安装行为驱动模块lettuce(卷心菜)模块
pip install lettuce
Successfully installed argparse-1.4.0 colorama-0.3.9 extras-1.0.0 fixtures-3.0.0 funcsigs-1.0.2 fuzzywuzzy-0.16.0 lettuce-0.2.23 linecache2-1.0.0 mock-2.0.0 pbr-4.1.0 python-mimeparse-1.6.0 python-subunit-1.3.0 sure-1.4.11 testtools-2.3.0 traceback2-1.4.0 unittest2-1.1.0
官网:http://lettuce.it
下面通过第一个例子来说明行为驱动是做什么的。
第一个例子,解释行为驱动的用法和结构,用的是方法
建一个目录(名称随意),在该目录下新建features目录,在features目录下,建两个文件steps.py和zero.feature
features目录名称是固定的 feature文件的后缀名必须是xxx.feature,也是固定的。
features和features下这两个文件就是行为驱动lettuce的结构,一个是文本文件,用来定义用例是什么,另一个是真正执行用例步骤的脚本
可以对比一下zero.feature里用例的三个关键字语句和steps的三个函数的映射关系,就是一一对应的,一个语句对应一个函数,这就是行为驱动的结构。
总结一下行为驱动:
行为驱动就是通过feature文件里关键字对应的自然语言映射脚本中对应的函数,然后执行steps脚本来执行feature中描述的测试用例。
每一句自然语言的描述都会有一个函数或步骤执行跟它对应,这么做的意义是在执行用例的时候可以看到他在干什么,看他完成了多少需求,因为自然语言中描述的都是需求中定义的东西,行为驱动一般定义在敏捷开发当中,敏捷开发中有数据驱动、行为驱动、验收测试驱动,这就是行为驱动,好处是可以验证需求是否都完成了,可以在开发完成后执行行为驱动用例,把完成的需求按自然语言方式输出出来,都输出了就说明完成了,就是把测试用例和自然语言的需求之间建立一个联系,当他执行通过之后,我就知道我的需求完成了多少,就是做了一个映射的关系,这样需求人员就知道原来我的进度是这样,在写测试用例的时候,需求人员自己就可以写了,把不同的场景写出来就可以了,不用管测试用例的实现,最后执行的时候就知道需求完成了多少,因为只要测试用例跑通过了就认为是成功了,这就是行为驱动的好处,方便非测试、非技术人员对需求进度的了解。
本质就是把自然语言跟你的测试步骤做了一一对应,以此来看进度的完成情况,以及是否通过测试,一般认为通过测试的才认为开发算完成了,在敏捷测试中用的比较多,在一般正常的非敏捷的测试中用的不多。
可以在githun上找源码看一下lettuce怎么实现的。
如何执行测试用例:
到features目录的上层目录中,打开cmd,执行lettuce
绿色代表执行通过,有问题的话会报错。
zero.feature:
#说明功能是干什么的,用的时候把注释都去掉,防止受影响
#Feature,Scenario,Given,When,Then等第一个字母大写的,这些都是关键字,不能变
Feature: Compute factorial#计算阶乘
#备注,描述说明
In order to play with Lettuce
As beginners
We'll implement factorial
#场景1,就是第一个测试用例
Scenario: Factorial of 0#0的阶乘
#下面这三个自然语言的描述都有一个函数跟它对应,执行测试用例的时候可以看他干了什么
#是否正确的执行
#敏捷里也有验收测试驱动,行为驱动,数据驱动
#把测试用例用自然语言的描述和程序有一个映射
Given I have the number 0#如果我有一个数是0
When I compute its factorial#当我计算这个阶乘的时候
Then I see the number 1#计算完了之后,我得到的结果0的阶乘是1
#下面以此类推,原理都是一样的
Scenario: Factorial of 1
Given I have the number 1
When I compute its factorial
Then I see the number 1
Scenario: Factorial of 2
Given I have the number 2
When I compute its factorial
Then I see the number 2
Scenario: Factorial of 3
Given I have the number 3
When I compute its factorial
Then I see the number 6
steps.py:定义方法,实现测试用例
#encoding=utf-8
from lettuce import *
# 用于计算整数的阶乘函数
def factorial(number):#被测试对象,告诉怎么计算阶乘的
number = int(number)
if (number == 0) or (number == 1):
return 1
else:
return reduce(lambda x, y: x * y, range(1, number + 1))#算阶乘的方法,后续自己演练#一下
#可以对比一下zero.feature里用例的三个关键字语句和下面的三个函数的映射关系,就是一#一对应的,一个语句对应一个函数,这就是行为驱动
#下面的@是装饰器的用法,括号里是给装饰器穿的参数
@step('I have the number (\d+)')#跟feature里的Given所指的一样
def have_the_number(step, number):
# 将通过正则表达式匹配的数字存于全局变量world中
# world是lettuce里的命名空间,这命名空间里的所有变量在所有lettuce方法中共用,类似全局变量
#做了一个类型转换
world.number = int(number)#world是lettuce里的命名空间,这空间里的所有变量在所有lettuce里公用
@step('I compute its factorial')#同步features文件,然后用正则
def compute_its_factorial(step):
# 从全局变量world中取出匹配的数字,
# 计算其阶乘,并将结果再存回world中
world.number = factorial(world.number)#把world.number传给函数,返回后又传给自己了
@step('I see the number (\d+)')
def check_number(step, expected):#step对应I see the number ,expected对应分组(\d+)
# 通过正则匹配到预期数字
expected = int(expected)#把字符串转成整形
# 断言计算阶乘结果是否等于预期
assert world.number == expected, "Got %d" %world.number
测试用例的执行:
到features目录的上层目录中,打开cmd,执行lettuce
绿色代表执行通过,有问题的话会报错。
结果:
D:\test\xingweiqudong\practice1>lettuce
c:\python27\lib\site-packages\fuzzywuzzy\fuzz.py:35: UserWarning: Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning
