python爬虫之scrapy 框架学习复习整理三--CrawlSpider(自动提取翻页)
文章目录
- 说明:
- 自动提取下一页:Scrapy中CrawlSpider
- 1、再建立一个爬虫程序:
- 2、Scrapy中CrawlSpider的几个点:
- ①、CrawlSpider注意点:
- ②、LinkExtractor参数
- ③、Rule参数
- 3、简单修改下爬虫程序scrapyd2.py
- 1、正则匹配需要提取的地址:
- 测试如果正则匹配为空会怎样:
- 2、xpath匹配需求提取的地址:
- 3、结论:
- 4、修改parse_item
- 5、修改下管道储存的数据名称(防止和之前的混淆):
- 6、运行:scrapy crawl scrayd2:
说明:
这次是接着上一次的爬虫:python爬虫之scrapy 框架学习复习整理二
进行补充,上一次是自己对响应的页面,进行分析,查找出下一页的地址,使用requests发送请求,解析方法还是parse函数。
这次使用自动从响应页面提取出需要爬取的地址,然后接着再次爬取,直至,提取的地址都爬取完毕。
自动提取下一页:Scrapy中CrawlSpider
1、再建立一个爬虫程序:
scrapy genspide -t crawl scrapyd2 lab.scrapyd.cn
解释下:scrapy genspide -t crawl 是固定格式,后面跟的scrapyd2是程序名字name,后面是允许爬取的域名,后续可以自己增加需要爬取的域名。
执行之后会生成一个scrapyd2.py文件。
scrapyd2.py文件模板自动生成格式为:
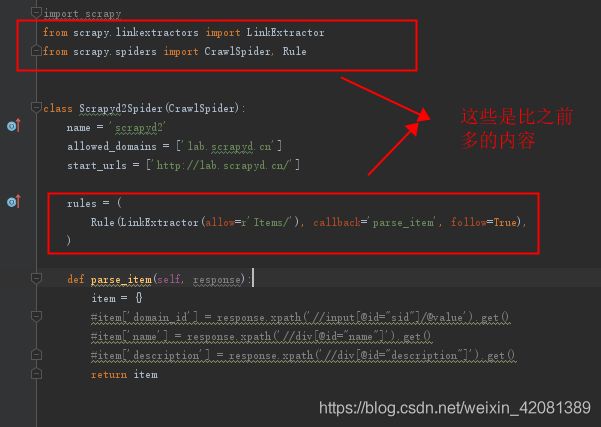
2、Scrapy中CrawlSpider的几个点:
①、CrawlSpider注意点:

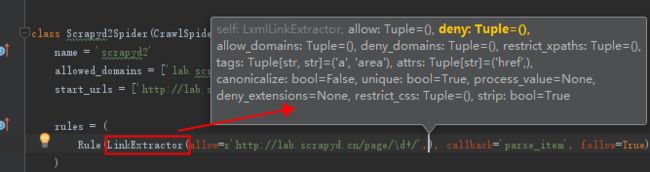
②、LinkExtractor参数

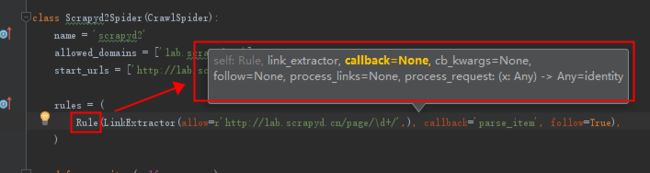
③、Rule参数

3、简单修改下爬虫程序scrapyd2.py
1、正则匹配需要提取的地址:
初步修改的完整代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Scrapyd2Spider(CrawlSpider):
name = 'scrapyd2'
allowed_domains = ['lab.scrapyd.cn']
start_urls = ['http://lab.scrapyd.cn/']
rules = (
Rule(LinkExtractor(allow=r'http://lab.scrapyd.cn/page/\d+/',), callback='parse_item', follow=True),
)
def parse_item(self, response):
print("进来了",response.url)
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
可以看到我只是修改可,rule和parse_item方法中的打印输出测试:
allow修改的是一个正则匹配,可以使用正则方法。
然后可以,执行:
scrapy crawl scrayd2
然后打印出来:

从结果我们可以看出,已经可以提取出翻页的url,并且爬取了翻页的地址。从打印出的翻页地址,可以充分体验出scrapy的爬取是一个异步的,因为我们就这几页的情况下,顺序还是乱序,如果翻页更多的情况下,那么顺序估计更乱。
测试如果正则匹配为空会怎样:

结果把所有的都给我匹配到了,只要是允许域名下的地址:

2、xpath匹配需求提取的地址:
只是修改了Rule:
经过我测试之后,发现使用xpath提取发现,’//[@id=“main”]//li[@class=“next”]/a’和’//[@id=“main”]//li[@class=“next”]'提取的结果是一样的,也就证实了,rule的规则,会把匹配到的HTML页面里面的所有地址,只要是allowed_domains 域名下的所有地址都会提取出来,作为下一个爬取url,放到url队列进行继续爬取。
rules = (
Rule(LinkExtractor(restrict_xpaths=('//*[@id="main"]//li[@class="next"]/a',), ), callback='parse_item', follow=True),
# Rule(LinkExtractor(restrict_xpaths=('//*[@id="main"]//li[@class="next"]',), ), callback='parse_item', follow=True),
# Rule(LinkExtractor(restrict_xpaths=('//*[@id="main"]',), ), callback='parse_item', follow=True),
)
定位到li和a标签,的结果和正则匹配是一样的。

处于好奇,我就测试了下,如果定位到href,会怎样,结果报错了。
‘//*[@id=“main”]//li[@class=“next”]/a/@href’

报错内容:看了使用xpath最多定位的url的a标签,着上一级的li
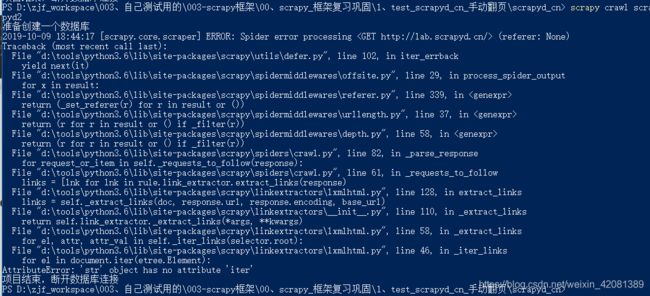
然后我又尝试了,如果定位到所有li的div会怎样,结果:
’//*[@id=“main”]'
结果:
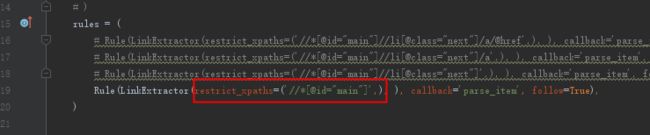
把div下所有是allowed_domains域名下的url都匹配过来了,所以,这个不精确的提取不建议使用,这些还是只有自己测试之后才会记得牢(当然时间长了也会忘,没事抽时间复习一下还是很有必要的)。

3、结论:
通过使用正则和xpath匹配尝试,得到:
- 如果使用正则,尽量匹配地址精确点,这样才不会出现页面混乱,不然解析页面是会出问题。
- 如果使用xpath匹配,进行精确到a标签,或者a标签的父级(如果父级有很多a标签,其他的a标签有些不符合,还是精确到a标签吧)
- 如果使用xpath匹配,不要匹配到href属性,不然还会报错
4、修改parse_item
直接把之前的代码复制过来了,只不过翻页步骤不要了:
def parse_item(self, response):
print("进来了",response.url)
# item = {}
# #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# #item['name'] = response.xpath('//div[@id="name"]').get()
# #item['description'] = response.xpath('//div[@id="description"]').get()
# return item
# 1、提取每一页的数据
div_list = response.xpath('//*[@id="main"]/div[@class="quote post"]')
for div in div_list:
# extract_first() 和 get() 返回的结果是一样的。
text = div.xpath('./span[@class="text"]/text()').get()
# author = div.xpath('.//*[@class="author"]/text()').extract_first()
author = div.xpath('.//*[@class="author"]/text()').get()
url = div.xpath('.//a[contains(text(),"详情")]/@href').get()
# print("div", text, author, url)
item = ScrapydCnItem()
# item = {}
item['text'] = text
item['author'] = author
item['url'] = url
yield item
5、修改下管道储存的数据名称(防止和之前的混淆):
和之前相比:多加了一个2
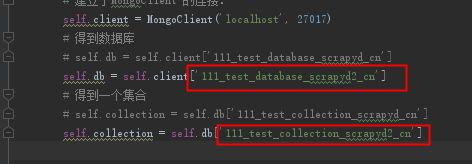
6、运行:scrapy crawl scrayd2:
scrapy crawl scrayd2
打印出来的数据:

MongoDB保存的数据:
