HLS学习
文章目录
- High-Level Synthesis
- 流程
- 接口类型
- 数据类型
- 时钟/复位
- 延迟/吞吐率
- Perfect and Semi-Perfect Loops
- Schedule Viewer
- 时序问题
- 应用directives
- 对全局变量使用directives
- 设置directives时使用宏
- 为数组加上static、const限定符
- 使用超大数组时要这样
- 其他注意事项
- 设计优化
- HLS的优化指令
- loop_merge指令
- Dataflow指令
- pipeline指令
- array_partition指令
- array_reshape指令
- data_pack指令
- HLS的operators、cores
- 优化吞吐率
- 对函数和循环进行pipelining
- HLS的依赖关系
- 优化延迟
- 优化面积
- 优化逻辑
- 优化策略
- Frame-Based C Code
- Sample-Based C Code
- 简单使用
- C_Code,使用不同的directives,综合后比较不同solution的报告
- C_TestBench,设置仿真选项,Debug查看变量,联合仿真查看RTL波形
- 顶层函数调用多个子函数,使用dataflow指令
- 实现cordic,设置接口类型
- 实现加法树,多种情况
- 使用静态变量
- C_TB中测试次数的处理
- 处理ERROR!!! DEADLOCK DETECTED ! SIMULATION WILL BE STOPPED!
- 使用hls_math中的函数
- 小试复位
- 使用axi_lite
- 使用memcpy、使用排序
- 其他
- 1 --> Port 'xxxx' has no fanin or fanout and is left dangling
- 2 --> 函数单独综合时与作为子函数综合时,综合结果不同
- 论文
- 官网
- AR
- AR60236
- AR57876
- AR61063
- AR5169
- 论坛
High-Level Synthesis
流程


接口类型
综合支持的接口类型如下图所示,注意,scalar类型不能实现I/O,可以在函数return,函数参数中没有输出端口

数据类型
枚举类型
如果enum作为顶层函数的参数,则enum会被综合成32位的数据;如果是在内部函数中使用,则HLS会将其映射为特定位宽的数据。
任意精度数据类型

半精度浮点数(Half-Precision Floating-Point Data Types)
半精度浮点数详解
// Include half-float header file
#include “hls_half.h”
// Use data-type “half”
typedef half data_t;
// Use typedef or “half” on arrays and pointers
void top( data_t in[SIZE], half &out_sum);
C中的初始化
#include "ap_cint.h"
uint15 a = 0;
uint52 b = 1234567890U;
uint52 c = 0o12345670UL;
uint96 d = 0x123456789ABCDEFULL;
C++中的初始化
#include "ap_int.h"
ap_int<42> a_42b_var(-1424692392255LL); // long long decimal format
a_42b_var = 0x14BB648B13FLL; // hexadecimal format
a_42b_var = -1; // negative int literal sign-extended to full width
ap_uint<96> wide_var(“76543210fedcba9876543210”, 16); // Greater than 64-bit
wide_var = ap_int<96>(“0123456789abcdef01234567”, 16);
ap_int<6> a_6bit_var(“101010”, 2); // 42d in binary format
a_6bit_var = ap_int<6>(“40”, 8); // 32d in octal format
a_6bit_var = ap_int<6>(“55”, 10); // decimal format
a_6bit_var = ap_int<6>(“2A”, 16); // 42d in hexadecimal format
a_6bit_var = ap_int<6>(“42”, 2); // COMPILE-TIME ERROR! “42” is not binary
ap_int<6> a_6bit_var(“0b101010”, 2); // 42d in binary format
a_6bit_var = ap_int<6>(“0o40”, 8); // 32d in octal format
a_6bit_var = ap_int<6>(“0x2A”, 16); // 42d in hexidecimal format
a_6bit_var = ap_int<6>(“0b42”, 2); // COMPILE-TIME ERROR! “42” is not binary
//If the bit-width is greater than 53-bits, the ap_[u]fixed value must be initialized with a string
ap_ufixed<72,10> Val(“2460508560057040035.375”);
类型转换 && 位操作
显示类型转换(HLS不支持位宽大于64的任意精度数据隐式转换为C/C++内置数据类型,需要进行显示转换)
//----------------------------------------------------------
to_long()
to_bool()
to_int()
to_uint()
to_int64()
to_uin64t()
to_double()
位操作符
//----------------------------------------------------------
//Concatenation
ap_uint<10> Rslt;
ap_int<3> Val1 = -3;
ap_int<7> Val2 = 54;
Rslt = (Val2, Val1); // Yields: 0x1B5
Rslt = Val1.concat(Val2); // Yields: 0x2B6
(Val1, Val2) = 0xAB; // Yields: Val1 == 1, Val2 == 43
//----------------------------------------------------------
//Bit Selection
ap_uint<4> Rslt;
ap_uint<8> Val1 = 0x5f;
ap_uint<8> Val2 = 0xaa;
Rslt = Val1.range(3, 0); // Yields: 0xF
Val1(3,0) = Val2(3, 0); // Yields: 0x5A
Val1(3,0) = Val2(4, 1); // Yields: 0x55
Rslt = Val1.range(4, 7); // Yields: 0xA; bit-reversed
//----------------------------------------------------------
//and_reduce()
//or_reduce()
//xor_reduce()
//nand_reduce()
//nor_reduce()
//xnor_reduce()
ap_uint<8> Val = 0xaa;
bool t = Val.and_reduce(); // Yields: false
t = Val.or_reduce(); // Yields: true
t = Val.xor_reduce(); // Yields: false
t = Val.nand_reduce(); // Yields: true
t = Val.nor_reduce(); // Yields: false
t = Val.xnor_reduce(); // Yields: true
//----------------------------------------------------------
//Bit Reverse
ap_uint<8> Val = 0x12;
Val.reverse(); // Yields: 0x48
//----------------------------------------------------------
//Test Bit Value
ap_uint<8> Val = 0x12;
bool t = Val.test(5); // Yields: true
//----------------------------------------------------------
//set
//set_bit
//clear
//invert
ap_uint<8> Val = 0x12;
Val.set(0, 1); // Yields: 0x13
Val.set_bit(4, false); // Yields: 0x03
Val.set(7); // Yields: 0x83
Val.clear(1); // Yields: 0x81
Val.invert(4); // Yields: 0x91
//----------------------------------------------------------
//Rotate Left/Right
ap_uint<8> Val = 0x12;
Val.rrotate(3); // Yields: 0x42
Val.lrotate(6); // Yields: 0x90
//----------------------------------------------------------
//Test Sign
sign()
//----------------------------------------------------------
//Bitwise NOT
ap_uint<8> Val = 0x12;
Val.b_not(); // Yields: 0xED
//----------------------------------------------------------
sizeof(ap_int<127>)=16
sizeof(ap_int<128>)=16
sizeof(ap_int<129>)=24
sizeof(ap_int<130>)=24
数据print
//----------------------------------------------------------
ap_int<72> Val(“80fedcba9876543210”);
printf(“%s\n”, Val.to_string().c_str()); // => “80FEDCBA9876543210”
printf(“%s\n”, Val.to_string(10).c_str()); // => “-2342818482890329542128”
printf(“%s\n”, Val.to_string(8).c_str()); // => “401773345651416625031020”
printf(“%s\n”, Val.to_string(16, true).c_str()); // => “-7F0123456789ABCDF0
//----------------------------------------------------------
#include 时钟/复位
时钟
对于C、C++设计只支持单个时钟;对于SystemC设计,HLS是可以支持多个时钟的,每一个SC_MODULE都可以赋一个主时钟
复位/初始化
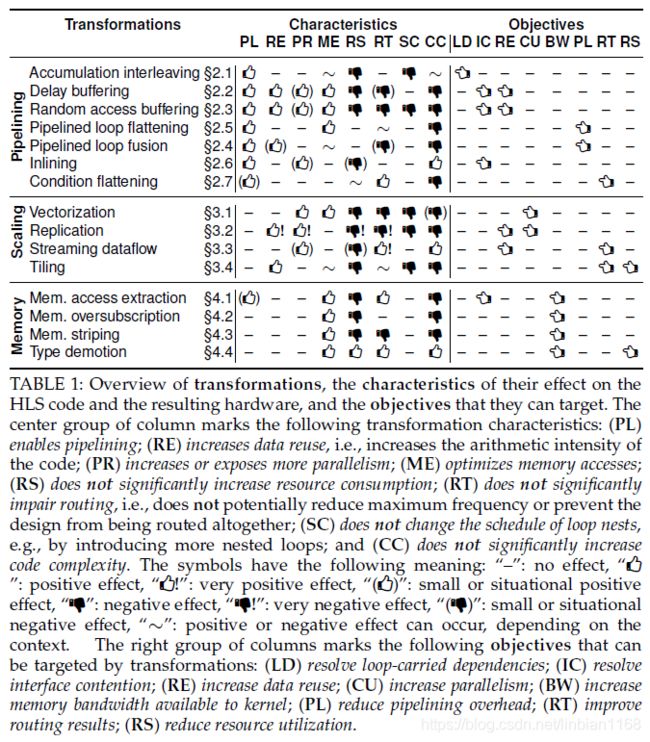
在C设计中,静态变量(Static)和全局变量(Global),默认都是会被编译器初始化为0的(当然这些变量也可以被明确的赋一个初值)。但不管怎样,这两种类型的变量,都是在编译的时候就会被初始化。
对于这些初始化变量,如果要使他们在运行中,重新回到初始化的状态,那么就必须要给他们赋一个复位信号(Reset)。
复位控制

| 选项 | 描述 |
|---|---|
| none | 整个rtl设计不加reset信号 |
| control | 这是默认选项。只对控制状态寄存器(比如状态机),和IO接口协议信号施加reset控制 |
| state | 除了Control选项的作用范围,这个选项还保证对所有的全局变量,和静态变量也施加reset信号。这可以保证全局和静态变量也能在reset信号的控制下,返回初始值 |
| all | 这个作用范围最广,它会保证HLS对所有的寄存器和Memory都施加reset信号 |
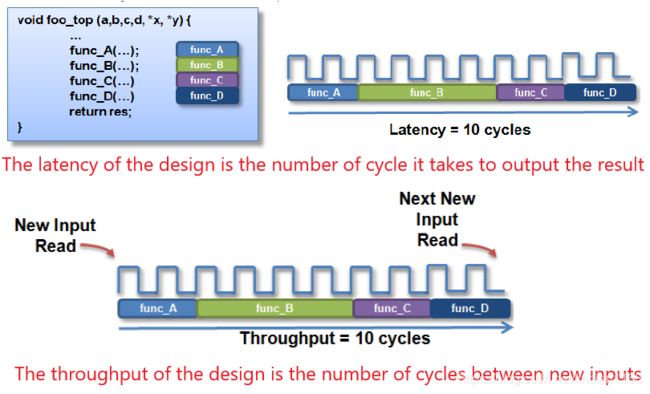
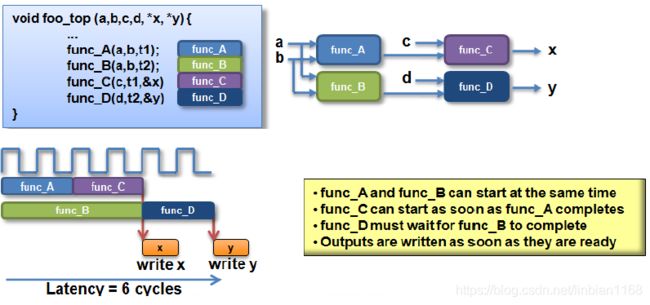
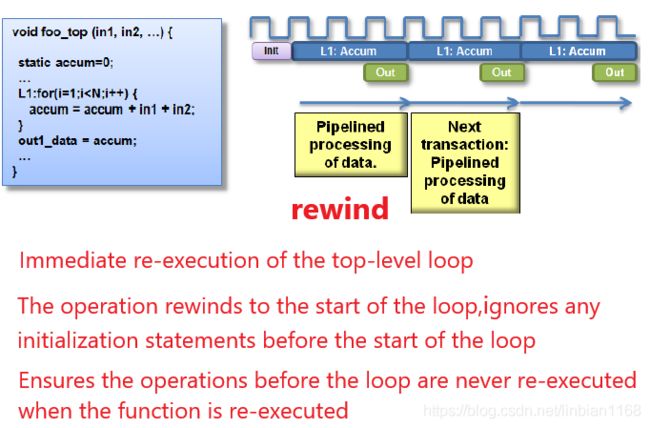
延迟/吞吐率
Perfect and Semi-Perfect Loops

Schedule Viewer
Schedule Viewer的目的:识别出任何阻止并行性,时序违规和数据依赖性的循环依赖性
在schedule viewer窗口中,
- 横轴上的纯灰色条显示的是连续的循环
- 纵轴显示操作和循环的名称
- 垂直虚线按比例显示由于时钟不确定而保留的时钟周期部分
- 对于每个操作,表中都显示一个灰色框。一般情况下,框的大小是水平的根据延迟的操作占总时钟周期的百分比
默认情况下,蓝线表征关键时序路径中每个操作之间的依赖关系,
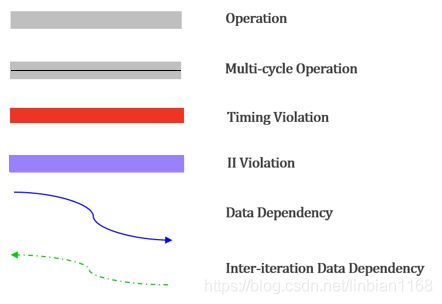
具体范例如下图,

时序问题
HLS design does not meet timing in video IP
Vivado HLS timing debugging tips/issues
Design timing not met
Vivado HLS and timing requirements in Vivado


应用directives

对全局变量使用directives

设置directives时使用宏

为数组加上static、const限定符
Xilinx建议在将数组映射为memory时,加上static限定符。因为,加入数组不加限定符且数组包含初始化内容,则每当函数执行的时候,数组都会耗费一定的时钟周期加载数组的各个初始值。此外,HLS不能每次都准确的将一个数组映射为ROM,因此,如果想将某个数组映射为ROM,需要加上const的限定符,来告诉HLS该数组是只读不写的。

使用超大数组时要这样

如上图,当直接在代码中如此设计时,在仿真时可能会报out of memory的错误,这是因为数组是放在栈中而不是放在堆中。一种解决方法是,在仿真时中使用动态内存分配,而在综合过程中这么设计。