warnings.warn('Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning')
Feature: Compute factorial # \features\zero.feature:1
In order to play with Lettuce # \features\zero.feature:2
As beginners # \features\zero.feature:3
We'll implement factorial # \features\zero.feature:4
Scenario: Factorial of 0 # \features\zero.feature:6
Given I have the number 0 # \features\steps.py:13
When I compute its factorial # \features\steps.py:18
Then I see the number 1 # \features\steps.py:24
Scenario: Factorial of 1 # \features\zero.feature:11
Given I have the number 1 # \features\steps.py:13
When I compute its factorial # \features\steps.py:18
Then I see the number 1 # \features\steps.py:24
Scenario: Factorial of 2 # \features\zero.feature:16
Given I have the number 2 # \features\steps.py:13
When I compute its factorial # \features\steps.py:18
Then I see the number 2 # \features\steps.py:24
Scenario: Factorial of 3 # \features\zero.feature:21
Given I have the number 3 # \features\steps.py:13
When I compute its factorial # \features\steps.py:18
Then I see the number 6 # \features\steps.py:24
1 feature (1 passed)
4 scenarios (4 passed)
12 steps (12 passed)

第二个例子:用类的方式实现
features没有变化和第一个例子一样,steps文件有变化,用类的方式实现
方法就是在类的上边用装饰器@steps来实现
steps.py:
#encoding=utf-8
from lettuce import world, steps
def factorial(number):
number = int(number)
if (number == 0) or (number == 1):
return 1
else:
return reduce(lambda x, y: x * y, range(1, number + 1))
@steps#装饰器,测试步骤类,他的每个方法默认都是一个测试步骤
class FactorialSteps(object):
"""Methods in exclude or starting with _ will not be considered as step"""
exclude = ['set_number', 'get_number']#不作为测试步骤,因为@steps测试步骤类里的方#法都作为测试步骤,所以在这里做一个排除
def __init__(self, environs):
# 初始全局变量
self.environs = environs#实例化后就是一个world,存全局共享变量的对象
def set_number(self, value):#不是步骤
# 设置全局变量中的number变量的值
#设定测试数据
self.environs.number = int(value)#就是world存到了这个实例变量里
def get_number(self):#不是步骤
# 从全局变量中取出number的值
return self.environs.number#取出测试数据
#私有方法默认也不是测试步骤
def _assert_number_is(self, expected, msg="Got %d"):
number = self.get_number()
# 断言取出的数据和期望的数据是否一致
assert number == expected, msg % number
#下边三个都是测试步骤
def have_the_number(self, step, number):
#下边跟自然语言描述是一样的,三句话
'''I have the number (\d+)'''#从feature文件里取出的自然语言的内容
# 上面的三引号引起的代码必须写,并且必须是三引号引起
# 表示从场景步骤中获取需要的数据
# 并将获得数据存到环境变量number中
self.set_number(number)#获取一下测试数据
def i_compute_its_factorial(self, step):
"""When I compute its factorial"""
number = self.get_number()#取出数据
# 调用factorial方法进行阶乘结算,
# 并将结算结果存于全局变量中的number中
self.set_number(factorial(number))#通过测试数据调用被测试方法
def check_number(self, step, expected):
'''I see the number (\d+)'''
# 上面的三引号引起的代码必须写,并且必须是三引号引起
# 表示从场景步骤中获取需要的数据以便断言测试结果
self._assert_number_is(int(expected))#私有方法做一个断言
FactorialSteps(world)#测试类的实例化,world是一个类,lettuce里可以存全局共享变量的对象
Zero.eature:
Feature: Compute factorial
In order to play with Lettuce
As beginners
We'll implement factorial
Scenario: Factorial of 0
Given I have the number 0
When I compute its factorial
Then I see the number 1
Scenario: Factorial of 1
Given I have the number 1
When I compute its factorial
Then I see the number 1
Scenario: Factorial of 2
Given I have the number 2
When I compute its factorial
Then I see the number 2
Scenario: Factorial of 3
Given I have the number 3
When I compute its factorial
Then I see the number 6
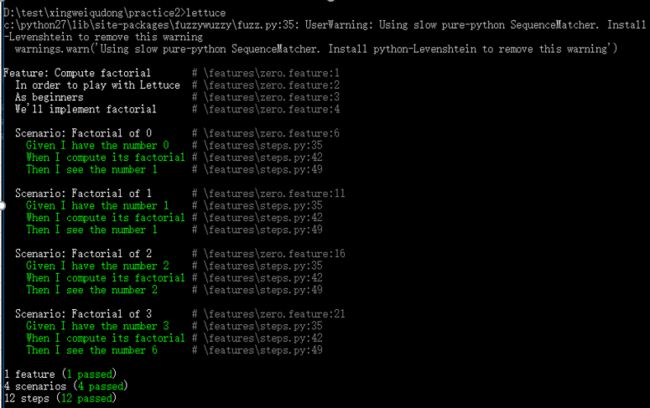
结果:
D:\test\xingweiqudong\practice2>lettuce
