基础篇 | 15 C++ 科学计算 - OpenBLAS的安装与使用
BLAS简介
类似于Anaconda里面的numpy,C++里面也有类似的矩阵运算库,称之为BLAS(Basic Linear Algebra Subprograms):基础线性代数子程序库。
支持的数据类型有:
- 单精度浮点数(float)
- 双精度浮点数(double)
- 单精度复数
- 双精度复数
在机器学习里面一般我们只用float类型,很少使用double,考虑到性能,我们认为float的精度已经够了,而且速度快。
还有一个更高级的叫LAPACK,现在我们常用的BLAS其实就是LAPACK里面的一部分。
BLAS支持对子程序的封装,其实就是子函数了,它的子程序分类:
- Level1: 标量操作、向量操作、向量-向量操作
- Level2:矩阵-向量操作
- Level3: 矩阵-矩阵操作
BLAS的实现
BLAS:标准实现(Fortran)
CBLAS:C的BLAS标准实现
Atlas:一种优化实现
GotoBLAS:多线程性能良好的优化实现(已停止更新)
OpenBLAS:目前性能最好的开源实现,基于GotoBLAS
MKL:Intel实现,在Intel处理器上性能最佳
各种BLAS实现的优劣对比
市面上的BLAS实现非常多,最早是用Fortran。
CBLAS是C的BLAS标准实现,但是这种实现有个缺点,速度非常慢。
Atlas:比C要好,但不够好。比如腾讯QQ空间有一个功能,就是标脸框那个程序,怎么做呢,你每上传一张图片之后都会进行图片处理,处理完之后进行人脸检测,识别出来再把结果返回到你的业务服务器上去。那这就有个问题了,我怎么能非常快的处理这些图片。对于流量很大的网站来说,它的数据量是非常大的,我怎么能够高实时性的处理这些东西呢。这就对我们计算产生非常高的要求,要求我们计算非常快,而且是多线程的计算,所以,后来外国友人就推出了GotoBLAS,特点是在多线程的情况下性能是比较良好的。不过这个程序在2010已结不更新了,不去用它了。
目前性能最好的开源实现OpenBLAS。OpenBLAS的整体性能不够稳定,但是平均性能是所有库里面最好的。它的开发者是中国人,中科院研究所的张先义,GitHub仓库叫xianyi。它是由中国人维护的目前最好的开源实现,Caffe里面用的BLAS库就是OpenBLAS。
比如我们使用的numpy,上面使用的是Python接口,底下也用了BLAS库,比如anaconda的numpy就使用了OpenBLAS。
非开源库,MKL:Math Kernel Library。Intel推出的和Intel C++ 编译器绑定的一个库,这是目前在Intel处理器上性能最好的BLAS库,而且比OpenBLAS要稳定。但是有两个问题,1.它是和Intel C++ Compiler绑定的。如果你想使用它你必须使用Intel C++ Compiler。事实上呢可以利用DLL的封装性在这上面再封一层。我们可以先通过Visual C++的DLL,再去调用因特尔的C++的DLL,这个就脱离了必须和Intel C++ Compiler绑定的这个一个限制,这是一种变通。2.它只能用在Intel CPU 上。比如说你要做移动程序上的机器学习,比如把人脸识别放到你的手机上去做。它都是ARM芯片,MKL就无能为力了,因为它是给Intel做的。这个时候我们的首选就只有OpenBLAS,所以我们今天介绍的是OpenBLAS。
OpenBLAS是跨平台的,windows、Linux、macOS下都是可以有的。
Mac的Xcode下安装OpenBLAS
-
直接去OpenBLAS的官网或GitHub下载到本地即可,本文以GitHub下载为例说明。
-
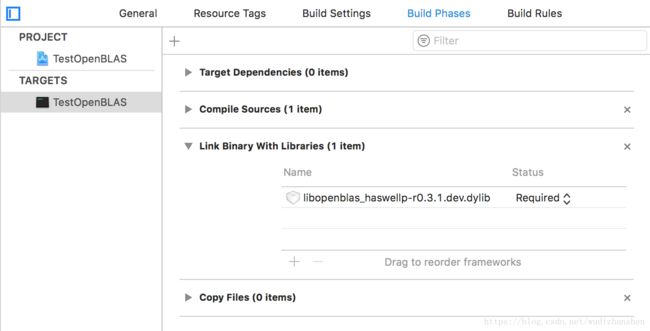
导入动态依赖库
在OpenBLAS的文件夹中找到如下动态库,直接拖入Link Binary With Libraries。

-
设置头文件和库的本地查找路径。
-
导入头文件,开始使用。
#include
BLAS的基本使用
我们先新建Xcode的C++工程,导入必要的头文件、声明会用到的函数定义和函数调用。
#include
#include
#include
#include
// 随机生成20以内的给定尺寸数组
static void RandomFill(std::vector& numbers,size_t size);
// 打印数组元素的函数
static void Print(const std::vector& numbers);
// vector是一维的,输出是个矩阵,那输出的时候就要指定有几行几列