其他注意事项
- 执行循环时,进入循环和退出循环都要额外花费一个时钟周期
- 函数是一直在执行的;循环则有结束条件
设计优化

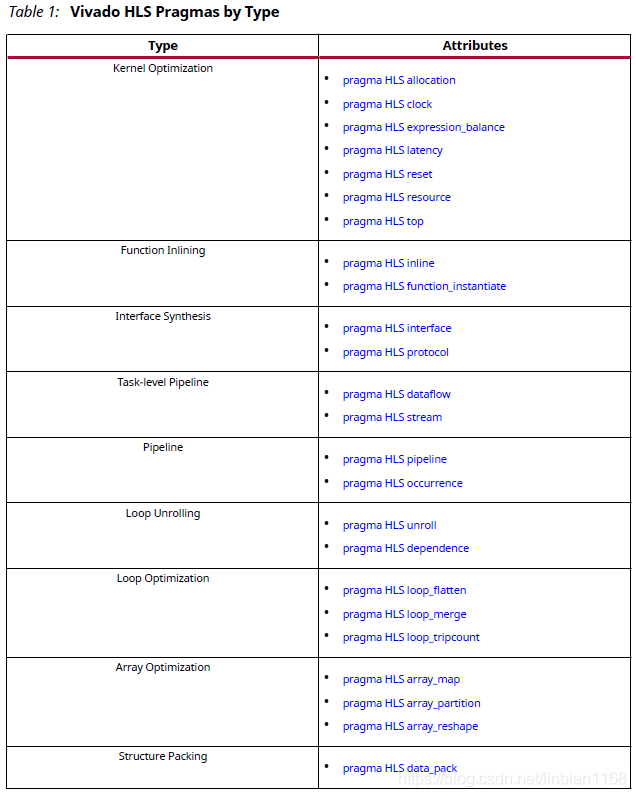
HLS的优化指令

loop_merge指令

Dataflow指令




pipeline指令


array_partition指令

array_reshape指令

data_pack指令

HLS的operators、cores
Vivado HLS Operators
| Operator | Description |
|---|---|
| add | Integer Addition |
| ashr | Arithmetic Shift-Right |
| dadd | Double-precision floating point addition |
| dcmp | Double -precision floating point comparison |
| ddiv | Double -precision floating point division |
| dmul | Double -precision floating point multiplication |
| drecip | Double -precision floating point reciprocal |
| drem | Double -precision floating point remainder |
| drsqrt | Double -precision floating point reciprocal square root |
| dsub | Double -precision floating point subtraction |
| dsqrt | Double -precision floating point square root |
| fadd | Single-precision floating point addition |
| fcmp | Single-precision floating point comparison |
| fdiv | Single-precision floating point division |
| fmul | Single-precision floating point multiplication |
| frecip | Single-precision floating point reciprocal |
| frem | Single-precision floating point remainder |
| frsqrt | Single-precision floating point reciprocal square root |
| fsub | Single-precision floating point subtraction |
| fsqrt | Single-precision floating point square root |
| icmp | Integer Compare |
| lshr | Logical Shift-Right |
| mul | Multiplication |
| sdiv | Signed Divider |
| shl | Shift-Left |
| srem | Signed Remainder |
| sub | Subtraction |
| udiv | Unsigned Division |
| urem | Unsigned Remainder |
Functional Cores
| Core | Description |
|---|---|
| AddSub | This core is used to implement both adders and subtractors. |
| AddSubnS | N-stage pipelined adder or subtractor. Vivado HLS determines how many pipeline stages are required. |
| AddSub_DSP | This core ensures that the add or sub operation is implemented using a DSP48 (Using the adder or subtractor inside the DSP48). |
| DivnS | N-stage pipelined divider. |
| DSP48 | Multiplications with bit-widths that allow implementation in a single DSP48 macrocell. This can include pipelined multiplications and multiplications grouped with a pre-adder, post-adder, or both. This core can only be pipelined with a maximum latency of 4. Values above 4 saturate at 4. |
| Mul | Combinational multiplier with bit-widths that exceed the size of a standard DSP48 macrocell.Note: Multipliers that can be implemented with a single DSP48 macrocell are mapped to theDSP48 core. |
| MulnS | N-stage pipelined multiplier with bit-widths that exceed the size of a standard DSP48 macrocell.Note: Multiplications which are >= 10 bits are implemented on a DSP48 macro cell. Multiplication lower than this limit are implemented using LUTs. Multipliers that can be implemented with a single DSP48 macrocell are mapped to the DSP48 core. |
| Mul_LUT | Multiplier implemented with LUTs. |
Floating Point Cores
| Core | Description |
|---|---|
| FAddSub_nodsp | Floating-point adder or subtractor implemented without any DSP48 primitives. |
| FAddSub_fulldsp | Floating-point adder or subtractor implemented using only DSP48s primitives. |
| FDiv | Floating-point divider. |
| FExp_nodsp | Floating-point exponential operation implemented without any DSP48 primitives. |
| FExp_meddsp | Floating-point exponential operation implemented with balance of DSP48 primitives. |
| FExp_fulldsp | Floating-point exponential operation implemented with only DSP48 primitives. |
| FLog_nodsp | Floating-point logarithmic operation implemented without any DSP48 primitives. |
| FLog_meddsp | Floating-point logarithmic operation with balance of DSP48 primitives. |
| FLog_fulldsp | Floating-point logarithmic operation with only DSP48 primitives. |
| FMul_nodsp | Floating-point multiplier implemented without any DSP48 primitives. |
| FMul_meddsp | Floating-point multiplier implemented with balance of DSP48 primitives. |
| FMul_fulldsp | Floating-point multiplier implemented with only DSP48 primitives. |
| FMul_maxdsp | Floating-point multiplier implemented the maximum number of DSP48 primitives. |
| FRSqrt_nodsp | Floating-point reciprocal square root implemented without any DSP48 primitives. |
| FRSqrt_fulldsp | Floating-point reciprocal square root implemented with only DSP48 primitives. |
| FRecip_nodsp | Floating-point reciprocal implemented without any DSP48 primitives. |
| FRecip_fulldsp | Floating-point reciprocal implemented with only DSP48 primitives. |
| FSqrt | Floating-point square root. |
| DAddSub_nodsp | Double precision floating-point adder or subtractor implemented without any DSP48 primitives. |
| DAddSub_fulldsp | Double precision floating-point adder or subtractor implemented using only DSP48s primitives. |
| DDiv | Double precision floating-point divider. |
| DExp_nodsp | Double precision floating-point exponential operation implemented without any DSP48 primitives. |
| DExp_meddsp | Double precision floating-point exponential operation implemented with balance of DSP48 primitives. |
| FAddSub_nodsp | Floating-point adder or subtractor implemented without any DSP48 primitives. |
| DExp_fulldsp | Double precision floating-point exponential operation implemented with only DSP48 primitives. |
| DLog_nodsp | Double precision floating-point logarithmic operation implemented without any DSP48 primitives. |
| DLog_meddsp | Double precision floating-point logarithmic operation with balance of DSP48 primitives. |
| DLog_fulldsp | Double precision floating-point logarithmic operation with only DSP48 primitives. |
| DMul_nodsp | Double precision floating-point multiplier implemented without any DSP48 primitives. |
| DMul_meddsp | Double precision floating-point multiplier implemented with a balance of DSP48 primitives. |
| DMul_fulldsp | Double precision floating-point multiplier implemented with only DSP48 primitives. |
| DMul_maxdsp | Double precision floating-point multiplier implemented with a maximum number of DSP48 primitives. |
| DRSqrt | Double precision floating-point reciprocal square root. |
| DRecip | Double precision floating-point reciprocal. |
| DSqrt | Double precision floating-point square root. |
| HAddSub_nodsp | Half-precision floating-point adder or subtractor implemented without DSP48 primitives. |
| HDiv | Half-precision floating-point divider. |
| HMul_nodsp | Half-precision floating-point multiplier implemented without DSP48 primitives. |
| HMul_fulldsp | Half-precision floating-point multiplier implemented with only DSP48 primitives. |
| HMul_maxdsp | Half-precision floating-point multiplier implemented with a maximum number of DSP48 primitives. |
| HSqrt | Half-precision floating-point square root. |
Storage Cores
| Core | Description |
|---|---|
| FIFO | A FIFO. Vivado HLS determines whether to implement this in the RTL with a block RAM or as distributed RAM. |
| FIFO_ | BRAM A FIFO implemented with a block RAM. |
| FIFO_LUTRAM | A FIFO implemented as distributed RAM. |
| FIFO_SRL | A FIFO implemented as with an SRL. |
| RAM_1P | A single-port RAM. Vivado HLS determines whether to implement this in the RTL with a block RAM or as distributed RAM. |
| RAM_1P_BRAM | A single-port RAM implemented with a block RAM. |
| RAM_1P_LUTRAM | A single-port RAM implemented as distributed RAM. |
| RAM_2P | A dual-port RAM that allows read operations on one port and both read and write operations on the other port. Vivado HLS determines whether to implement this in the RTL with a block RAM or as distributed RAM. |
| RAM_2P_BRAM | A dual-port RAM implemented with a block RAM that allows read operations on one port and both read and write operations on the other port. |
| RAM_2P_LUTRAM | A dual-port RAM implemented as distributed RAM that allows read operations on one port and both read and write operations on the other port. |
| RAM_S2P_BRAM | A dual-port RAM implemented with a block RAM that allows read operations on one port and write operations on the other port. |
| RAM_S2P_LUTRAM | A dual-port RAM implemented as distributed RAM that allows read operations on one port and write operations on the other port. |
| RAM_T2P_BRAM | A true dual-port RAM with support for both read and write on both ports implemented with a block RAM. |
| ROM_1P | A single-port ROM. Vivado HLS determines whether to implement this in the RTL with a block RAM or with LUTs. |
| ROM_1P_BRAM | A single-port ROM implemented with a block RAM. |
| ROM_nP_BRAM | A multi-port ROM implemented with a block RAM. Vivado HLS automatically determines the number of ports. |
| ROM_1P_LUTRAM | A single-port ROM implemented with distributed RAM. |
| ROM_nP_LUTRAM | A multi-port ROM implemented with distributed RAM. Vivado HLS automatically determines the number of ports. |
| ROM_2P | A dual-port ROM. Vivado HLS determines whether to implement this in the RTL with a block RAM or as distributed ROM. |
| ROM_2P_BRAM | A dual-port ROM implemented with a block RAM. |
| ROM_2P_LUTRAM | A dual-port ROM implemented as distributed ROM. |
| XPM_MEMORY | Specifies the array is to be implemented with an UltraRAM. This core is only usable with devices supporting UltraRAM blocks. |
优化吞吐率
对函数和循环进行pipelining

HLS的依赖关系
当使用pipeline的时候,需要考虑依赖关系。典型的依赖关系(数据依赖、存储依赖)是数据的读写顺序引起的,大致可以分为RAW、WAR、WAW三类。
//A read-after-write (RAW) is a true dependency when an instruction (and data it reads/uses) depends
//on the result of a previous operation
t = a * b;
c = t + 1;
//A write-after-read (WAR) is an anti-dependence when an instruction cannot update a register or
//memory (by a write) before a previous instruction has read the data
b = t + a;
t = 3;
//A write-after-write (WAW) is a dependence when a register or memory must be written in specific
//order otherwise other instructions might be corrupted
t = a * b;
c = t + 1;
t = 1;
//A read-after-read has no dependency as instructions can be freely reordered if the variable is
//not declared as volatile. If it is, then the order of instructions has to be maintained.
优化延迟
- 使用LATENCY指令
- 使用LOOP_MERGE指令
- 使用LOOP_FLATTEN指令
优化面积
- 对数据类型使用适当的精度
- 使用INLINE指令设置内联函数,减少层级
- 将多个数组合并成一个大数组
- 使用ARRAY_RESHAPE指令
- 使用FUNCTION_INSTANTIATE指令(当一个函数被调用时,函数的入参可能是常数,HLS提供了FUNCTION_INSTANTIATE指令,针对函数的调用情况进行优化,简化掉一部分控制逻辑,为同一个函数产生不同的RTL代码)
- 控制硬件资源
– 限制操作符的数量(使用ALLOCATION指令,处理function、loop、region作用域)
– 全局限制操作符数量(使用config_bind配置中的min_op选项)
– 控制硬核(使用ALLOCATION指令、RESOURCE指令)
优化逻辑
- 控制操作符的pipeline(使用RESOURCE指令的-latency选项显示指定pipeline的级数)
– 如果指定的latency延迟比HLS决定的多1,则HLS会在操作符的输出端添加一个寄存器
– 如果指定的latency延迟比HLS决定的多2,则HLS会在操作符的输入端、输出端各添加一个寄存器
– 如果指定的latency延迟比HLS决定的多3,则HLS会在操作符的输入端、输出端各添加一个寄存器;HLS会自动决定剩余的寄存器的位置。
- 优化逻辑表达式(使用EXPRESSION_BALANCE指令)
– 默认情况下,对于整型操作,expression balancing是使能的,但是可以禁止掉
– 默认情况下,对于浮点操作,expression balancing是禁能的,但是可以使能
优化策略
Frame-Based C Code

Sample-Based C Code

简单使用
C_Code,使用不同的directives,综合后比较不同solution的报告
可以使用directive的对象有Functions, Loops, Regions, Arrays, Top-level arguments
代码很简单,如下
data_typeD_t getSumSqrt(data_xyz_t a,data_xyz_t b)
{
data_typeA_t subAy[3];
data_typeB_t multAy[3];
data_typeC_t sum;
float fSum;
float fSumSqrt;
loop_mult_sub : for(int i=0;i<3;i++)
{
subAy[i] = a.xyz[i] - b.xyz[i];
multAy[i] = subAy[i] * subAy[i];
}
sum = multAy[0] + multAy[1] + multAy[2];
fSum = (float) sum;
fSumSqrt = sqrtf(fSum);
return (data_typeD_t) fSumSqrt;
}
对应的两组directives如下,唯一的区别在于solution2中,对整个函数进行了pipeline

比较两组solution对应的报告如下,可以看出solution2的Interval的值为1,

对应的RTL仿真波形如下,可以看出对顶层函数pipeline后,solution2中能够实现流水处理
solution1对应的RTL仿真图
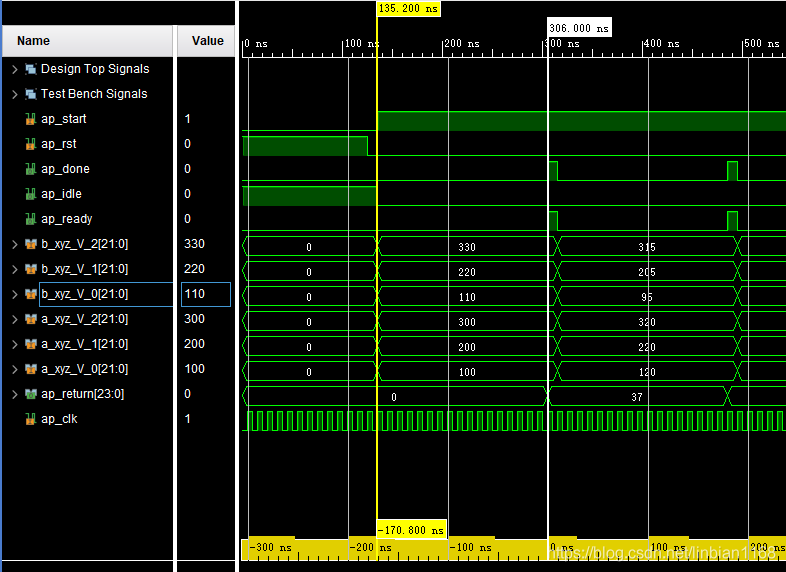
solution2对应的RTL仿真图

C_TestBench,设置仿真选项,Debug查看变量,联合仿真查看RTL波形
- testbench最好能够self-checking,对待综合函数的输出进行验证
- 如果仿真运行正常,则返回0;否则,返回非0值
仿真代码示例如下,注意,
- 在C代码中读入文件中的数据时,要将数据赋给标准类型的数据,之后再对其进行转换,赋给任意精度的数据
- 在C代码中将任意精度数据写入文件前,需要将其转换为标准类型的数据
- 如果任意精度的数据位宽超过64位,可以考虑按照字符串读入,再将字符串转换为任意精度数据
int main()
{
data_xyz_t a;
data_xyz_t b;
FILE * fp_data_a;
FILE * fp_data_b;
FILE * fp_result_matlab;
FILE * fp_result_fpga;
int a_0,a_1,a_2;
int b_0,b_1,b_2;
int c;
data_typeD_t srtqData_fpga;
data_typeD_t srtqData_matlab;
fp_data_a = fopen("data_a.txt","r");
fp_data_b = fopen("data_b.txt","r");
fp_result_matlab = fopen("result_matlab.txt","r");
fp_result_fpga = fopen("result_fpga.txt","w");
for(int m=0;m<100;m++)
{
//从文件中读入激励数据
fscanf(fp_data_a,"%d %d %d\n",&a_0,&a_1,&a_2);
fscanf(fp_data_b,"%d %d %d\n",&b_0,&b_1,&b_2);
a.xyz[0] = a_0;
a.xyz[1] = a_1;
a.xyz[2] = a_2;
b.xyz[0] = b_0;
b.xyz[1] = b_1;
b.xyz[2] = b_2;
//进行FPGA仿真
srtqData_fpga = getSumSqrt(a,b);
//比较FPGA仿真结果与MATLAB结果的差异,差别过大的话,返回-1,表征出错
fscanf(fp_result_matlab,"%d\n",&c);
srtqData_matlab = c;
fprintf(fp_result_fpga,"%d\n",srtqData_fpga.to_int());
if( ((srtqData_matlab-srtqData_fpga)>10) || ((srtqData_matlab-srtqData_fpga)<-10) )
{
return -1;
}
}
return 0;
}
C代码仿真时,有如下几个选项,
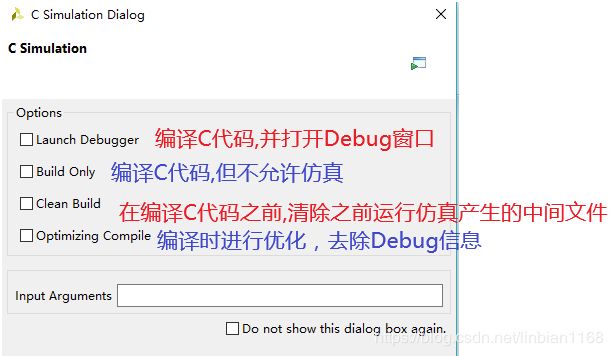
可以选择"Launch Debugger"选项,在Debug窗口中进行调试,查看程序运行过程中的变量。标准类型的数据可以直接在Expression中查看对应的值;如果想任意精度的数据,可以查看其对应的VAL的值,也可以使用to_int等类型转换语句查看对应值(个人觉得这样比较方便)

对于生成的RTL代码,C代码仿真时看不出输入输出接口的时序关系,这时可以进行联合仿真,查看波形,设置如下图,具体的RTL仿真波形截图参见上面的RTL波形图

顶层函数调用多个子函数,使用dataflow指令

头文件代码如下,其中对数据流、任意数据类型进行了typedef声明,
#ifndef _APP_H_
#define _APP_H_
#include "ap_int.h"
#include "ap_fixed.h"
#include "hls_math.h"
#include "hls_stream.h"
using namespace hls;
/*********************************************************
* 宏定义
*********************************************************/
#define XYZ_WIDTH (22)
#define TOA_WIDTH (22)
#define X_LOOP_MAX (1000)
#define Y_LOOP_MAX (1000)
#define Z_LOOP_MAX (100)
/*********************************************************
* 数据类型
*********************************************************/
typedef ap_int<XYZ_WIDTH> dinXYZ_t;
typedef ap_int<XYZ_WIDTH> dinTOA_t;
typedef ap_int<XYZ_WIDTH + 1> data_typeA_t;
typedef ap_int<XYZ_WIDTH*2 + 2> data_typeB_t;
typedef ap_int<XYZ_WIDTH*2 + 3> data_typeC_t;
typedef ap_int<XYZ_WIDTH + 2> data_typeD_t;
typedef ap_int<XYZ_WIDTH + 3> data_typeE_t;
typedef ap_int<XYZ_WIDTH*2 + 6> data_typeF_t;
typedef ap_int<XYZ_WIDTH*2 + 8> data_typeG_t;
typedef struct {
dinXYZ_t min;
dinXYZ_t step;
dinXYZ_t step_num;
} din_info_t;
typedef hls::stream<dinXYZ_t> my_xyz_stream;
typedef hls::stream<data_typeG_t> my_sumdata_stream;
/*********************************************************
* 函数声明
*********************************************************/
void genCurXyz(din_info_t xyzInfoAy[3],
my_xyz_stream &cur_x,my_xyz_stream &cur_y,my_xyz_stream &cur_z);
data_typeD_t getDistance(dinXYZ_t a[3],dinXYZ_t b[3]);
void computeSumData(dinXYZ_t M[3][3],dinXYZ_t S[3][3],dinTOA_t dToa[3],
my_xyz_stream &r_cur_x,my_xyz_stream &r_cur_y,my_xyz_stream &r_cur_z,
my_sumdata_stream &sumdata,
my_xyz_stream &w_cur_x,my_xyz_stream &w_cur_y,my_xyz_stream &w_cur_z);
void computeMinData(din_info_t xyzInfoAy[3],my_sumdata_stream &sumdata,
my_xyz_stream &r_cur_x,my_xyz_stream &r_cur_y,my_xyz_stream &r_cur_z,
dinXYZ_t find_xyz[3]);
void min_search(dinXYZ_t M[3][3],dinXYZ_t S[3][3],dinTOA_t dToa[3],din_info_t xyzInfoAy[3],dinXYZ_t find_xyz[3]);
#endif
C代码如下,其中,顶层函数是min_search。
- 在顶层函数中,依序调用了三个子函数,它们之间通过stream来实现参数传递
- 在设置dataflow时,将start_propagation禁止了(在config_rtl的GUI界面里,找不到该选项)
- M、S、dToa、xyzInfoAy的接口类型设置为ap_stable(在ap_rst信号无效之后,这些输入信号不会改变,我写的测试例子里不需要外部输入随时钟变化),如此设置是有原因的,如果设置为ap_none,由于整个min_search设置为dataflow,则M、S、dToa、xyzInfoAy端口会使用FIFO或乒乓RAM来实现,如果FIFO的深度设置不合适,则在C-RTL联合仿真时,会出现问题

- 在genCurXyz函数中,在每层for循环内,没有使用变量作为循环的边界,而是在循环内部判断迭代次数是否达到上限,如果达到上限,需要break跳出,否则该循环还是会执行到设定的最大迭代次数才跳出(这点是通过C-RTL仿真发现的,明明inter循环迭代次数已经达到入参设定的值,但outer循环的值却没有立刻改变)
- computeMinData函数是寻找一帧计算过程中的最小值,通过判断循环变量有没有都达到最大值,来判定搜索最小值得过程有没有结束
- 对computeSumData函数、computeMinData函数进行了pipeline处理
#include "app.h"
void min_search(dinXYZ_t M[3][3],dinXYZ_t S[3][3],dinTOA_t dToa[3],din_info_t xyzInfoAy[3],dinXYZ_t find_xyz[3])
{
static my_xyz_stream cur_x_0,cur_y_0,cur_z_0;
static my_xyz_stream cur_x_1,cur_y_1,cur_z_1;
static my_sumdata_stream sumdata;
genCurXyz(xyzInfoAy,cur_x_0,cur_y_0,cur_z_0);
computeSumData(M,S,dToa,cur_x_0,cur_y_0,cur_z_0,sumdata,cur_x_1,cur_y_1,cur_z_1);
computeMinData(xyzInfoAy,sumdata,cur_x_1,cur_y_1,cur_z_1,find_xyz);
}
/**********************************************************
* 计算当前坐标点
**********************************************************/
void genCurXyz(din_info_t xyzInfoAy[3],
my_xyz_stream &cur_x,my_xyz_stream &cur_y,my_xyz_stream &cur_z)
{
dinXYZ_t curXyz[3];
loop_x : for(int ii=0;ii<X_LOOP_MAX;ii++)
{
if(ii<=xyzInfoAy[0].step_num)
{
if(ii==0)
{
curXyz[0] = xyzInfoAy[0].min;
}
else
{
curXyz[0] += xyzInfoAy[0].step;
}
loop_y : for(int jj=0;jj<Y_LOOP_MAX;jj++)
{
if(jj<=xyzInfoAy[1].step_num)
{
if(jj==0)
{
curXyz[1] = xyzInfoAy[1].min;
}
else
{
curXyz[1] += xyzInfoAy[1].step;
}
loop_z : for(int kk=0;kk<Z_LOOP_MAX;kk++)
{
if(kk<=xyzInfoAy[2].step_num)
{
if(kk==0)
{
curXyz[2] = xyzInfoAy[2].min;
}
else
{
curXyz[2] += xyzInfoAy[2].step;
}
//将当前坐标写入stream中
cur_x.write(curXyz[0]);
cur_y.write(curXyz[1]);
cur_z.write(curXyz[2]);
}
else //如果不跳出当前循环,则循环仍会执行,只是没有什么有意义的操作
{
break;
}
}
}
else //如果不跳出当前循环,则循环仍会执行,只是没有什么有意义的操作
{
break;
}
}
}
else
{
break;
}
}
}
/**********************************************************
* 计算两个坐标点的欧式距离
**********************************************************/
data_typeD_t getDistance(dinXYZ_t a[3],dinXYZ_t b[3])
{
data_typeA_t subAy[3];
data_typeB_t multAy[3];
data_typeC_t sum;
float fSum;
float fSumSqrt;
loop_mult_sub : for(int i=0;i<3;i++)
{
subAy[i] = a[i] - b[i];
multAy[i] = subAy[i] * subAy[i];
}
sum = multAy[0] + multAy[1] + multAy[2];
fSum = (float) sum;
fSumSqrt = hls::sqrtf(fSum);
return (data_typeD_t) fSumSqrt;
}
/**********************************************************
* 计算差的平方和
**********************************************************/
void computeSumData(dinXYZ_t M[3][3],dinXYZ_t S[3][3],dinTOA_t dToa[3],
my_xyz_stream &r_cur_x,my_xyz_stream &r_cur_y,my_xyz_stream &r_cur_z,
my_sumdata_stream &sumdata,
my_xyz_stream &w_cur_x,my_xyz_stream &w_cur_y,my_xyz_stream &w_cur_z)
{
dinXYZ_t cur_xyz[3];
data_typeD_t sqrt_M_Ay[3],sqrt_S_Ay[3];
data_typeE_t sqrtSub_Ay[3];
data_typeF_t multSqrtSubAy[3];
data_typeG_t sum;
r_cur_x.read(cur_xyz[0]);
r_cur_y.read(cur_xyz[1]);
r_cur_z.read(cur_xyz[2]);
loop_xx : for(int i=0;i<3;i++)
{
sqrt_M_Ay[i] = getDistance(M[i],cur_xyz);
sqrt_S_Ay[i] = getDistance(S[i],cur_xyz);
sqrtSub_Ay[i] = sqrt_M_Ay[i] - sqrt_S_Ay[i] - dToa[i];
multSqrtSubAy[i] = sqrtSub_Ay[i] * sqrtSub_Ay[i];
}
sum = multSqrtSubAy[0] + multSqrtSubAy[1] + multSqrtSubAy[2];
//将计算结果写入数据流中
sumdata.write(sum);
w_cur_x.write(cur_xyz[0]);
w_cur_y.write(cur_xyz[1]);
w_cur_z.write(cur_xyz[2]);
}
/**********************************************************
* 统计最小值
**********************************************************/
void computeMinData(din_info_t xyzInfoAy[3],my_sumdata_stream &sumdata,
my_xyz_stream &r_cur_x,my_xyz_stream &r_cur_y,my_xyz_stream &r_cur_z,
dinXYZ_t find_xyz[3])
{
static data_typeG_t minData = 0xFFFFFFFFFFFF;
data_typeG_t cur_sum_data;
dinXYZ_t max_xyz[3];
dinXYZ_t cur_xyz[3];
dinXYZ_t temp_xyz[3];
loop_xx : for(int i=0;i<3;i++)
{
max_xyz[i] = xyzInfoAy[i].min + xyzInfoAy[i].step * xyzInfoAy[i].step_num;
}
sumdata.read(cur_sum_data);
r_cur_x.read(cur_xyz[0]);
r_cur_y.read(cur_xyz[1]);
r_cur_z.read(cur_xyz[2]);
if(cur_sum_data<minData)
{
minData = cur_sum_data;
temp_xyz[0] = cur_xyz[0];
temp_xyz[1] = cur_xyz[1];
temp_xyz[2] = cur_xyz[2];
}
if((cur_xyz[0]>=max_xyz[0]) && (cur_xyz[1]>=max_xyz[1]) && (cur_xyz[2]>=max_xyz[2]))
{
find_xyz[0] = temp_xyz[0];
find_xyz[1] = temp_xyz[1];
find_xyz[2] = temp_xyz[2];
}
}
directive指令如下,