c:\python27\lib\site-packages\fuzzywuzzy\fuzz.py:35: UserWarning: Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning
warnings.warn('Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning')
Feature: Compute factorial # \features\zero.feature:1
In order to play with Lettuce # \features\zero.feature:2
As beginners # \features\zero.feature:3
We'll implement factorial # \features\zero.feature:4
Scenario: Factorial of 0 # \features\zero.feature:6
Given I have the number 0 # \features\steps.py:35
When I compute its factorial # \features\steps.py:42
Then I see the number 1 # \features\steps.py:49
Scenario: Factorial of 1 # \features\zero.feature:11
Given I have the number 1 # \features\steps.py:35
When I compute its factorial # \features\steps.py:42
Then I see the number 1 # \features\steps.py:49
Scenario: Factorial of 2 # \features\zero.feature:16
Given I have the number 2 # \features\steps.py:35
When I compute its factorial # \features\steps.py:42
Then I see the number 2 # \features\steps.py:49
Scenario: Factorial of 3 # \features\zero.feature:21
Given I have the number 3 # \features\steps.py:35
When I compute its factorial # \features\steps.py:42
Then I see the number 6 # \features\steps.py:49
1 feature (1 passed)
4 scenarios (4 passed)
12 steps (12 passed)
第三个例子:用表格的模式
用表格的模式,用多行数据的时候会用到
核心的原理:表格里的数据是
Student.feature:多了个and关键字
Feature: bill students alphabetically#基于字母来付款
In order to bill students properly
As a financial specialist
I want to bill those which name starts with some letter
Scenario: Bill students which name starts with "G"
#数据表,不同字母开头,付的钱不一样
Given I have the following students in my database:
| name | monthly_due | billed |
| Anton | $ 500 | no |
| Jack | $ 400 | no |
| Gabriel | $ 300 | no |
| Gloria | $ 442.65 | no |
| Ken | $ 907.86 | no |
| Leonard | $ 742.84 | no |
#只想让以G开头的人付款
When I bill names starting with "G"#当我打了一个G
Then I see those billed students:#看到这些人,以G开头的
| name | monthly_due | billed |
| Gabriel | $ 300 | no |
| Gloria | $ 442.65 | no |
And those that weren't:#且不看到这些人(非G开头)的信息
| name | monthly_due | billed |
| Anton | $ 500 | no |
| Jack | $ 400 | no |
| Ken | $ 907.86 | no |
| Leonard | $ 742.84 | no |
step.py:
#encoding=utf-8
from lettuce import *
@step('I have the following students in my database:')#以函数的方式实现的
def students_in_database(step):
if step.hashes:#feature的数据表的内容给读出来
# 如果存在步骤表格数据,则继续后续步骤
print type(step.hashes)
assert step.hashes == [#断言是否和数据表对应,每个{}里的内容和数据表的一行数据对应
{
#每行的数据,表头加值
'name': 'Anton',#每行的数据是一个字典
'monthly_due': '$ 500',
'billed': 'no'
},
{
'name': 'Jack',
'monthly_due': '$ 400',
'billed': 'no'
},
{
'name': 'Gabriel',
'monthly_due': '$ 300',
'billed': 'no'
},
{
'name': 'Gloria',
'monthly_due': '$ 442.65',
'billed': 'no'
},
{
'name': 'Ken',
'monthly_due': '$ 907.86',
'billed': 'no'
},
{
'name': 'Leonard',
'monthly_due': '$ 742.84',
'billed': 'no'
},
]
@step('I bill names starting with "(.*)"')#敲了一个东西,正则.*代表除回车外的任意字符
def match_starting(step, startAlpha):
# 将通过正则表达式匹配步骤中最后一个字母,
# 并存于全局变量startAlpha中
world.startAlpha = startAlpha#给全局变量
#打印了一下取出来的东西,'feature里bill names starting with部分没哈希表
print "no data exist:",step.hashes
@step('I see those billed students:')#要看到需要付款的人,有哈希表
def get_starting_with_G_student(step):
# 遍历步骤数据表中的数据
for i in step.hashes:#遍历哈希表
# 断言学生的名字是否以world.startAlpha变量存取的的字母开头
assert i["name"].startswith(world.startAlpha)#断言每个人的名字是否是以刚才敲的字符开头的
@step("those that weren't:")
def result(step):