static void Print(const std::vector& numbers, int rows, int cols);
// 寻找数组中最大的那个元素的索引和值
static void TestLevel1();
// 测试Level2里面最常用的函数:向量和矩阵的乘积
static void TestLevel2();
static void TestLevel3();
int main(int argc, const char * argv[]) {
TestLevel1();
TestLevel2();
TestLevel3();
return 0;
}
void RandomFill(std::vector& numbers, size_t size) {
// 预分配size的缓冲区,这样性能相对更好一点
numbers.resize(size);
for (size_t i = 0; i != size; ++ i) {
numbers[i] = static_cast(rand() % 20);
}
}
void Print(const std::vector& numbers) {
for (float number : numbers) {
std::cout << number << ' ';
}
std::cout << std::endl;
}
void Print (const std:: vector& numbers ,int rows, int cols) {
for (int row =0; row != rows; ++ row) {
for (int col = 0; col != cols; ++ col) {
// 取出每一列的数字
std::cout << numbers[row * cols + col] << ' ';
}
// 没输出一行之后换一行
std::cout << std::endl;
}
}
接下来我们依次看一下OpenBLAS在三个子程序上的基本使用。
Level1:找出数组的最大值和改值所在的Index
static void TestLevel1() {
const int VECTOR_SIZE = 4;
std::vector fv1;
RandomFill(fv1, VECTOR_SIZE);
Print(fv1);
/**
从数组里面找出最大的那个数的索引:cblas_isamax()属于Level1的函数
VECTOR_SIZE 数组长度
fv1.data 数组缓冲区指针的首地址,怎么获得fv1内部缓冲区呢,用fv1.data
third params: 跳跃数量,两个元素之间间隔几个元素,也就是每处理一个元素之后,+1得到下一个元素,如果想跳过一个元素 +2
*/
size_t maxIndex = cblas_isamax(VECTOR_SIZE, fv1.data(), 1);
std::cout << maxIndex << std::endl;
std::cout << fv1[maxIndex] << std::endl;
}
/*
Prints:
7 9 13 18
3
18
*/
Level2常用函数:计算向量与矩阵的乘积
/*
测试Level2里面最常用的函数:向量和矩阵的乘积
*/
static void TestLevel2()
{
// 假设我们有一个三行二列的矩阵
const int M = 3;
const int N = 2;
/*
A(M*N),x(N*1), y(M*1)
我们定义三个矩阵a、x、y
a:M*N的矩阵:维度为M*N矩阵
x:N*1的矩阵,实际上是一个向量,维度为N矩阵
y:M*1的矩阵,实际上是长度为M的向量,维度为M的矩阵
*/
std::vector a;
std::vector x;
std::vector y;
RandomFill(a, M * N);
RandomFill(x, N);
RandomFill(y, M);
std::cout << "A" << std::endl;
Print(a, M, N);
std::cout << "x" << std::endl;
Print(x);
std::cout << "y" << std::endl;
Print(y);
/*
我们的目标是想计算这么一个公式:
y := alpha * A * x + beta * y
A:是一个矩阵,x是一个向量,所以我希望说去计算一个矩阵和向量的乘积。alpha是一个乘积的缩放,
beta是对y的缩放,
相当于把y里面的数字乘以beta,再加上A矩阵和向量的乘积。
那这边有一个特例,假如我y里面都是0,或这beta是0的情况下,我就可以把公式看成:
// y := alpha * A * x
这个函数名称为:cblas_sgemv()
// s:single 单精度浮点数
// ge: 是一个乘法
// m: matrix
// v: vector
*/
/**
参数解释:
param CblasRowMajor 行主序还是列主序,默认行主序,何为主序:即数组存储元素的方式--按行存储还是按列存储,行主序:00,01,列主序00,10
param CblasNoTrans 矩阵是否需要转置,不需要转置,如果需要转置的话,运算的时候它会自动做转置
param M 矩阵的行数
param N 矩阵的列数
param 1.0f alpha ,我们设为1
param a.data a矩阵的缓冲区首地址
param lda a矩阵的列数
param x.data x矩阵的缓冲区首地址
param 1 x里面每次跳跃累加的个数,默认为1
param 2.0f beta对y的缩放值
param y.data y矩阵的缓冲区首地址
param 1 y里面每次跳跃累加的个数,默认为1
*/
int lda = N;
cblas_sgemv(CblasRowMajor, CblasNoTrans, M, N, 1.0f, a.data(), lda, x.data(), 1, 2.0f, y.data(), 1);
std::cout << "result y" << std::endl;
Print(y);
}
/*
Prints:
A
7 9
13 18
10 12
x
4 18
y
3 9 0
result y
196 394 256
*/
Level3常用函数:计算两个矩阵的乘积
/**
计算两个矩阵的乘积
*/
static void TestLevel3() {
// 我们希望计算两个矩阵的乘积,我们就需要定义三个参数M、N、K。
const int M = 3;
const int N = 2;
const int K = 4;
std::vector a;
std::vector b;
std::vector c;
RandomFill(a, M * K);
RandomFill(b, K * N);
RandomFill(c, M * N);
// 输出A、B、C 三个矩阵
std::cout << "A" << std::endl;
Print(a, M, K);
std::cout << "B" << std::endl;
Print(b, K, N);
std::cout << "C" << std::endl;
Print(c, M, N);
/*
我们的目标是计算这么一个公式:
// C := alpha * A * B + beta * C
// 如果只想做两个矩阵的乘法,beta设成0就好了,变为如下式子:
// C := alpha * A * B
*/
/*
函数释义:
sgemm:矩阵间的单精度乘法
s:single 单精度
ge:general 一般的,普通的
m:matix 矩阵
m:multiplication 乘法
*/
/**
参数释义:
param CblasRowMajor 行主序还是列主序,默认行主序
param CblasNoTrans A需不需要转置,不需要
param CblasNoTrans B需不需要转置,不需要
param M 系数M
param N 系数N
param K 系数K
param 1.0f alpha 设为1
param a.data a的缓冲区首地址
param lda a的列数
param b.data b的缓冲区首地址
param ldb b的列数
param 1.0f beta 设为1
param c.data c的缓冲区首地址
param ldc c的列数
*/
int lda = K;
int ldb = N;
int ldc = N;
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans, M, N, K, 1.0f, a.data(), lda, b.data(), ldb, 1.0f, c.data(), ldc);
std::cout << "Result C" << std::endl;
// 三行四列的矩阵 * 四行二列的矩阵 + 三行二列的矩阵,结果为一个三行二列的矩阵
Print(c, M, N);
}
/*
Prints:
A
7 9 13 18
10 12 4 18
3 9 0 5
B
12 2
7 3
7 9
0 12
C
3 9
9 17
0 13
Result C
241 383
241 325
99 106
*/