testbench如下,
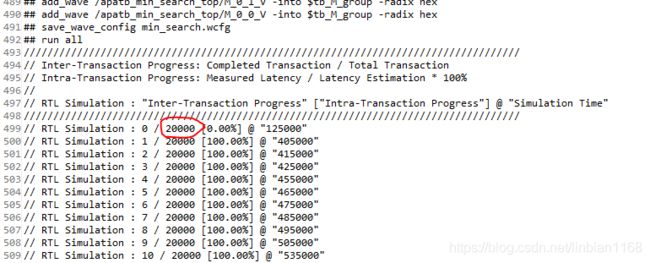
#include 在C-RTL联合仿真时,部分log记录如下,可以看到,在仿真代码中,min_search函数执行了20000次,则RTL Simulation时,也执行了20000次(不太确定:因为采用dataflow,min_search调用一次对应一个时钟周期???整个RTL仿真的运行时间和min_search调用次数有近似线性的关系)
C-RTL仿真波形如下,
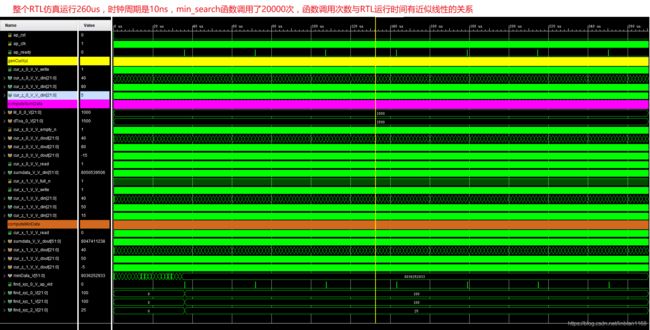
将波形图局部放大,


实现cordic,设置接口类型
下图的代码是有问题的,scalar类型不能作为输出,

采用数组或指针可以正确输出数据,各个接口类型对应的协议参见上文,

实现加法树,多种情况
目的:加法树共有4级,实现各级流水计算,延迟为4
case 1

整个函数的LATENCY设为4,PIPELINE间隔设为1,可以看到,虽然整个函数的LATENCY设置为4,但整体的计算结果还是在第一个CLK就完成了,延迟了几个CLK再输出而已,没有达到预想的每一级加法树占用一个CLK的目的
case 2
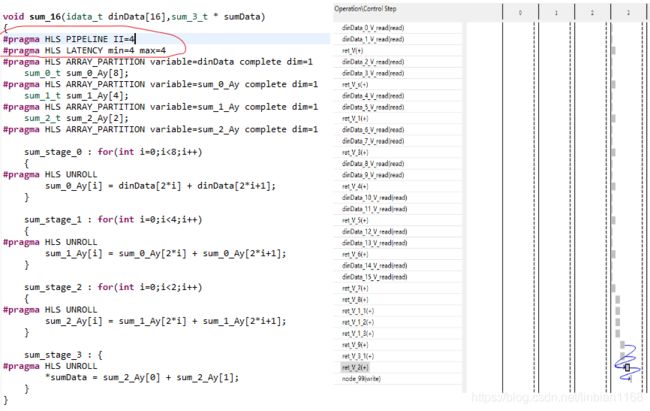
整个函数的LATENCY设为4,PIPELINE间隔设为4,可以看到,设置PIPELINE为4后,前3个CLK没有任何操作,只有第4个CLK有操作,目的没有达成
case 3
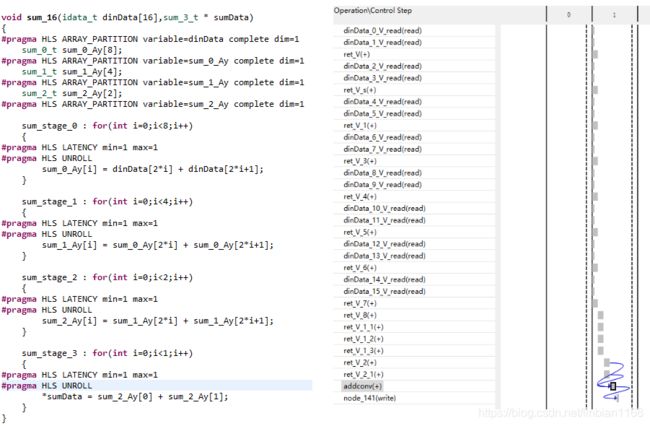
在我看来,case1和case2的代码将加法树的每一级都清楚的写好了,只要在各级之间寄存一拍后,就OK了,偏偏这个难以实现。。。在四个for循环内,设置各个循环的LATENCY为1。但是,从最终的结果看,只有一个LATENCY设置生效了,估计是因为for循环被unroll的缘故。
case4
在UG902上看到一段adder_tree的代码,综合后,并没有达到手册上说的需要多个时钟运行的效果。
case5
How to force registering the output of a module
在上述链接中看到这么一段话,“I would recommend you get away from the ideas of adder trees, multiplexers, and logic levels to some extent. That is the purpose behind Vivado HLS - to abstract out some of the details of the hardware. If you care, write RTL. Otherwise, write C and let HLS do the optimization for you”,亦即在C语言层次不要过多的涉及太底层的实现层面的事情。
这样看来的话,则上面加法树的C语言写法和HDL代码的写法其实也没什么区别,过于偏向底层了,不算好的写法。

修改C代码,使用一个for循环采用累加的方式,设置for循环unroll,计算所有数据的和。从Schedule Viewer中可以看到,HLS实际采用了加法树的方式求累加和。但是,所有的运算还是在一个CLK内完成。
case6
考虑到组合逻辑的延迟是个绝对时间,如果提高时钟频率的话,说不定上面case中,累加运算没法再一个时钟周期内完成,则加法树自然而然就会采用多个CLK了,

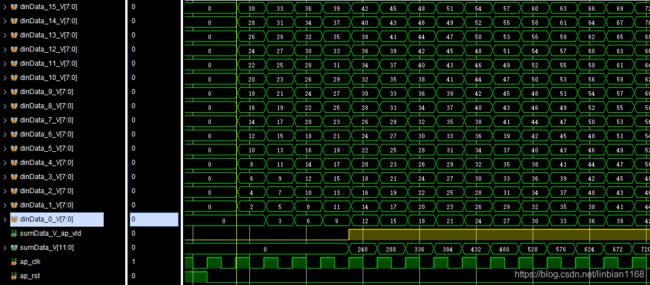
RTL仿真波形如下图,
case 7
定义了一个Reg类型,对输入数据进行寄存,之后将CLK周期设为10ns,
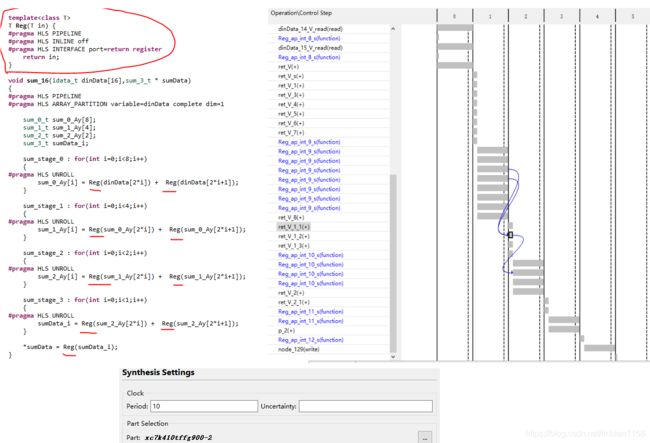
可以看到到达预定目的,RTL波形图如下

