SDGAN
CVPR 2019 Semantics Disentangling for Text-to-Image Generation
Project Page

这篇文章属于Text-to-Image一类,它所解决的主要任务是如何根据文本的描述生成相应的图像,不仅要求生成的图像要清晰真实,而且更要求其符合给定的文本描述。类似的GAN模型有StackGAN(《StackGAN:Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks》探析)、StackGAN++、AttenGAN……,已经同样是收录于CVPR2019上的一篇StoryGAN,当然解决同样任务的模型还有很多,更多可见
arbitrary-text-to-image-papers
首先看一下本文所提出的SDGAN的效果如何

如上图所示,SDGAN和之前的StackGAN、AttenGAN进行了对比,从生成的图像可以直观的看出SDGAN的结果更清晰,同时与描述文本更相符,那么它是做了哪些工作才得到这么好的效果呢?首先看下题目:Semantics Disentangling for Text-to-Image Generation,将其翻译过来为用于用于Text-to-Image的语义分解,从中我们可以知道它是基于文本的语义来改进Text-to-Image的工作,进一步可以猜测它应该是考虑文本的高级语义和低级语义,SDGAN具体是如何做的,下面具体的来看一下。
作者指出由于对于同一张图像来说,不同的人会给出不同的描述,它们自然包含了对于图像主要信息的描述,同样也充满了多样性和个性化,因此如何从中提取出一致性的语义信息,同时保留描述的多样性和其中的细节信息,成为了Text-to-Image任务的一大难题。
在正式理解SDGAN模型之前,我们需要补充一些相关的基础知识,主要是Siamese structure network、Batch Normalization。
Siamese structure network
Siam是古代对于泰国的称呼,可译为暹(xian)罗,Siamese自然可译为暹罗人或泰国人。但Siamese structure network中的Siamese可译为孪生、连体
十九世纪泰国出生了一对连体婴儿,当时的医学技术无法使两人分离出来,于是两人顽强地生活了一生,1829年被英国商人发现,进入马戏团,在全世界各地表演,1839年他们访问美国北卡罗莱那州后来成为“玲玲马戏团” 的台柱,最后成为美国公民。从此之后“暹罗双胞胎”(Siamese twins)就成了连体人的代名词,也因为这对双胞胎让全世界都重视到这项特殊疾病。
Siamese network最早在2005年Yann Lecun提出,它可以看做是一种相似性度量方法,而它所主要解决的是one-shot(few-shot)的任务。one-shot任务是指在现实的场景中,数据集中的样本可能类别数很多,但是每个类别所包含的样本的数量很少,甚至极端情况下只有一张,在这样的情况下,如果使用传统的分类模型去做,往往得到的效果都不会太好,因为传统的模型依赖于大量有标注的样本。而one-shot希望做的就是使用极少的样本也可以得到不错的效果。
Siamese network试图从数据中去学习一个相似性度量,然后用这个习得的度量去比较和匹配新的未知类别的样本。它的模型架构如下所示

如果只是在pixel空间中进行相似性度量显然不合适,因此Siamese network通过某个映射函数将输入的样本映射到一个目标空间中,然后在目标空间中使用一般的距离度量方式进行相似度比较,希望同类的样本的距离应该相近,而不同类别的样本距离应较远。如上图所示, G W ( X ) G_{W}(X) GW(X)表示需要学习的映射函数,在Siamese network中只要求其可微,并不附加其他的限制条件,其中的参数 W W W的求解就是主要的工作。
对于输入 X 1 X_{1} X1和 X 2 X_{2} X2来说,当它们是同类别的样本时,相似性度量 E W ( X 1 , X 2 ) = ∥ G W ( X 1 ) − G W ( X 2 ) ∥ E_{W}\left(X_{1},X_{2}\right)=\left\|G_{W}\left(X_{1}\right)-G_{W}\left(X_{2}\right)\right\| EW(X1,X2)=∥GW(X1)−GW(X2)∥的值较小;当它们是不同类别的样本时, E W ( X 1 , X 2 ) = ∥ G W ( X 1 ) − G W ( X 2 ) ∥ E_{W}\left(X_{1}, X_{2}\right)=\left\|G_{W}\left(X_{1}\right)-G_{W}\left(X_{2}\right)\right\| EW(X1,X2)=∥GW(X1)−GW(X2)∥的值较大。因此,在训练集上使用成对的样本进行训练,输入同类别时最小化损失函数 E W ( X 1 , X 2 ) E_{W}\left(X_{1}, X_{2}\right) EW(X1,X2),而输入是不同类别时最大化 E W ( X 1 , X 2 ) E_{W}\left(X_{1}, X_{2}\right) EW(X1,X2)。
在模型中左右两个网络共享参数,因此可以看做两个完全相同的网络,它们的输出为低维空间中的 G W ( X 1 ) G_{W}(X_{1}) GW(X1)和 G W ( X 2 ) G_{W}(X_{2}) GW(X2),然后使用能量函数 E W ( X 1 , X 2 ) E_{W}(X_{1},X_{2}) EW(X1,X2)进行比较。如果假设损失函数只与输入 X i X_{i} Xi和参数 W W W有关,它的形式如下所示: L ( W ) = ∑ i = 1 P L ( W , ( Y , X 1 , X 2 ) i ) L ( W , ( Y , X 1 , X 2 ) i ) = ( 1 − Y ) L G ( E W ( X 1 , X 2 ) i ) + Y L I ( E W ( X 1 , X 2 ) i ) \begin{aligned} \mathcal{L}(W) &=\sum_{i=1}^{P} L\left(W,\left(Y, X_{1}, X_{2}\right)^{i}\right) \\ L\left(W,\left(Y, X_{1}, X_{2}\right)^{i}\right) &=(1-Y) L_{G}\left(E_{W}\left(X_{1}, X_{2}\right)^{i}\right) \\ &+Y L_{I}\left(E_{W}\left(X_{1}, X_{2}\right)^{i}\right) \end{aligned} L(W)L(W,(Y,X1,X2)i)=i=1∑PL(W,(Y,X1,X2)i)=(1−Y)LG(EW(X1,X2)i)+YLI(EW(X1,X2)i)其中 ( Y , X 1 , X 2 ) (Y,X_{1},X_{2}) (Y,X1,X2)表示第 i i i个样本,是由一组配对图片和一个标签( Y = 0 Y=0 Y=0表示同类别 Y = 1 Y=1 Y=1表示不同类别,)组成的,其中 L G L_{G} LG是只计算相同类别对图片的损失函数, L I L_{I} LI是只计算不相同类别对图片的损失函数。 P P P是训练的样本数。通过这样分开设计,可以达到当我们要最小化损失函数的时候,可以减少相同类别对的能量,增加不相同对的能量。
[1] S. Chopra, R. Hadsell, and Y. LeCun. Learning a similarity metric discriminatively, with application to face verification. In Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, volume 1, pages 539–546. IEEE, 2005.
[2] Mohammad Norouzi, David J. Fleet, Ruslan Salakhutdinov, Hamming Distance Metric Learning, Neural Information Processing Systems (NIPS), 2012.
