MSER相关总结
最近做项目用到了MSER,特地在这做总结。
以前提到字符检测首先会想到Tesseract,但是tesseact对图像的二值化要求过高,比较适合于白底黑字的字符识别,对于复杂情况就无能为力了;
于是就想到用轮廓检测,这种方法试验过后,对我的课题效果不太管用,或者说是适用性不太广泛,因此决定放弃;在阅读几篇论文之后,发现了MSER,这里首先说一下,我搜论文的时候用到了关键字:natural sence才搜到这几个论文,以前都是搜索character detection or recognition,应该把这两个关键字加在一起,才会有更多自然情况下字符检测的论文出来;
这里首先把这几个论文贴出来;
第一篇:ROBUST TEXT DETECTION IN NATURAL IMAGES WITH EDGE-ENHANCED MAXIMALLY STABLE EXTREMAL REGIONS ,Huizhong Chen 。相当好的一篇论文,将轮廓检测和MSER相结合;
第二篇:CHARACTER RECOGNITION IN NATURAL IMAGES;
三:Real-Time Scene Text Localization and Recognition。Luk´aˇs Neumann。这也是相当好的一篇文章,提到了对MSER的相关应用;
下边主要是我根据之前看过的博客,总结一个关于MSER的内容。
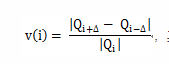

关于MSER的定义讲解,还有这篇文章:overview of mser
虽然是英文,但是很通俗易懂,这里把我认为很重要的摘抄出来:




Effect of Δ. We startwith a synthetic image which has an intensity profile as shown. The bumps have heights equal to 32, 64, 96, 128 and 160. As we increase Δ, fewer and fewer regions are detected until finally at Δ=160 there is no region R which is stable at R(+Δ).
The stability of an extremal region R is the inverse of the relative area variation of the region R when the intensity level is increased by Δ. Formally, the variation is defined as:
|R(+Δ) - R|
-----------
|R|
where |R| denotes the area of the extremal region R, R(+Δ) is the extremal region +Δ levels up which contains R and |R(+Δ) - R| is the area difference of the two regions.
A stable region has a small variation. The algorithm finds regions which are "maximally stable", meaning that they have a lower variation than the regions one level below or above. Note that due to the discrete nature of the image, the region below / above may be coincident with the actual region, in which case the region is still deemed(被认为) maximal.
However, even if an extremal region is maximally stable, it might be rejected if:
- it is too big (see the parameter
MaxArea); - it is too small (see the parameter
MinArea); - it is too unstable (see the parameter
MaxVariation); - it is too similar to its parent MSER (see the parameter
MinDiversity).
By default, MSERs are extracted for both dark-on-bright regions and bright-on-dark regions. To control this, parmeters BrightOnDark and DarkOnBright which take values 0 or 1 to enable or disable the regions
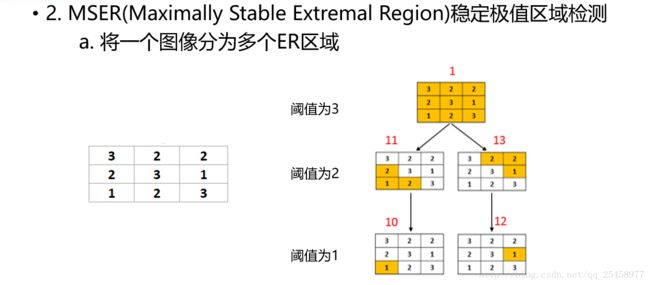
以下是MSER的算法步骤,最好是看一下,对于理解MSER的定义和计算过程有帮助;
以下总结来自于博客:文字识别与检测--1.MSER

 就是检测这个积木块上的字母
就是检测这个积木块上的字母