Hadoop杂说
也接触Hadoop好长时间了,一直想写篇关于Hadoop的博文,看来今天倒是挺不错,动动笔喽。
I.版本杂说:
Hadoop现在已经有了2.0版本,那么相比1.0版本,Hadoop确实解决了一些比较棘手的问题:
1、单点故障问题。由于1.0版本的NameNode只有一个,所以一旦部署NameNode的机器宕掉,整个集群就会瘫痪。所以,2.0版本增加了Secondary NameNode,它相当于NN的副手,它的作用不是要取代掉NN,也不是NN的备份。它会和NN进行通信,将快照更新到fsimage镜像文件,将修改保存到edits日志中,这就极大地降低了单点故障所带来的数据损失和宕机时间给集群的影响。
2、资源管理框架Yarn的引入。相比1.0版本,2.0版本将JobTracker的资源管理和作业控制分开,分别由负责所有应用程序资源分配的ResourceManager和负责管理应用程序的ApplicationMaster组成。这样,Hadoop的组成就变成了分布式存储HDFS,分布式计算MapReduce和资源管理系统Yarn。
II.节点杂说:
说到节点,我们就会想到NameNode,Secondary NameNode(高可用NameNode将不包含Secondary NameNode),DataNode三种节点。
普通的,Secondary NameNode会将NameNode中edits日志和fsimage做定期合并,防止Namenode的节点故障,并且,当namenode宕掉后需要快速启动的时候,Secondary NameNode会把合并好的fsimage镜像文件加载到NameNode内存中实现快速启动。
特别的, 若NameNode配置了高可用(即NameNode HA),集群将会有两个NameNode(这显然是不对的,此处要理解为一个工作,一个预备),Active和Standby,虽然会有两个NameNode,但真正管理集群的只有一个NameNode,即就是Active NameNode。因此,Active节点和Standby节点会保持状态同步,Active NameNode负责集群中的所有客户端操作,Standby充当备份,并且Standby机器要保持足够的状态以提供快速故障切换。
III.MapReduce杂说:
一般的,MR包括这几个组件:TextInputFormat,LineRecorderReader,Mapper,Shuffle,Reducer,LineRecorderWriter,TextOutputFormat。其中,shuffle包括partition,sort,combiner。
TextInputFormat和LineRecorderReader是输入组件,负责从HDFS读数据,默认将文件一行一行的读到map中进行处理。
LineRecorderWriter和TextOutputFormat是输出组件,负责把reducer处理好的数据写入DHFS,一般有几个reduceTask就会生成几个文件 (从partition的分组可以看出,此处的reduce Task就是partion的处理结果,即partion有几个分组就有几个reduce Task,进而也就有几个part文件)。
其他的在这里就不说了,提提shuffle里面的partition,partition的分组遵循 (key.hashCode() & Integer.MAX_VALUE) % reduceTasksNum 。
我们再来聊聊MR处理大数据集的过程。
如下图

首先是进行split切割,分成的split0,split1,split2...分别在map端变成一个个的mapTask,
接着,在map端映射成为一个个的
之后,这些
最后进入reduce阶段,这个阶段,每个
IV.HDFS杂说:
HDFS读
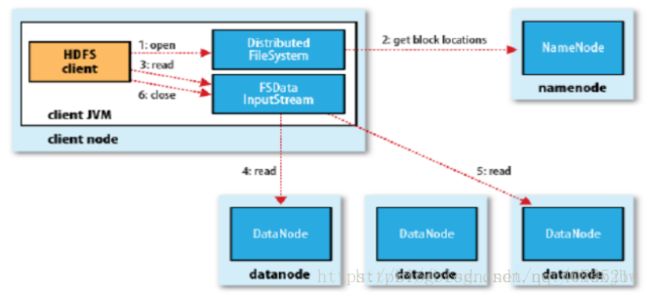
1、客户端向NameNode发出写文件请求。
2、检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。 (注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)
3、client端按128MB的块切分文件。
4、client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。 (注:并不是写好一个块或一整个文件后才向后分发)
5、每个DataNode写完一个块后,会返回确认信息。 (注:并不是每写完一个packet后就返回确认信息,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生)
6、写完数据,关闭输出流。
7、发送完成信号给NameNode。 (注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性)。
HDFS写
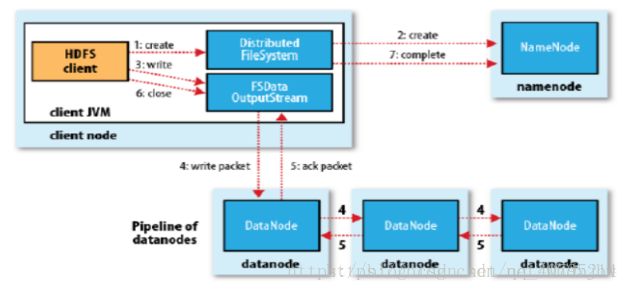
1、client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
2、就近挑选一台datanode服务器,请求建立输入流 。
3、DataNode向输入流中写数据,以packet为单位来校验。
4、关闭输入流。
V.Yarn杂说:
先上一张大家都用的图片,这张图片说了Hadoop的Yarn是怎么工作的。

组成Yarn的几个组件分别是ResourceManager,ApplicationMaster,NodeManager和Container等。
ResourceManager:一个Cluster只有一个,负责资源调度、资源分配等工作。
ApplicationMaster:ResourceManager将任务给Application Master,然后Application Master再将任务给NodeManager。每个Application只有一个ApplicationMaster,运行在Node Manager节点,Application Master是由ResourceManager指派的。
NodeManager:运行在DataNode节点,负责启动Application和对资源的管理。
Containers:Container通过ResourceManager分配。包括容器的CPU、内存等资源。
一个job运行处理的整体流程:
1、用户向YARN中提交作业,其中包括Application Master启动、Application Master的命令及用户程序等;ResourceManager为作业分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动该作业的Application Master;Application Master首先向ResourceManager注册,这样用户可以直接通过ResourceManager查询作业的运行状态,然后它将为各个任务申请资源并监控任务的运行状态,直到任务结束。Application通过RPC请求向ResourceManager申请和领取资源。
2、ApplicationMaster要求指定的NodeManager节点启动任务。
3、启动之后,去干ResoucrceManager指定的Map task。
4、等Map task干完之后,通知Application Master。然后Application Master去告知Resource Manager。接下来Resource Manager分配新的资源给Application Master,让它找人去干其他的活。
5、接下来Application Master通知NodeManager启动新的Container准备干新的活,该活的输入是Map task的输出。
6、开始干Reduce task任务。
7、等各个节点的Reduce task都干好了,将干活的NodeManager的任务结果进行同步。做最后的Reduce任务。
8、等计算都完了之后,就将最终的结果输出到HDFS,完成一个job。
注:部分参考
https://blog.csdn.net/whdxjbw/article/details/81072207
https://blog.csdn.net/u013063153/article/details/73692093