爬虫之Selenium模块
1.简介:
Selenium是一个we’b自动化测试工具,最初是为了自动化测试而开发的,Selenium可以直接调用浏览器,它支持所有的主流浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏等。使用selenium很容易完成一个爬虫。
2.安装使用:
1. 此处以谷歌(chrome)浏览器为例,安装chromedriver
-
查看当前浏览器版本

-
下载对应版本的driver
官方链接:http://npm.taobao.org/mirrors/chromedriver/ -
设置环境变量
右键此电脑------>属性------>高级系统设置----->环境变量----->双击系统环境变量中的Path行----->选择新建----->把下载的driver路径填进去
2. python对接selenium模块
pip3 install selenium
3.简单使用
-
打开百度浏览器,搜索python关键字
import time from selenium import webdriver # 调用chromedriver,如果没有配置系统环境变量,请用参数executable_path来指明chromedriver路径 driver = webdriver.Chrome() # 请求百度 driver.get("https://www.baidu.com/") # 使用属性选择器选择id=wk的标签(即浏览器输入框) # send_keys:输入内容python driver.find_element_by_id("kw").send_keys("python") # 找到id属性为su的标签,即百度一下按钮,点击它 driver.find_element_by_id("su").click() # 为了避免请求太快,我们看不清楚,此处有意模仿耗时操作 time.sleep(6) # 请求完成,关闭driver driver.quit()
3.driver对象的常用属性和方法
driver.page_source:当前标签页浏览器渲染后的网页源代码driver.current_url:当前标签页响应的urldriver.close():关闭当前标签页,如果只有一个标签页则关闭整个浏览器driver.quit():关闭浏览器driver.forward():页面前进driver.back():页面后退dirver.save_screenshot(img_name):页面截图
4.driver对象定位标签元素的方法
-
find_element_by_id(返回一个元素) -
find_element(s)_by_class_name(根据类名获取元素列表) -
find_element(s)_by_name(根据标签的name属性值,返回包含标签对象元素的列表) -
find_element(s)_by_xpath(根据xpath语法返回一个包含元素的列表) -
find_element(s)_by_link_text(根据连接文本获取元素列表) -
find_element(s)_by_partial_link_text(根据连接包含的文本获取元素列表) -
find_element(s)_by_tag_name(根据标签名获取元素列表,返回第一个元素,定位不到会报错) -
find_element(s)_by_css(根据css选择器来获取元素列表)注意:
find_element:返回匹配到的第一个元素,匹配不到报错
find_elements:返回匹配到的所有元素,以列表形式,匹配不到返回空列表
by_link_text:返回全部文本,绝对匹配,匹配不到会报错:find_element(s)_by_link_text(‘hao123’)
by_partial_link_text:包含某个文本,模糊匹配,包含:find_element(s)_by_partial_link_text(“hao”)
5.标签对象提取文本内容和属性值
find_element仅仅能够获取元素,不能直接获取其中的数据,如果需要获取数据,需要使用以下方法
1. 获取文本element.text
- 过定位获取的标签对象的
text属性,获取文本内容 - 通过定位获取的标签对象的
get_attribute函数,传入属性名,来获取属性值
2. 代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 获取百度热点下的文本内容
elements = driver.find_elements_by_class_name("title-content-title")
for element in elements:
print(element.text, + ": " + )
elements = driver.find_elements_by_link_text("新闻")
for element in elements:
print(element.get_attribute("href"))
driver.quit()
31省份新增10例确诊
霍启刚郭晶晶入住1.5亿独立屋
4个气象预警齐发
长江2020年第2号洪水在上游形成
台积电宣布断供华为
四川骨科大夫左手给右手做手术
http://news.baidu.com/
Process finished with exit code 0
6.selenium标签页的切换
1. 当selenium控制浏览器打开多个标签页时,如何控制浏览器再不同的标签页中进行切换呢?需要我们做如下两步:
1.获取所有标签页的窗口句柄(即指向标签页对象的标识)
2.利用句柄字切换到句柄指向的标签页对象的标识
2.具体方法
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://jn.58.com')
# 定位租房按钮
el = driver.find_element_by_class_name("contentAdTilRt")
el.click()
# 1.获取当前所有的标签页的句柄构成的列表
current_windows = driver.window_handles
# print(driver.current_url)
# 2.根据标签页句柄列表索引下标进行切换
# 新打开的标签页是当前标签页列表之后,所以根据当前页索引列表取最后一个
driver.switch_to.window(current_windows[-1])
# print(driver.current_url)
# 获取租房页的房屋标题和url
els = driver.find_elements_by_xpath("//ul[@class='house-list']/li/div[@class='des']/h2//a")
for el in els:
if el.text:
# 由于url太长,此处截取了前40个字符,便于观察
print(el.text, ": ", el.get_attribute("href")[0:40])
driver.quit()

