netty5笔记-线程模型4-无锁队列MpscLinkedQueue
NioEventLoop里面使用了MpscLinkedQueue作为taskQueue,替换了父类中默认的LinkedBlockingQueue队列。taskQueue主要用于存放可执行任务,其调用的频率非常高,因此使用一个更高效的队列能带来很大的收益。 为什么在NioEvnetLoop里用MpscLinkedQueue替换了LinkedBlockingQueue,是使用了更好的算法?还是通过舍弃一些功能的情况来达到更高效的目的?
我们知道LinkedBlockingQueue也是一个高效的线程安全的队列,它使用了takeLock和putLock两个锁分别作用与消费线程和生产线程,避免了消费者和生产者直接的竞争。然而在消费者之间、生产者之间依然需要竞争各自端的锁。 对于NioEventLoop来说,taskQueue只有一个消费者,即运行NioEventLoop.run()的那个线程(如果不理解这句话,可以看前一篇NioEventLoop的介绍)。也就是说消费端不需要锁, 那是不是我们去掉消费端那把锁就能提高效率了呢? 并不是!! 在只有一个消费者的情况下,获取锁的时候由于没有竞争,一个cas就能完成锁定,效率实极高的。因此只去掉消费端的锁,对于单消费者的场景是没有效率的提高的。 那么? 难道要把生产者的锁也去掉?!! netty可以告诉你,是的。去掉takeLock,去掉puLock,让效率飞一会。。。还有一个关键是,代码简单的你想哭!!!
好了,我们来看看MpscLinkedQueue是怎么在单消费者多生产者的场景下去锁的。
首先,我决定把MpscLinkedQueue类的注释翻译一下,方便你有一个初步的了解,防止你没看完直接跑去实践结果发现有问题。
1、一个无锁的支持单消费者多生产者的并发队列;
2、 允许多个生产者同时进行以下操作:offer(Object),add(Object),addAll(Collection);
3、只允许一个消费者进行以下操作:poll(),remove(),remove(Object),clear();
4、以下方法不支持:remove(Object o),removeAll(Collection),retainAll(Collection);为啥不支持这三个方法? 看了后面的源码分析,也许你就知道答案了。
首先MpscLinkedQueue里面有一堆莫名其妙的字段,这个是用来消除伪共享的(想了解伪共享,可以看看这篇文章),直接忽视。
long p00, p01, p02, p03, p04, p05, p06, p07;
long p30, p31, p32, p33, p34, p35, p36, p37;
实际上的字段就两个headRef、tailRef,表示队列的头节点和尾节点,结构包含两个字段next和value, 通过这两个字段最终可形成一个单项链表:

可以看到,头结点是不存数据的,尾节点的next也是空的。初始化的时候头尾节点相同,且不包含数据。此时,headRef==tailRef且headRef.next = null
MpscLinkedQueue() {
MpscLinkedQueueNode tombstone = new DefaultNode(null);
setHeadRef(tombstone);
setTailRef(tombstone);
} public boolean offer(E value) {
if (value == null) {
throw new NullPointerException("value");
}
// 如果传入的是node则直接使用,否则实例化一个newTail
final MpscLinkedQueueNode newTail;
if (value instanceof MpscLinkedQueueNode) {
newTail = (MpscLinkedQueueNode) value;
newTail.setNext(null);
} else {
newTail = new DefaultNode(value);
}
// 更新尾节点为newTail,并获取被替换的原节点
MpscLinkedQueueNode oldTail = getAndSetTailRef(newTail);
oldTail.setNext(newTail);
return true;
}
protected final MpscLinkedQueueNode getAndSetTailRef(MpscLinkedQueueNode tailRef) {
// LOCK XCHG in JDK8, a CAS loop in JDK 7/6
return (MpscLinkedQueueNode) UPDATER.getAndSet(this, tailRef);
}
1、UPDATER.getAndSet(this, tailRef);
UPDATER是tailRef的一个AtomicReferenceFieldUpdater,可以原子的将tailRef修改,并返回修改前的数据;
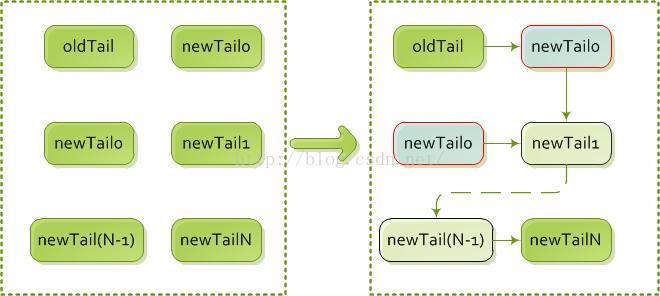
假设有N(N>0)个线程同时同时增加一条数据,则可能形成下图中左边的情况,此时场面虽然混乱,然而你会发现除了原来的oldTail和最后一个newTailN,其他的节点都会出现两次,而且一次作为new节点(刚被插入时),一次作为old节点(插入了其他新节点)。
2、oldTail.setNext(newTail);
而当执行到这句时,各个节点开始通过next进行连接。由于old和new是一一对应的关系,不存在竞争,所以最终可以很简单的形成下图中右边的状态(注意实际情况中是没有右下图第二排那个newTail0的状况的,因为它和第一排的newTail0是同一个对象,这里只是为了和左边对比。 另外虚线箭头表示中间可能还有N(N>=0)个节点。
消费者消费数据使用poll方法:
// 该方法获取链表中的第一个元素
private MpscLinkedQueueNode peekNode() {
MpscLinkedQueueNode head = headRef();
MpscLinkedQueueNode next = head.next();
// 头结点与尾节点相同,说明还在初始化状态,直接返回null(上面有讲过初始状态headRef.next=null)
if (next == null && head != tailRef()) {
// 当头结点与尾节点不同时,说明肯定已经有数据插入了;
// 此时如果队列还在上图左边的状态,则next == null。
// 由于oldTail.setNext(newTail)很快就会执行,因此此处直接不停的循环获取next
do {
next = head.next();
} while (next == null);
}
return next;
}
public E poll() {
final MpscLinkedQueueNode next = peekNode();
if (next == null) {
return null;
}
// next becomes a new head.