for j in step.hashes:#就是feature里those that weren’t部分的数据表/哈希表
# 断言学生名字不以world.startAlpha变量存取的的字母开头
assert world.startAlpha not in j["name"][0]#断言表里每个名字的首字母不是G
结果:
D:\test\xingweiqudong\practice3>lettuce
Feature: bill students alphabetically # \features\student.feature:1
In order to bill students properly # \features\student.feature:2
As a financial specialist # \features\student.feature:3
I want to bill those which name starts with some letter # \features\student.feature:4
Scenario: Bill students which name starts with "G" # \features\student.feature:6
Given I have the following students in my database: # \features\step.py:5
Given I have the following students in my database: # \features\step.py:5
| name | monthly_due | billed |
| Anton | $ 500 | no |
| Jack | $ 400 | no |
| Gabriel | $ 300 | no |
| Gloria | $ 442.65 | no |
| Ken | $ 907.86 | no |
| Leonard | $ 742.84 | no |
When I bill names starting with "G" # \features\step.py:43
When I bill names starting with "G" # \features\step.py:43
Then I see those billed students: # \features\step.py:50
| name | monthly_due | billed |
| Gabriel | $ 300 | no |
| Gloria | $ 442.65 | no |
And those that weren't: # \features\step.py:57
| name | monthly_due | billed |
| Anton | $ 500 | no |
| Jack | $ 400 | no |
| Ken | $ 907.86 | no |
| Leonard | $ 742.84 | no |
1 feature (1 passed)
1 scenario (1 passed)
4 steps (4 passed)

py -3 m pip install lettuce python 3,运行python3
virtual env 虚拟环境,生成独立的沙盒,跟虚拟机一样,生成了一个虚拟的python运行环境
帖子:linux下的
https://blog.csdn.net/u012734441/article/details/55044025/
pycharm里新建项目时,选virtualEnv,安装的python编译环境跟操作系统就完全独立的
window下
https://www.cnblogs.com/ruhai/p/6597280.html
第四个例子,基于webdriver,数据驱动的例子
sogou.feature:
Feature: Search in Sogou website
In order to Search in Sogou website
As a visitor
We'll search the NBA best player
Scenario: Search NBA player
Given I have the english name "
When I search it in Sogou website
Then I see the entire name "
Examples:
| search_name | search_result |
| Jordan | Michael |
| Curry | Stephen |
| Kobe | Bryant |
自然语言和测试步骤函数的映射关系,一一对应,方便非测试、非技术人员对需求进度的了解
Examples是关键字
sougou.py:
#encoding=utf-8
from lettuce import *
from selenium import webdriver
import time
@step('I have the english name "(.*)"')
def have_the_searchWord(step, searchWord):
world.searchWord = str(searchWord)
print world.searchWord
@step('I search it in Sogou website')
def search_in_sogou_website(step):
world.driver = webdriver.Firefox(executable_path = "c:\\geckodriver")
world.driver.get("http://www.sogou.com")
world.driver.find_element_by_id("query").send_keys(world.searchWord)#上个方法获取的数据
world.driver.find_element_by_id("stb").click()
time.sleep(3)
@step('I see the entire name "(.*)"')
def check_result_in_sogou(step, searchResult):
assert searchResult in world.driver.page_source, "got word:%s" %searchResult
world.driver.quit()
terrain.py:
#本质是在用例开始的前、后,每个场景之前、后,每个步骤开始之前、后做一些事情
#跟testNG的标签差不多,就是一个框架
#encoding=utf-8
from lettuce import *
import logging
# 初始化日志对象
logging.basicConfig(
# 日志级别
level = logging.INFO,
# 日志格式
# 时间、代码所在文件名、代码行号、日志级别名字、日志信息
format = '%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
# 打印日志的时间
datefmt = '%a, %Y-%m-%d %H:%M:%S',
# 日志文件存放的目录(目录必须存在)及日志文件名
filename = 'e:/BddDataDriveRreport.log',
# 打开日志文件的方式
filemode = 'w'
)
# 在所有场景执行前执行,只会执行一次
@before.all
def say_hello():
logging.info("Lettuce will start to run tests right now...")
print "Lettuce will start to run tests right now..."