使用静态变量
注意,当一个函数包含静态变量时,该函数无法综合成一个包被多次例化的模块。
在使用dataflow时,考虑到function会被综合成module,进行了几番尝试,代码如下,
//---------------------------------------------------
#ifndef SUM_H_
#define SUM_H_
#include "stdio.h"
#include "ap_int.h"
#include "hls_stream.h"
#define TRY_2 2
#define TRY_3 3
#define TRY_TYPE TRY_2
typedef ap_int<1> s1_t;
typedef ap_int<8> s8_t;
typedef ap_uint<1> u1_t;
typedef ap_uint<8> u8_t;
typedef ap_uint<10> u10_t;
typedef u8_t cnt_t;
typedef u10_t cnt_deal_t;
typedef hls::stream<cnt_t> cnt_stream_t;
typedef hls::stream<cnt_deal_t> cnt_deal_stream_t;
void top(cnt_deal_stream_t &deal_data);
void xyz_cnt(cnt_stream_t &x_cnt_out,cnt_stream_t &y_cnt_out,cnt_stream_t &z_cnt_out);
void deal_cnt(cnt_stream_t &x_cnt_in,cnt_stream_t &y_cnt_in,cnt_stream_t &z_cnt_in,cnt_deal_stream_t &deal_out);
#endif
//---------------------------------------------------
#include "test.h"
void top(cnt_deal_stream_t &deal_data)
{
#pragma HLS DATAFLOW
static cnt_stream_t x_cnt("x_cnt_stream");
static cnt_stream_t y_cnt("y_cnt_stream");
static cnt_stream_t z_cnt("z_cnt_stream");
//函数调用
xyz_cnt(x_cnt,y_cnt,z_cnt);
deal_cnt(x_cnt,y_cnt,z_cnt,deal_data);
}
void xyz_cnt(cnt_stream_t &x_cnt_out,cnt_stream_t &y_cnt_out,cnt_stream_t &z_cnt_out)
{
#if (TRY_TYPE==TRY_2)
cnt_t x_cnt=0;
cnt_t y_cnt=0;
cnt_t z_cnt=0;
if(x_cnt<199)
{
x_cnt++;
}
else
{
x_cnt=0;
if(y_cnt<199)
{
y_cnt++;
}
else
{
y_cnt=0;
if(z_cnt<199)
{
z_cnt++;
}
else
{
z_cnt=0;
}
}
}
x_cnt_out.write(x_cnt);
y_cnt_out.write(y_cnt);
z_cnt_out.write(z_cnt);
#elif (TRY_TYPE==TRY_3)
static cnt_t x_cnt=0;
static cnt_t y_cnt=0;
static cnt_t z_cnt=0;
if(x_cnt<199)
{
x_cnt++;
}
else
{
x_cnt=0;
if(y_cnt<199)
{
y_cnt++;
}
else
{
y_cnt=0;
if(z_cnt<199)
{
z_cnt++;
}
else
{
z_cnt=0;
}
}
}
x_cnt_out.write(x_cnt);
y_cnt_out.write(y_cnt);
z_cnt_out.write(z_cnt);
#endif
}
void deal_cnt(cnt_stream_t &x_cnt_in,cnt_stream_t &y_cnt_in,cnt_stream_t &z_cnt_in,cnt_deal_stream_t &deal_out)
{
cnt_t x_cnt;
cnt_t y_cnt;
cnt_t z_cnt;
cnt_deal_t deal_data;
//数据流读取
x_cnt = x_cnt_in.read();
y_cnt = y_cnt_in.read();
z_cnt = z_cnt_in.read();
if( (x_cnt==50) && (y_cnt==50) && (z_cnt==1) )
{
deal_data = x_cnt + y_cnt + z_cnt;
//数据流写入
deal_out.write(deal_data);
}
}
//---------------------------------------------------
#include "test.h"
int main()
{
cnt_deal_stream_t deal_data;
int i;
for(i=0;i<65536;i++)
{
top(deal_data);
}
return 0;
}
当TRY_TYPE为TRY_2和TRY_3时,唯一的区别是二者对于函数中变量的声明方式不同,但二者的RTL联合仿真结果截然不同,

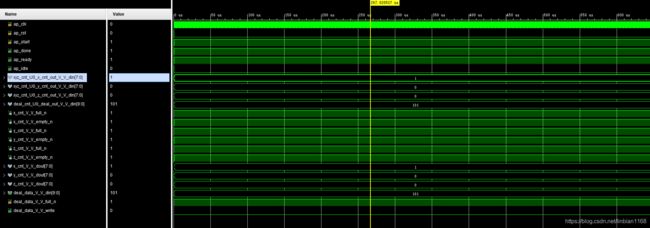

另外,此番尝试发现有如下几点要注意,
1-函数中的hls::stream在声明时需要加上static限定
2-在执行dataflow时,某个函数一旦运行完后,就会设置该函数对应的ap_idle、ap_done、ap_ready信号;某个函数在运行完之后,会继续再次执行,但函数中的变量如果不是静态变量的话,会重新进行初始化等操作;如果想让函数在多次执行过程中对某一变量持续操作,要使用static限定
3-可以为hls::stream变量额外起一个名字,便于仿真调试

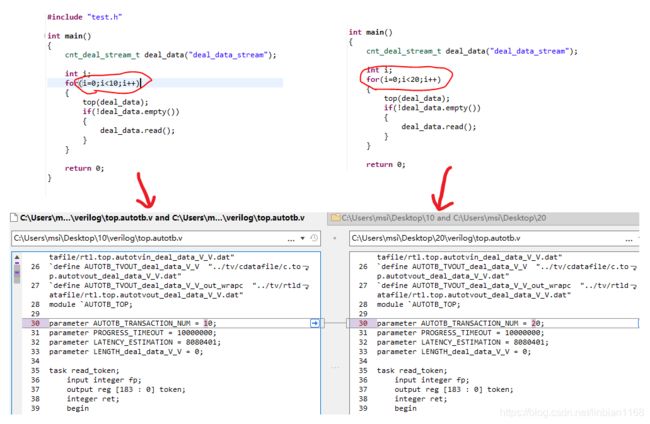
C_TB中测试次数的处理
当在C测试代码中使用循环多次调用顶层函数,并进行联合仿真时,HLS会自动生成相应的测试激励及测试数据文件。当测试循环调用次数不同时,最终生成的verilog tb文件除了AUTOTB_TRANSACTION_NUM参数之外,其他地方是相同的。

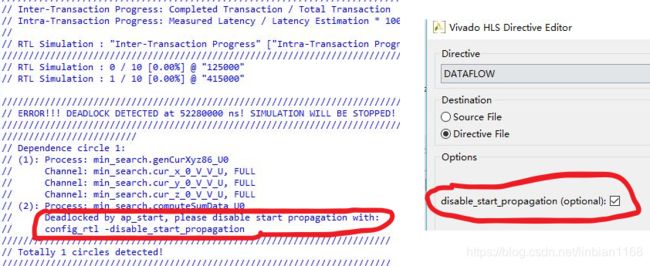
处理ERROR!!! DEADLOCK DETECTED ! SIMULATION WILL BE STOPPED!
顶层函数代码如下,

在联合仿真过程中,出现错误,提示检测到了死锁,
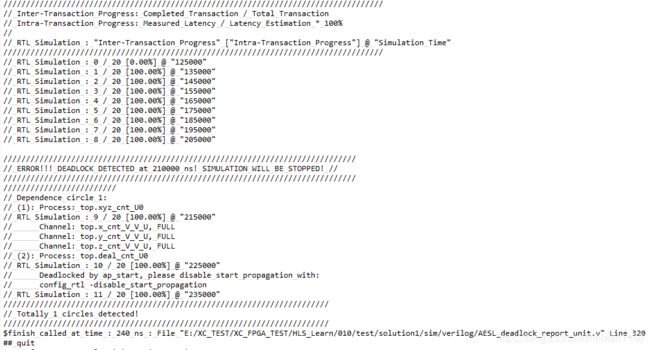
网上查找资料,有提示说fifo的深度过小可能会导致联合仿真失败,于是将fifo的深度不断加大,但一直出错,