Batch Normalization
BN是优化神经网络训练一个很重要的工具,大家应该都比较熟悉了,这里只给出一个简单的总结,如下所示

这个过程可以表示为 B N ( x ) = γ ⋅ x − μ ( x ) σ ( x ) + β \mathrm{BN}(x)=\gamma \cdot \frac{x-\mu(x)}{\sigma(x)}+\beta BN(x)=γ⋅σ(x)x−μ(x)+β
此外对BN的改进有Conditional Batch Norm,可以将其看作是在一般的特征图上的缩放和移位操作的一种特例,它的表示形式如下所示 BN ( x ∣ c ) = ( γ + γ c ) ⋅ x − μ ( x ) σ ( x ) + ( β + β c ) \operatorname{BN}(x | c)=\left(\gamma+\gamma_{c}\right) \cdot \frac{x-\mu(x)}{\sigma(x)}+\left(\beta+\beta_{c}\right) BN(x∣c)=(γ+γc)⋅σ(x)x−μ(x)+(β+βc)
其中 γ c \gamma_{c} γc和 β c \beta_{c} βc通过条件线索 c c c学得。
SDGAN
模型架构如下所示
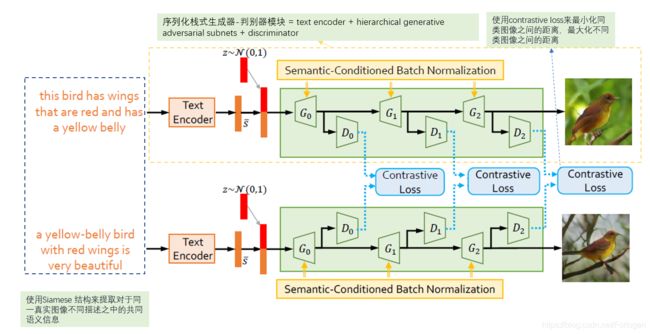
整个模型可以看作主要由 Siamese network + SCBN \text{Siamese network + SCBN} Siamese network + SCBN组成,其中使用 Siamese network \text{Siamese network } Siamese network 在判别器(Discriminator)中学习高层次的语义一致性,使用SCBN来发现 Sentence-level 和 Word-level 的细节信息。这样既可以提取出语义的一致性部分,由可以保留描述的多样性和细节部分。
模型的主要部分为:
-
text encoder:用于提取描述文本中的特征表示,文中采用的BiLSTM,其中 w t w_{t} wt表示第 i i i个词的特征向量,最后输出的隐状态 s ‾ \overline{\mathcal{s}} s表示整个句子的特征向量;
-
hierarchical generative adversarial subnets:用于图像的生成,由多对生成器和判别器组成,实现从低分辨到高分辨率的逐级过渡,每个阶段都由一个 G G G和一个 D D D配对组成, G G G生成的图像 D D D都会给出判别真假的结果。 G 1 G_{1} G1的输入不只是 s ‾ \overline{\mathcal{s}} s,还由一个采样自标准正态分布的噪声向量 z z z,使得对于很相近的描述,模型也可以生成不同的图像,如下图(a)所示; G 1 G_{1} G1和 G 2 G_{2} G2的输入包括上一阶段的低分辨率图像和描述文本 x x x,如下图(b)所示:
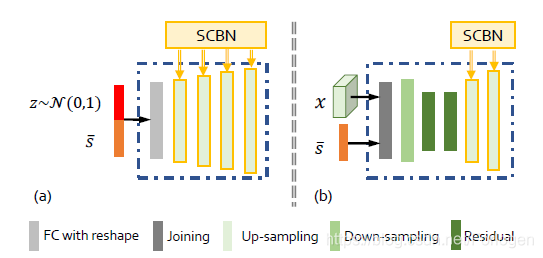
另外不同的判别器直接是彼此独立的。
-
adversarial discriminators:用于判断每阶段生成图像是否符合文本描述
Contrastive Loss
对于两个语义上相近的描述性文本生成的图像也应该类似,否则生成的图像应相差较远。因此可采用contrastive loss来提取成对的描述性文本输入中的语义信息,损失函数如下所示: L c = 1 2 N ∑ n = 1 N y ⋅ d 2 + ( 1 − y ) max ( ε − d , 0 ) 2 L_{c}=\frac{1}{2 N} \sum_{n=1}^{N} y \cdot d^{2}+(1-y) \max (\varepsilon-d, 0)^{2} Lc=2N1n=1∑Ny⋅d2+(1−y)max(ε−d,0)2其中 d = ∣ ∣ v 1 − v 2 ∣ ∣ d=||v_{1}-v_{2}|| d=∣∣v1−v2∣∣表示两个特征向量之间的距离, y y y表示输入的描述文本都是是针对于同一图像, y = 1 y=1 y=1表示相同, y = 0 y=0 y=0表示不同。 N N N表示特征向量的维度,其中 d = 256 d=256 d=256, ϵ = 1.0 \epsilon=1.0 ϵ=1.0。