# 在每个secnario开始执行前执行
@before.each_scenario
def setup_some_scenario(scenario):
# 每个Scenario开始前,打印场景的名字
print 'Begin to execute scenario name:' + scenario.name
# 将开始执行的场景信息打印到日志
logging.info('Begin to execute scenario name:' + scenario.name)
# 每个step开始前执行,每执行一步就打印一次
@before.each_step#固定写法
def setup_some_step(step):
run = "running step %r, defined at %s" % (
step.sentence, # 执行的步骤
step.defined_at.file # 步骤定义在哪个文件
)
# 将每个场景的每一步信息打印到日志
logging.info(run)
# 每个step执行后执行
@after.each_step
def teardown_some_step(step):
if not step.hashes:#判断是否没有表格文件
print "no tables in the step" #会被打印9次,因为我们仅仅设定了场景的table,而不是给每个步骤设定table
#注意每个step可以有自己的table,等价于把table的数据作为一个字典传入到程序中使用。
logging.info("no tables in the step")#打印没有table
# 在每个secnario执行结束执行,每一个场景结束后打印
@after.each_scenario
def teardown_some_scenario(scenario):
print 'finished, scenario name:' + scenario.name
logging.info('finished, scenario name:' + scenario.name)
# 在所有场景开始执行后执行
@after.all #默认获取执行结果的对象作为total参数
def say_goodbye(total):
result = "Congratulations, %d of %d scenarios passed!" % (
total.scenarios_ran, #一共多少场景运行了
total.scenarios_passed #一共多少场景运行成功了
)
print result
logging.info(result)
# 将测试结果写入日志文件
logging.info("Goodbye!")
print "------ Goodbye! ------"
结果:
D:\test\xingweiqudong\practice4>lettuce
Lettuce will start to run tests right now...
Lettuce will start to run tests right now...
Feature: Search in Sogou website # \features\sogou.feature:1
In order to Search in Sogou website # \features\sogou.feature:2
As a visitor # \features\sogou.feature:3
We'll search the NBA best player # \features\sogou.feature:4
Begin to execute scenario name:Search NBA player
Scenario Outline: Search NBA player # \features\sogou.feature:6
Begin to execute scenario name:Search NBA player
Given I have the english name "
Jordan
no tables in the step
no tables in the step
When I search it in Sogou website # \features\sogou.py:12
no tables in the step
no tables in the step
Then I see the entire name "
no tables in the step
no tables in the step
Examples:
| search_name | search_result |
| Jordan | Michael |
Curry
no tables in the step
no tables in the step
no tables in the step
no tables in the step
no tables in the step
no tables in the step
| Curry | Stephen |
Kobe
no tables in the step
no tables in the step
no tables in the step
no tables in the step
no tables in the step
no tables in the step
| Kobe | Bryant |
finished, scenario name:Search NBA player
finished, scenario name:Search NBA player
Congratulations, 3 of 3 scenarios passed!
------ Goodbye! ------
1 feature (1 passed)
3 scenarios (3 passed)
9 steps (9 passed)
Congratulations, 3 of 3 scenarios passed!
------ Goodbye! ------

第五个例子:feature里用中文#language:zh-CN
涉及中文,要改个东西,colored_shell_output.py里encode('utf-8')注释掉
在默认编码为GBK的Windows系统中执行场景使用中文描述的行为驱动测试时,打印到控制台的场景等信息,中文会出现乱码,这是由于lettuce框架将输出到控制台的场景描述信息转成UTF8编码的字符导致的。下面针对lettuce(0.2.23)版本给出具体解决方法。
(1)进入Python安装目录中lettuce安装路径中的plugins目录中,比如本地路径为C:\Python27\Lib\site-packages\lettuce\plugins。
(2)找到该目录下的colored_shell_output.py文件,
(3)打开该文件,找到该文件的第32行代码what = what.encode('utf-8'),将其改成what = what#.encode('utf-8')
Baidu.feature:
#encoding=utf-8
# language: zh-CN
特性: 在百度网址搜索IT相关书籍
能够搜索到书的作者,比如吴晓华
场景: 在百度网站搜索IT相关书籍
如果将搜索词设定为书的名字"<书名>"
当打开百度网站
和在搜索输入框中输入搜索的关键词,并点击搜索按钮后
那么在搜索结果中可以看到书的作者"<作者>"
例如:
| 书名 | 作者 |
| Selenium WebDriver实战宝典 | 吴晓华 |
| HTTP权威指南 | 协议 |
| Python核心编程 | Python |
log.py:写了个配置
#encoding=utf-8
import logging
# 初始化日志对象
logging.basicConfig(
# 日志级别
level = logging.INFO,
# 日志格式
# 时间、代码所在文件名、代码行号、日志级别名字、日志信息
format = '%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
# 打印日志的时间
datefmt = '%a, %Y-%m-%d %H:%M:%S',
# 日志文件存放的目录(目录必须存在)及日志文件名
filename = 'e:/BddDataDriveRreport.log',
# 打开日志文件的方式
filemode = 'w'
)
terranin.py内容跟上个例子一样
#encoding=utf-8
from lettuce import *
from log import *
# 在所有场景执行前执行
@before.all
def say_hello():
logging.info(u"开始执行行为数据驱动测试...")