6.selenium切换frame窗口
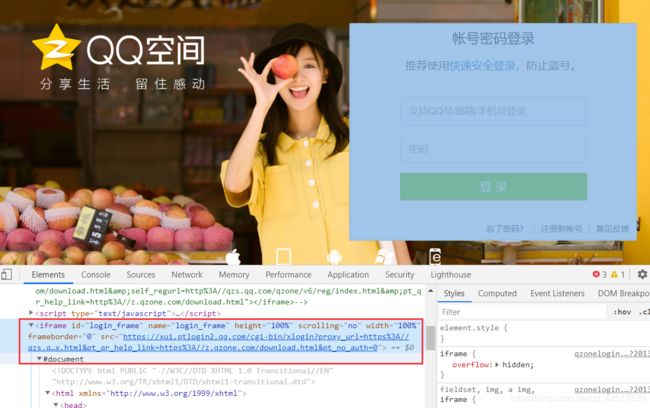
- 根据iframe窗口id元素定位到该窗口
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://qzone.qq.com/")
# 根据iframe框架id定位到该frame
driver.switch_to.frame("login_frame")
# 模拟点击账号密码登录
driver.find_element_by_id("switcher_plogin").click()
# 输入账户信息
driver.find_element_by_id("u").send_keys("账号")
driver.find_element_by_id("p").send_keys("密码")
# 点击登录
driver.find_element_by_id("login_button").click()
- 根据xpath定位到iframe元素,将其传给frame,从而定位到该窗口(避免iframe窗口不存在id属性的情况)
el_frame = driver.find_element_by_xpath("//*[@name='login_frame']")
driver.switch_to.frame(el_frame)
7.selenium处理cookies
1. 设置cookies
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 获取cookies
cookie_info = driver.get_cookies()
# 构建cookies
cookies = {cookie["name"]: cookie["value"] for cookie in cookie_info}
print(cookies)
2. 删除cookies
# 删除名称为CookieName的cookie
driver.delete_cookie("CookieName")
# 删除所有cookies
driver.delete_cookies()
8.selenium运行JS代码
- 当我们模拟点击某个元素时,这个元素再当前页面并看不到,需要下拉滚轮才可以看到,那么此时就需要模拟滚动,才可以找到该元素,从而进行点击。

import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://jn.lianjia.com/")
time.sleep(1)
# 滚动条的托动(水平值和垂直值),此处如果不滚动,则找不到元素,会报错
js = "scrollTo(0, 300)"
driver.execute_script(js)
# 找到元素点击
driver.find_element_by_xpath("/html/body/div[2]/ul/li/a").click()
driver.quit()
9.selenium页面等待
1. 强制等待
- time.sleep()
- 缺点:不智能呢个,设置时间太短,可能导致网页还没完全加载出来,设置时间太长,则会浪费时间
2. 隐式等待
- 设置一个时间,在一段时间内判断元素是否定位成功,如果完成了,就进行下一步,不需要继续等待设置的时间
- 在设置的时间内没有定位成功,则会报超时加载
- driver.implicitly_wait(10)
3. 显示等待
- 明确指定等待某一个元素,如果该元素未出现就继续等待,超时则报错。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 显示等待
# 参数20表示最多等待20秒
# 参数0.5表示每0.5秒检查一次规定的标签是否存在
WebDriverWait(driver, 20, 0.5).until(
ec.presence_of_all_elements_located((By.LINK_TEXT, 'hao123'))
)
print(driver.find_element_by_link_text('hao123').get_attribute('href'))
driver.quit()
10.selenium开启无界面模式
from selenium import webdriver
# 创建配置对象
opt = webdriver.ChromeOptions()
# 添加配置参数
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
# 创建浏览器对象的时候添加配置对象
driver = webdriver.Chrome(options=opt)
driver.get('https://www.baidu.com')
driver.save_screenshot('baiduyou.png')
11.selenium使用代理IP
- 更换ip代理必须重新启动driver
from selenium import webdriver
# 创建配置对象
opt = webdriver.ChromeOptions()
# 添加配置参数
opt.add_argument('--headless')
opt.add_argument('--proxy-server=http://114.239.172.17:9999')
# opt.add_argument('--user-agent=Mozilia/6.5') 可以通过请求头模拟手机请求
driver = webdriver.Chrome(options=opt)
driver.get('https://www.baidu.com')
driver.save_screenshot('baiduyou.png')
12. 斗鱼直播案例
import time
from selenium import webdriver
class Douyu(object):
def __init__(self):
self.url = 'https://www.douyu.com/directory/all'
self.driver = webdriver.Chrome()
def parse_data(self):
house_list = self.driver.find_elements_by_xpath("//ul[@class='layout-Cover-list']/li")
# house_list = self.driver.find_elements_by_xpath("//section[2]//ul[@class='layout-Cover-list']/li")
# house_list = self.driver.find_elements_by_xpath("//*[@id='listAll']/section[2]/div[2]/ul/li/div")
print(len(house_list))
data_list = list()
for house in house_list:
temp = dict()
temp['title'] = house.find_element_by_xpath(".//h3[@class='DyListCover-intro']").text
temp['img'] = house.find_element_by_xpath(".//div[contains(@class, 'DyImg')]//img").get_attribute("src")
temp['tag'] = house.find_element_by_xpath(".//span[@class='DyListCover-zone']").text
temp['room'] = house.find_element_by_xpath(".//h2[@class='DyListCover-user']").text
temp['hot'] = house.find_element_by_xpath(".//span[@class='DyListCover-hot']").text
data_list.append(temp)
return data_list
def save_data(self, data_list):
for data in data_list:
print(data)
def run(self):
# get
self.driver.get(self.url)
while True:
time.sleep(10)
# parse
data_list = self.parse_data()
# save
self.save_data(data_list)
# next
# 判断是否有下一页
next_el = self.driver.find_elements_by_xpath("//*[@class=' dy-Pagination-next']")
if next_el:
next_page = self.driver.find_element_by_xpath("//*[contains(text(), '下一页')]")
self.driver.execute_script("scrollTo(0, 1000)")
next_page.click()
else:
print("数据提取完成...")
break
if __name__ == '__main__':
douyu = Douyu()
douyu.run()