOLO一样,卷积层的每个点都是一个vector,含义也和YOLO类似,只是分类的时候,多了一个背景的类别,所以就成了20+1类。
在YOLO中,由于每个格子只有1个default box,所以对于一个格子中包含两个物体的情况是无能为力的。SSD的Anchor方法略微改善了这方面的性能,但对于超过Anchor数量的情况,仍然无能为力。因此,这两者对于小目标的检测,没有RCNN系列算法的效果好。
训练策略
监督学习训练的关键点:如何把标注信息(ground true box,ground true category)映射到(default box上)?
正负样本
与ground truth box的IOU大于0.5的default box,被定为该ground truth box的正样本,其它的default box则为负样本。
而一般的MultiBox算法中,只有IOU最大的default box才是正样本。
显然,在SSD中,一个ground truth box可能对应多个default box。

例如上图,有两个default box与猫匹配,一个default box与狗匹配。
Hard Negative Mining
Hard Negative Mining是机器学习领域的一个常用技巧。
对于正负样本数量不均衡的数据集(这里假设负样本数量远大于正样本数量),通常的做法有:
1.增加正样本的数量。这个过程通常叫做数据增强(Data Augmentation)。例如对图片进行旋转、位移得到新的正样本。
2.减少负样本的数量。这里实际上是一个筛选有价值的负样本的过程。Hard Negative Mining就属于这类方法,它认为负样本的分数越高,越有价值。
具体到图像分类任务就是:那些不包含该物体但分值却很高的样本。通俗的讲,就是那些容易被混淆的负样本。
3.修改正负判定门限,以匹配正负样本比例。例如,提高IOU门限。
4.异常点检测。
在SSD中,用于预测的feature map上的每个点都对应有6个不同的default box,绝大部分的default box都是负样本,导致了正负样本不平衡。
在训练过程中,采用了Hard Negative Mining的策略(根据confidence loss对所有的box进行排序,使正负例的比例保持在1:3)来平衡正负样本的比率。
参考:
https://mp.weixin.qq.com/s/D0JaJaHeNX4kljSTxTsAAw
一文概览卷积神经网络中的类别不均衡问题
Caffe实现的细节问题

上图是SSD末端的caffe结构图。我们注意到在flatten之前有个permute的操作。这个实际上还是和caffe blob的格式有关。
只有flatten的效果:[B, CxHxW]
permute+flatten的效果:[B, HxWxC]
C在最后,意味着同一个点的不同通道的信息挨着放在一起,从而保证了信息的局部空间性保持不变。
显然,这里如果是TensorFlow的tensor结构的话,permute就没有存在的必要了。
参考
http://www.jianshu.com/p/ebebfcd274e6
Caffe-SSD训练自己的数据集教程
https://zhuanlan.zhihu.com/p/24954433
SSD
http://blog.csdn.net/zy1034092330/article/details/72862030
SSD详解
http://blog.csdn.net/jesse_mx/article/details/74011886
SSD模型fine-tune和网络架构
http://blog.csdn.net/u010167269/article/details/52563573
SSD论文阅读
http://blog.csdn.net/zijin0802034/article/details/53288773
另一个SSD论文阅读
http://www.lai18.com/content/24600342.html
还是一个SSD论文阅读
https://www.zhihu.com/question/49455386
为什么SSD(Single Shot MultiBox Detector)对小目标的检测效果不好?
YOLOv2
面对SSD的攻势,pjreddie不甘示弱,于2016年12月提出了YOLOv2(又名YOLO9000)。YOLOv2对YOLO做了较多改进,实际上更像是SSD的升级版。
论文:
《YOLO9000: Better, Faster, Stronger》
实际上,论文的内容也正如标题所言,主要分为Better, Faster, Stronger三个部分。
Better
batch normalization
YOLOv2网络通过在每一个卷积层后添加batch normalization,极大的改善了收敛速度同时减少了对其它regularization方法的依赖(舍弃了dropout优化后依然没有过拟合),使得mAP获得了2%的提升。
High Resolution Classifier
所有state-of-the-art的检测方法基本上都会使用ImageNet预训练过的模型(classifier)来提取特征,例如AlexNet输入图片会被resize到不足256x256,这导致分辨率不够高,给检测带来困难。所以YOLO(v1)先以分辨率224x224训练分类网络,然后需要增加分辨率到448x448,这样做不仅切换为检测算法也改变了分辨率。所以作者想能不能在预训练的时候就把分辨率提高了,训练的时候只是由分类算法切换为检测算法。
YOLOv2首先修改预训练分类网络的分辨率为448x448,在ImageNet数据集上训练10轮(10 epochs)。这个过程让网络有足够的时间调整filter去适应高分辨率的输入。然后fine tune为检测网络。mAP获得了4%的提升。
Convolutional With Anchor Boxes
借鉴SSD的经验,使用Anchor方法替代全连接+reshape。
相应的,YOLOv2对于输出向量的编码方式进行了改进,如下图所示:

其主要思路是:将对类别的预测放到anchor box中。
同时,由于分辨率的提高,cell的数量由7x7改为13x13。这样一来就有13x13x9=1521个boxes了。因此,YOLOv2比YOLO在检测小物体方面有一定的优势。
Dimension Clusters
使用anchor时,作者发现Faster-RCNN中anchor boxes的个数和宽高维度往往是手动精选的先验框(hand-picked priors),设想能否一开始就选择了更好的、更有代表性的先验boxes维度,那么网络就应该更容易学到准确的预测位置。
解决办法就是统计学习中的K-means聚类方法,通过对数据集中的ground true box做聚类,找到ground true box的统计规律。以聚类个数k为anchor boxs个数,以k个聚类中心box的宽高维度为anchor box的维度。
作者做了对比实验,5种boxes的Avg IOU(61.0)就和Faster R-CNN的9种Avg IOU(60.9)相当。 说明K-means方法的生成的boxes更具有代表性,使得检测任务更好学习。
Direct location prediction
使用anchor boxes的另一个问题是模型不稳定,尤其是在早期迭代的时候。大部分的不稳定现象出现在预测box的(x,y)坐标时。
究其原因在于,虽然RPN会预测坐标的修正值 (Δx,Δy) ( Δ x , Δ y ) ,然而却未对 Δx,Δy Δ x , Δ y 的取值范围做限定。因此,可能会出现anchor检测很远的目标box的情况,效率比较低。
正确做法应该是每一个anchor只负责检测周围正负一个单位以内的目标box。
Fine-Grained Features
修改后的网络最终在13x13的特征图上进行预测,虽然这足以胜任大尺度物体的检测,但如果用上细粒度特征的话可能对小尺度的物体检测有帮助。
Faser R-CNN和SSD都在不同层次的特征图上产生区域建议以获得多尺度的适应性。
YOLOv2使用了一种不同的方法,简单添加一个passthrough layer,把浅层特征图(分辨率为26x26)连接到深层特征图。
具体操作如下:
1.叠加相邻空间位置的特征到不同通道,将26x26x512的特征图叠加成13x13x2048的特征图。
2.将浅层特征图(13x13x2048)和深层特征图(13x13x1024)合并为一个(13x13x3072)tensor。
Multi-Scale Training
为了让YOLOv2对不同尺寸图片具有鲁棒性,在训练的时候就要考虑这一点。
每经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,…,608},最小的尺寸为320 * 320,最大的尺寸为608 * 608。 调整网络到相应维度然后继续进行训练。
Faster
Darknet-19
YOLOv2使用了一个新的分类网络作为特征提取部分,参考了前人的先进经验,比如类似于VGG,作者使用了较多的3x3卷积核,在每一次池化操作后把通道数翻倍。
借鉴了network in network的思想,网络使用了全局平均池化(global average pooling),把1x1的卷积核置于3x3的卷积核之间,用来压缩特征。也用了batch normalization(前面介绍过)稳定模型训练。
最终得出的基础模型就是Darknet-19,其包含19个卷积层、5个最大值池化层(maxpooling layers )。如下图:
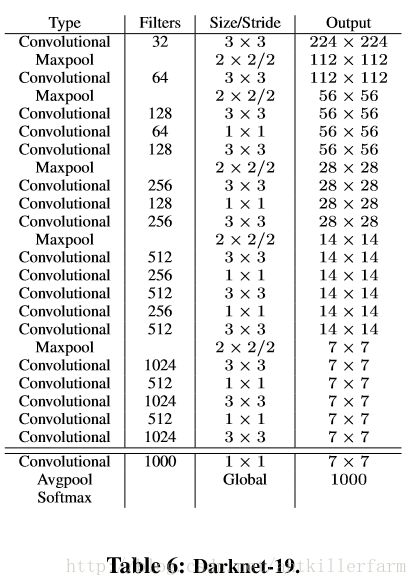
Darknet-19的运算量为55.8亿次浮点数运算。VGG-16为306.9亿次,而YOLO为85.2亿次。
Stronger
联合训练
作者提出了一种在分类数据集和检测数据集上联合训练的机制:
1.使用检测数据集的图片去学习检测相关的信息,例如bounding box坐标预测,是否包含物体以及属于各个物体的概率。
2.使用仅有类别标签的分类数据集图片去扩展可以检测的种类。
这种方法有一些难点需要解决。检测数据集只有常见物体和抽象标签(不具体),例如 “狗”,“船”。分类数据集拥有广而深的标签范围(例如ImageNet就有一百多类狗的品种,包括 “Norfolk terrier”, “Yorkshire terrier”, and “Bedlington terrier”等. )。必须按照某种一致的方式来整合两类标签。
大多数分类的方法采用softmax层,考虑所有可能的种类计算最终的概率分布。但是softmax假设类别之间互不包含,但是整合之后的数据是类别是有包含关系的,例如 “Norfolk terrier” 和 “dog”。所以整合数据集没法使用这种方式(softmax 模型),
作者最后采用一种不要求互不包含的多标签模型(multi-label model)来整合数据集。