100 Days Of ML Code:Day1-Data Preprocessing(数据预处理)
100天机器学习挑战汇总文章链接在这儿。
Data Preprocessing -- Getting Started with Machine Learning
第1天学习的内容主要是数据预处理。主要包括:
目录
Step 1:导入库
Step 2:导入数据集
Step 3:处理缺失数据
Step 4:把分类数据转换为数字
Step 5:将数据集分为训练集和测试集
Step 6:特征缩放
最后:全部代码
Step 1:导入库

import numpy as np
import pandas as pdStep 2:导入数据集

这一步首先用到的是pandas里面的read指令。可以参考这篇文章对它的基本指令进行复习。
接下来是要将自变量(3列)和因变量(1列)拆开,拆成一个矩阵和一个向量。
我的做法是:
df = pd.read_csv('Data.csv')
X = df.iloc[:, :3]
Y = df.iloc[:, 3]把X和Y print了一下,结果如下(这不是矩阵or向量的形式):

标答给出的提取matrix的方法是(这里列的范围取“:-1”:效果是一样的;):
X = df.iloc[ : , :-1].values
Y = df.iloc[:, 3].values而values会把表的形式转换为矩阵或者向量,如下:
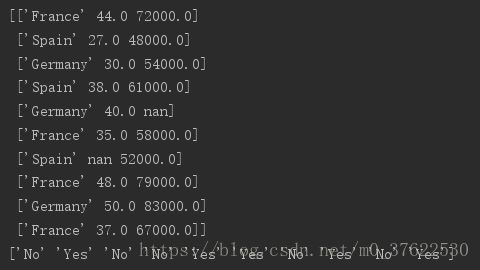
Step 3:处理缺失数据

Imuter的指导页面在这儿,此处还参考了这篇文章中对Imputer的使用范例。
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0, verbose=0, copy=True)
imp.fit(X[:, 1:])
X[:, 1:] = imp.transform(X[:, 1:])再重新打印X得到的是:
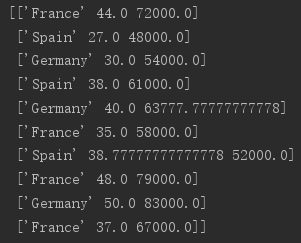
Step 4:把分类数据转换为数字

LabelEncoder的指导页面在这儿。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# print(le.fit(X[:,0]))
# 上一行得到的结果是:LabelEncoder()
# print(list(le.classes_))
# 上一行得到的结果是:['France', 'Germany', 'Spain']
# print(le.transform(list(le.classes_)))
# 上一行得到的结果是:[0 1 2]
# print(list(le.inverse_transform([0, 1, 2])))
# 上一行得到的结果是:['France', 'Germany', 'Spain']
X[:, 0] = le.fit_transform(X[:, 0])输出print(X[:, 0])的结果是:
[0 2 1 2 1 0 2 0 1 0]Step 5:将数据集分为训练集和测试集

train_test_split的指导页面在这儿。
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.20, random_state=0)我这里输出了一下X_train作为验证,结果如下(可以看出现在80%的数据用来训练):

Step 6:特征缩放

数据过大的时候,会占据更大的权重,所以要进行特征缩放。
StandardScaler的指导页面在这儿。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)打印一下新的X_train和X_test,结果为:

最后:全部代码
最后贴一下整个过程中全部的代码:
import numpy as np
import pandas as pd
df = pd.read_csv('Data.csv')
X = df.iloc[:, :3].values
Y = df.iloc[:, 3].values
# print(X)
# print(Y)
# print(X[:, 1:])
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0, verbose=0, copy=True)
imp.fit(X[:, 1:])
X[:, 1:] = imp.transform(X[:, 1:])
# print(X)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# print(le.fit(X[:,0]))
# 上一行得到的结果是:LabelEncoder()
# print(list(le.classes_))
# 上一行得到的结果是:['France', 'Germany', 'Spain']
# print(le.transform(list(le.classes_)))
# 上一行得到的结果是:[0 1 2]
# print(list(le.inverse_transform([0, 1, 2])))
# 上一行得到的结果是:['France', 'Germany', 'Spain']
X[:, 0] = le.fit_transform(X[:, 0])
# print(X)
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.20, random_state=0)
# print(X_train)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)
# print(X_train)
# print(X_test)