MpscLinkedQueueNode oldHead = headRef();
// 直接将此次获取到的数据修改成头结点
lazySetHeadRef(next);
// 将原头结点的next置为null,去除oldHead与新头结点之间的关联
oldHead.unlink();
// 获取节点中的数据,并将value置为null,去除节点与数据直接的关联
return next.clearMaybe();
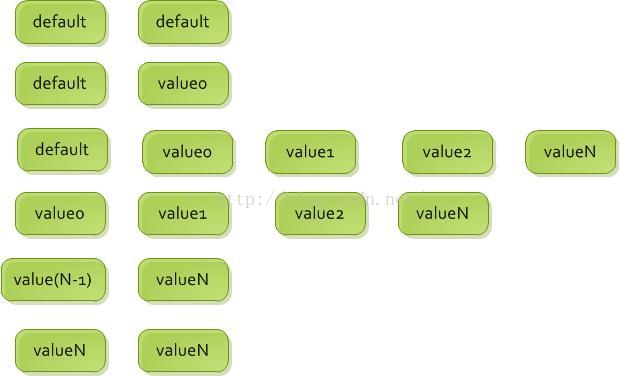
} 1、初始状态,头结点尾节点都为default,此时poll返回null;
2、生产者插入value0,并替换到tail节点,此时default.next = value0, value0.next = null,此时消费者可以poll;
3、生产者插入更多的value,形成第三行的链表,此时default.next = value0, value0.next = value1, valueN.next = null,此时消费者可以poll;
4、消费者消费掉第一个节点的数据,第一个节点变为头结点,此时value0.value = null;
5、经过多次消费,链表中只剩下一个节点,此时value(N-1).value=null,与第二种情况一致;
6、最后一个节点valueN被消费,此时valueN.value=null, 由于之前valueN是尾节点,所以valueN.next=null。 另外在消费者poll的时候并不会对尾节点做处理,所以此时尾节点还是valueN,此时的状况与1的状况一致。
到这里最关键的两个方法分析完成。 下面我们再回过头来看看前面留下的一个疑问,为啥不支持这三个方法:remove(Object o),removeAll(Collection),retainAll(Collection)
,现在回答这个问题已经很简单了,假设需要移除中间的一个元素:
1、初始状态为上图中第三行,但节点与节点之间完全没有关联(第二张图中的左半部分的状态),此时连遍历所有元素都无法完成,更别说要去做移除之类的操作了;
2、初始状态为上图中第三行(选这行是因为元素多比较方便看),且此时前半部分连接已经建立,后半部分连接未建立。即default.next = value0, value0.value=value1, 但value1.next = null;
尝试移除value1,由于链表可达,此时我们顺利将value1移除,并执行操作value0.next = value1.next,顺利吧。不过等等,此时value1.next=null啊,设置完以后value0.next变为null了,整个链表就会分裂成两个链表,后续的poll无法顺利完成。
3、初始状态为上图中第三行,且链表已形成,要求移除valueN,此时消费者成功便利到valueN,将value(N-1)设置为尾节点,而同时生产者正要插入value(N+1)。此时如果消费者先执行完毕生产者后执行,则整个操作可以顺利完成;如果生产者先执行,则生产者会设置valueN.next = value(N+1),尾节点为value(N+1),消费者后执行,将value(N-1)设置为尾节点,这样value(N+1)就丢失了。怎么解决?加锁! 好吧,那这个就变成了LinkedBlockingQueue的设计了。
因此,上面这几个方法暂时还是不能去实现的。