# 在每个secnario开始执行前执行
@before.each_scenario
def setup_some_scenario(scenario):
# 将开始执行的场景信息打印到日志
logging.info(u'开始执行场景“%s”' %scenario.name)
# 每个step开始前执行
@before.each_step
def setup_some_step(step):
world.stepName = step.sentence
run = u"执行步骤“%s”, 定义在“%s”文件" % (
step.sentence, # 执行的步骤
step.defined_at.file # 步骤定义在哪个文件
)
# 将每个场景的每一步信息打印到日志
logging.info(run)
# 每个step执行后执行
@after.each_step
def teardown_some_step(step):
logging.info(u"步骤“%s”执行结束" % world.stepName)
# 在每个secnario执行结束执行
@after.each_scenario
def teardown_some_scenario(scenario):
logging.info(u'场景“%s”执行结束' %scenario.name)
# 在所有场景开始执行后执行
@after.all #默认获取执行结果的对象作为total参数
def say_goodbye(total):
result = u"恭喜,%d个场景运行,%d个场景运行成功" % (
total.scenarios_ran, #一共多少场景运行了
total.scenarios_passed #一共多少场景运行成功了
)
logging.info(result)
# 将测试结果写入日志文件
logging.info(u"本次行为数据驱动执行结束")
baidu.py:
把装饰器里传的内容改成中文,其他没变化
#encoding=utf-8
# language: zh-CN
from lettuce import *
from selenium import webdriver
import time
@step(u'将搜索词设定为书的名字"(.*)"')
def have_the_searchWord(step, searchWord):
world.searchWord = searchWord
print world.searchWord
@step(u'打开百度网站')
def visit_baidu_website(step):
world.driver = webdriver.Firefox(executable_path = "c:\\geckodriver ")
world.driver.get("http://www.baidu.com")
@step(u'在搜索输入框中输入搜索的关键词,并点击搜索按钮后')
def search_in_sogou_website(step):
world.driver.find_element_by_id("kw").send_keys(world.searchWord)
world.driver.find_element_by_id("su").click()
time.sleep(3)
@step(u'在搜索结果中可以看到书的作者"(.*)"')
def check_result_in_sogou(step, searchResult):
assert searchResult in world.driver.page_source, "got word:%s" %searchResult
world.driver.quit()
结果:
D:\test\xingweiqudong\practice5>lettuce
特性: 在百度网址搜索IT相关书籍 # \features\baidu.feature:4
能够搜索到书的作者,比如吴晓华 # \features\baidu.feature:5
场景模板: 在百度网站搜索IT相关书籍 # \features\baidu.feature:7
如果将搜索词设定为书的名字"<书名>" # \features\baidu.py:8
Selenium WebDriver实战宝典
当打开百度网站 # \features\baidu.py:13
和在搜索输入框中输入搜索的关键词,并点击搜索按钮后 # \features\baidu.py:18
那么在搜索结果中可以看到书的作者"<作者>" # \features\baidu.py:24
例如:
| 书名 | 作者 |
| Selenium WebDriver实战宝典 | 吴晓华 |
HTTP权威指南
| HTTP权威指南 | 协议 |
Python核心编程
| Python核心编程 | Python |
1 feature (1 passed)
3 scenarios (3 passed)
12 steps (12 passed)

第六个例子:批量执行
把多个feature和脚本文件放在一个目录下,lettuce会自动的匹配feature的东西,一个一个的执行
Login_Chinese.feature:
#encoding=utf-8
# language: zh-CN
特性: 登录126邮箱和退出126邮箱登录
场景: 成功登录126邮箱
假如启动一个浏览器
当用户访问http://mail.126.com网址
当用户输入输入用户名“testman1980”和密码“wulaoshi1978”
那么页面会出现“未读邮件”关键字
场景: 成功退出126邮箱
当用户从页面单击退出链接
那么页面显示“您已成功退出网易邮箱”关键内容
Login_English.feature:
#encoding=utf-8
Feature: login and logout
Scenario: Successful Login with Valid Credentials
Given Launch a browser
When User visit to http://mail.126.com Page
And User enters UserName"testman1980" and Password"wulaoshi1978"
Then Message displayed Login Successfully
Scenario: Successful LogOut
When User LogOut from the Application
Then Message displayed LogOut Successfully
Login_Chinese.py:
#encoding=utf-8
# language: zh-CN
from lettuce import *
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
@step(u'启动一个浏览器')
def open_browser(step):
try:
# 创建Chrome浏览器的driver实例,并存于全局对象world中,
# 供后续场景或步骤函数使用
world.driver = webdriver.Firefox(executable_path="c:\\geckodriver")
except Exception, e:
raise e
@step(u'用户访问(.*)网址')
def visit_url(step, url):
print url
world.driver.get(url)
@step(u'用户输入输入用户名“(.*)”和密码“(.*)”')
def user_enters_UserName_and_Password(step, username, password):
print username, password
# 浏览器窗口最大化
world.driver.maximize_window()
time.sleep(3)
# 切换进frame控件
world.driver.switch_to.frame("x-URS-iframe")
# 获取用户名输入框
userName = world.driver.find_element_by_xpath('//input[@name="email"]')
userName.clear()
# 输入用户名
userName.send_keys(username)
# 获取密码输入框
pwd = world.driver.find_element_by_xpath("//input[@name='password']")
# 输入密码
pwd.send_keys(password)
# 发送一个回车键
pwd.send_keys(Keys.RETURN)
# 等待15秒,以便登录后成功进入登录后的页面
time.sleep(15)
@step(u'页面会出现“(.*)”关键字')
def message_displayed_Login_Successfully(step, keywords):
# print world.driver.page_source.encode('utf-8')
# 断言登录成功后,页面是否出现预期的关键字
world.driver.switch_to.default_content()#自己加的
assert keywords in world.driver.page_source
# 断言成功后,打印登录成功信息
print "Login Success"
@step(u'用户从页面单击退出链接')
def LogOut_from_the_Application(step):
print "====",world.driver
# time.sleep(5)
world.driver.switch_to.default_content()#自己加的
# 点击退出按钮,退出登录
world.driver.find_element_by_link_text(u"退出").click()
time.sleep(8)
@step(u'页面显示“(.*)”关键内容')
def displayed_LogOut_Successfully(step, keywords):
# 断言退出登录后,页面是否出现退出成功关键内容
assert keywords in world.driver.page_source
print u"Logout Success"
# 退出浏览器
world.driver.quit()
Login_English.py:
#encoding=utf-8
from lettuce import *
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
@step('Launch a browser')
def open_browser(step):
try:
world.driver = webdriver.Firefox(executable_path="c:\\geckodriver")
except Exception, e:
raise e
@step('User visit to (.*) Page')
def visit_url(step, url):
world.driver.get(url)
@step('User enters UserName"(.*)" and Password"(.*)"')
def user_enters_UserName_and_Password(step, username, password):
world.driver.maximize_window()
time.sleep(3)
world.driver.switch_to.frame("x-URS-iframe")
userName = world.driver.find_element_by_xpath('//input[@name="email"]')
userName.clear()
userName.send_keys(username)
pwd = world.driver.find_element_by_xpath("//input[@name='password']")
pwd.send_keys(password)
pwd.send_keys(Keys.RETURN)
time.sleep(15)
@step('Message displayed Login Successfully')
def message_displayed_Login_Successfully(step):
# print world.driver.page_source.encode('utf-8')
world.driver.switch_to.default_content()#自己加的
assert u"未读邮件" in world.driver.page_source
print "Login Success"
@step('User LogOut from the Application')
def LogOut_from_the_Application(step):
print "====",world.driver
# time.sleep(15)
world.driver.switch_to.default_content()#自己加的
world.driver.find_element_by_link_text(u"退出").click()
time.sleep(4)
@step('Message displayed LogOut Successfully')
def displayed_LogOut_Successfully(step):
assert u"您已成功退出网易邮箱" in world.driver.page_source
print u"Logout Success"
world.driver.quit()
terrain.py:
#encoding=utf-8
from lettuce import *
# 在所有场景执行前执行
@before.all
def say_hello():
print u"开始执行行为数据驱动测试..."