通过使用Contrastive Loss来最小化来自同一图像描述的生成图像之间的距离,以及最大化来自不同图像描述的生成图像之间的距离来优化模型。同时为了避免生成无意义的结果,最终采用的形式如下所示 L c = 1 2 N ∑ n = 1 N y max ( d , α ) 2 + ( 1 − y ) max ( ε − d , 0 ) 2 L_{c}=\frac{1}{2 N} \sum_{n=1}^{N} y \max (d, \alpha)^{2}+(1-y) \max (\varepsilon-d, 0)^{2} Lc=2N1n=1∑Nymax(d,α)2+(1−y)max(ε−d,0)2其中 α = 0.1 \alpha=0.1 α=0.1同样是用来避免生成太过于相近的假样本。
Semantic-Conditioned Batch Normalization,SCBN
利用自然语言描述中的语言线索(linguistic cues)来调节条件批处理归一化,主要目的是增强生成网络特征图的视觉语义嵌入。它使语言嵌入能够通过上下缩放、否定或关闭等方式操纵视觉特征图,SCBN可以从输入中获取到语句级和词级两个层次上的语言线索。如下所示
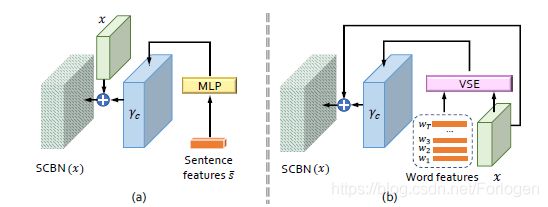
对于Sentence-level层级来说,首先将 s ‾ \overline{s} s通过感知机得到参数 γ c \gamma_{c} γc( β c \beta_{c} βc的计算一样),然后将其扩展到和 x x x相同的尺寸,作为 BN ( x ∣ c ) = ( γ + γ c ) ⋅ x − μ ( x ) σ ( x ) + ( β + β c ) \operatorname{BN}(x | c)=\left(\gamma+\gamma_{c}\right) \cdot \frac{x-\mu(x)}{\sigma(x)}+\left(\beta+\beta_{c}\right) BN(x∣c)=(γ+γc)⋅σ(x)x−μ(x)+(β+βc)的输入。 γ c = f γ ( s ‾ ) , β c = f β ( s ‾ ) \gamma_{c}=f_{\gamma}(\overline{s}),\beta_{c}=f_{\beta}(\overline{s}) γc=fγ(s),βc=fβ(s)
对于Word-level层级来说,使用VSE实现词特征和视觉特征的融合,同样得到 γ c \gamma_{c} γc和 β c \beta_{c} βc来作为 BN(x|c) \text{BN(x|c)} BN(x|c)的输入,其中VSE部分的计算为:
vse j = ∑ t = 0 T − 1 σ ( v j T ⋅ f ( w t ) f ( w t ) ) \text{vse}_{j}=\sum_{t=0}^{T-1}\sigma(v_{j}^T\cdot f(w_{t})f(w_{t})) vsej=t=0∑T−1σ(vjT⋅f(wt)f(wt))
实验
通过再CUB和MS-COCO两个数据集上进行实验,证明了SDGAN优于已有的模型
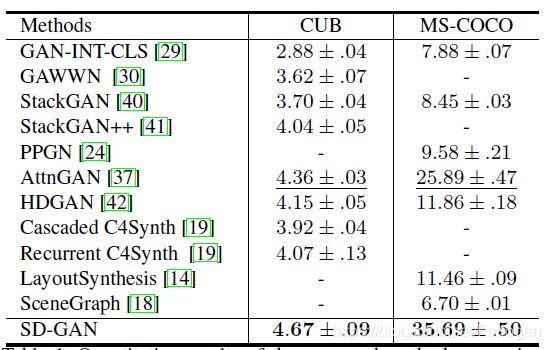
进一步通过实验证明了Siamese mechanism和SCBN的有效性


最后显示了SDGAN可以对描述文本中小的变化做出相应的改变

总结
整体来看,本文所使用的模型架构和新提出的SCBN具有一定的吸引力,为后面Text-to-Image 任务的解决提供了新的思路。
参考
Learning a similarity metric discriminatively, with application to face verification
Siamese network 孪生神经网络–一个简单神奇的结构
Siamese Network理解