最后观测RTL波形发现,deal_cnt模块并没有一直读取FIFO中的数据,因此无论如何加大fifo的深度,都于事无补,
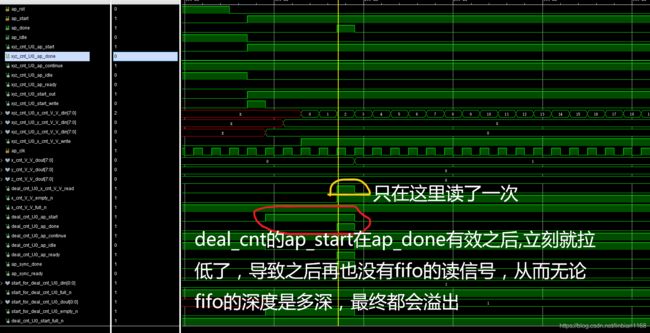
遂在dataflow设置时,禁止start_propagation,则问题解决了

使用hls_math中的函数
hls_math中的函数多使用template进行定义,在函数中进行调用时,直接向待调用函数传递相应参数即可,
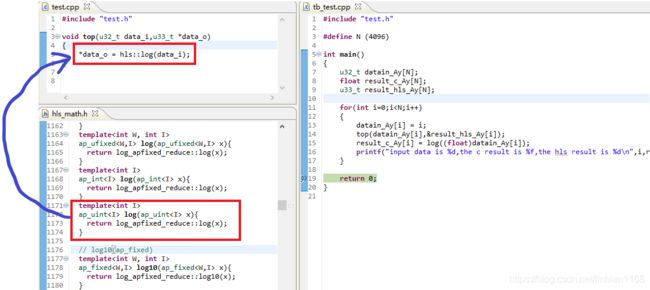
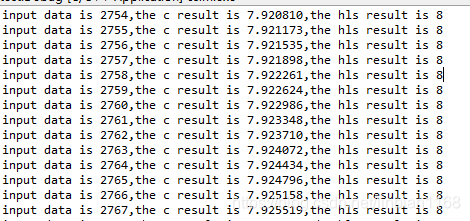
C仿真结果如下,可以看出当对uint类型数据进行log处理时,返回的结果是经过四舍五入处理的
小试复位

使用axi_lite
全部代码如下,
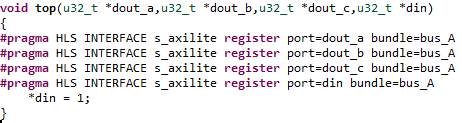
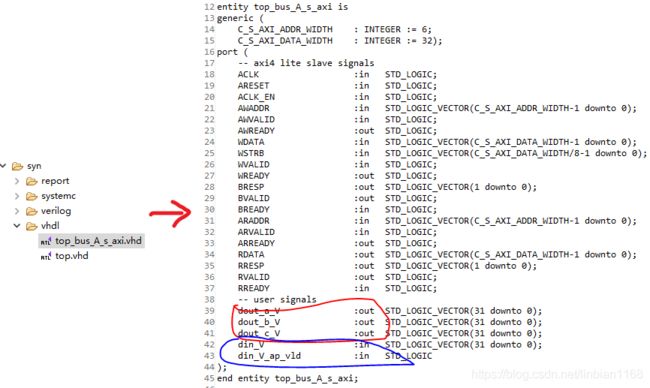
对din指针直接赋予一个常数,仅仅是为了下面生成axi_lite模块时,din能够作为输入端口而已。最终生成的模块如下,可以看到dout_a、dout_b、dout_c已经被设置为输出端口,din被设置成输入端口。
使用memcpy、使用排序
其他
1 --> Port ‘xxxx’ has no fanin or fanout and is left dangling
C综合之后,提示
WARNING: [RTGEN 206-101] Port ‘app/M0_0_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/M0_1_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/M0_2_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S1_0_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S1_1_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S1_2_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S2_0_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S2_1_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S2_2_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S3_0_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S3_1_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/S3_2_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
网上查了一下,大意是入参没有真正使用,在综合过程中被优化掉了。
考虑到这几个变量都是用于计算平方根的,而计算平方根时使用了sqrt函数,因此修改部分代码,如下
#include "hls_math.h" //想使用其中的sqrt函数
data_typeD_t getDistance(dinXYZ_t a_x,dinXYZ_t a_y,dinXYZ_t a_z,dinXYZ_t b_x,dinXYZ_t b_y,dinXYZ_t b_z)
{
data_typeB_t squareAy[3];
data_typeC_t square;
data_typeD_t sqrtResult;
squareAy[0] = (a_x-b_x)*(a_x-b_x);
squareAy[1] = (a_y-b_y)*(a_y-b_y);
squareAy[2] = (a_z-b_z)*(a_z-b_z);
square = squareAy[0] + squareAy[1] + squareAy[2];
//sqrtResult = sqrt(square);
sqrtResult = square;//测试验证使用
return sqrtResult;
}
int app(dinXYZ_t M0[3],dinXYZ_t S1[3],dinXYZ_t S2[3],dinXYZ_t S3[3],din_info_t xyzInfoAy[3])
{
...
squareAy[0][0] = (M0[0]-cur_x)*(M0[0]-cur_x);
squareAy[0][1] = (M0[1]-cur_y)*(M0[1]-cur_y);
squareAy[0][2] = (M0[2]-cur_z)*(M0[2]-cur_z);
squareSumAy[0] = squareAy[0][0] + squareAy[0][1] + squareAy[0][2];
sqrtResultAy[0] = sqrt(squareSumAy[0]);
// sqrtResultAy[0] = getDistance(M0[0],M0[1],M0[2],cur_x,cur_y,cur_z);
sqrtResultAy[1] = getDistance(S1[0],S1[1],S1[2],cur_x,cur_y,cur_z);
sqrtResultAy[2] = getDistance(S2[0],S2[1],S2[2],cur_x,cur_y,cur_z);
sqrtResultAy[3] = getDistance(S3[0],S3[1],S3[2],cur_x,cur_y,cur_z);
...
}
更改之后,仅提示
WARNING: [RTGEN 206-101] Port ‘app/M0_0_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/M0_1_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
WARNING: [RTGEN 206-101] Port ‘app/M0_2_V’ has no fanin or fanout and is left dangling.
Please use C simulation to confirm this function argument can be read from or written to.
可见的确是sqrt函数使用不当,导致这一部分逻辑被优化掉,没有实际使用,可以通过查看生产的HLD代码确认这件事。
2 --> 函数单独综合时与作为子函数综合时,综合结果不同
该函数单独综合时,返回的cur_xyz是时变的;当该函数作为一个子函数综合时,返回值不是cur_xyz,返回的是整个循环执行完后的cur_xyz的值,这点不甚理解
void getCurXyz(din_info_t info[3],data_xyz_t *cur_xyz)
{
loop_x : for(cur_xyz->xyz[0]=info[0].min;cur_xyz->xyz[0]<info[0].max;cur_xyz->xyz[0]=cur_xyz->xyz[0]+info[0].step)
{
loop_y : for(cur_xyz->xyz[1]=info[1].min;cur_xyz->xyz[1]<info[1].max;cur_xyz->xyz[1]=cur_xyz->xyz[1]+info[1].step)
{
loop_z : for(cur_xyz->xyz[2]=info[2].min;cur_xyz->xyz[2]<info[2].max;cur_xyz->xyz[2]=cur_xyz->xyz[2]+info[2].step)
{
;
}
}
}
}
论文
官网
AR
AR60236
AR57876
AR61063

AR5169

论坛
Two processes running at the same time
SDK C program for 4-bit counter: Vivado HLS
关于HLS 循环并行优化问题(中文帖子,写的很好)
C/RTL Co-Simulation freezes (Not support hls::stream?)
求助vivado HLS协同仿真deadlock问题
Vivado HLS中指针作为top函数参数的处理
HLS: Efficiently apply RESOURCE constraints to expressions
Pragma about FMul_fulldsp and FAddSub_fulldsp
WARNING: Estimated clock period exceeds the target
AddSub_DSP