# 在每个secnario开始执行前执行
@before.each_scenario
def setup_some_scenario(scenario):
print u'开始执行场景“%s”' %scenario.name
# 在每个secnario执行结束后执行
@after.each_scenario
def teardown_some_scenario(scenario):
print u'场景“%s”执行结束' %scenario.name
# 在所有场景执行结束后执行
@after.all #默认获取执行结果的对象作为total参数
def say_goodbye(total):
result = u"恭喜,%d个场景被运行,%d个场景运行成功" % (
total.scenarios_ran, #一共多少场景运行了
total.scenarios_passed #一共多少场景运行成功了
)
print result
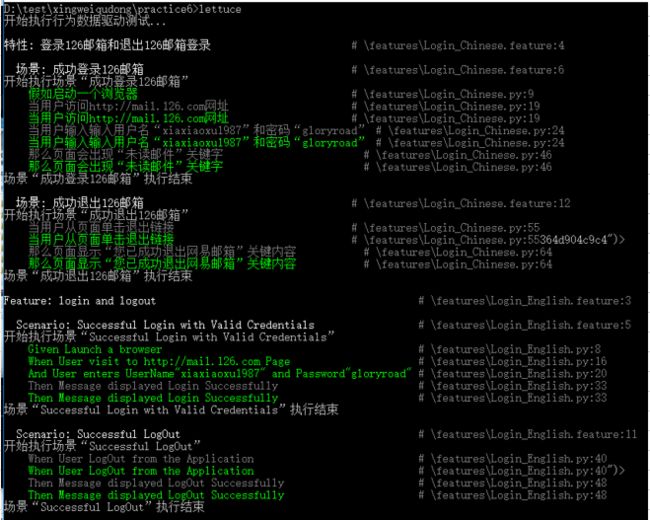
结果:
D:\test\xingweiqudong\practice6>lettuce
开始执行行为数据驱动测试...
特性: 登录126邮箱和退出126邮箱登录 # \features\Login_Chinese.feature:4
场景: 成功登录126邮箱 # \features\Login_Chinese.feature:6
开始执行场景“成功登录126邮箱”
假如启动一个浏览器 # \features\Login_Chinese.py:9
当用户访问http://mail.126.com网址 # \features\Login_Chinese.py:19
当用户访问http://mail.126.com网址 # \features\Login_Chinese.py:19
当用户输入输入用户名“xiaxiaoxu1987”和密码“gloryroad” # \features\Login_Chinese.py:24
当用户输入输入用户名“xiaxiaoxu1987”和密码“gloryroad” # \features\Login_Chinese.py:24
那么页面会出现“未读邮件”关键字 # \features\Login_Chinese.py:46
那么页面会出现“未读邮件”关键字 # \features\Login_Chinese.py:46
场景“成功登录126邮箱”执行结束
场景: 成功退出126邮箱 # \features\Login_Chinese.feature:12
开始执行场景“成功退出126邮箱”
当用户从页面单击退出链接 # \features\Login_Chinese.py:55
当用户从页面单击退出链接 # \features\Login_Chinese.py:55364d904c9c4")>
那么页面显示“您已成功退出网易邮箱”关键内容 # \features\Login_Chinese.py:64
那么页面显示“您已成功退出网易邮箱”关键内容 # \features\Login_Chinese.py:64
场景“成功退出126邮箱”执行结束
Feature: login and logout # \features\Login_English.feature:3
Scenario: Successful Login with Valid Credentials # \features\Login_English.feature:5
开始执行场景“Successful Login with Valid Credentials”
Given Launch a browser # \features\Login_English.py:8
When User visit to http://mail.126.com Page # \features\Login_English.py:16
And User enters UserName"xiaxiaoxu1987" and Password"gloryroad" # \features\Login_English.py:20
Then Message displayed Login Successfully # \features\Login_English.py:33
Then Message displayed Login Successfully # \features\Login_English.py:33
场景“Successful Login with Valid Credentials”执行结束
Scenario: Successful LogOut # \features\Login_English.feature:11
开始执行场景“Successful LogOut”
When User LogOut from the Application # \features\Login_English.py:40
When User LogOut from the Application # \features\Login_English.py:40")>
Then Message displayed LogOut Successfully # \features\Login_English.py:48
Then Message displayed LogOut Successfully # \features\Login_English.py:48
场景“Successful LogOut”执行结束
2 features (2 passed)
4 scenarios (4 passed)
12 steps (12 passed)
恭喜,4个场景被运行,4个场景运行成功

pip show lettuce 显示lettuce版本号
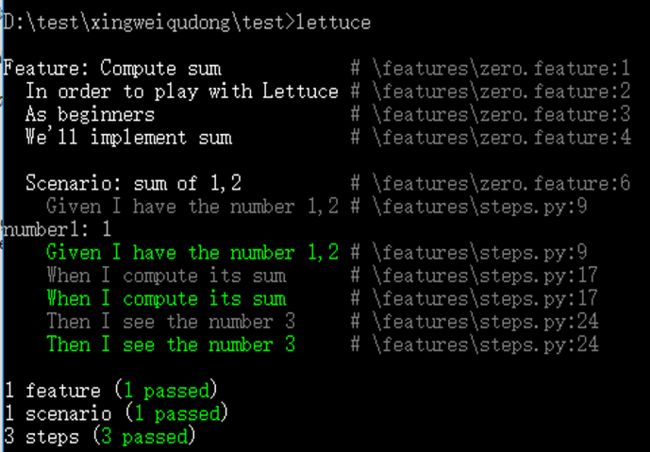
练习,用lettuce实现两个数的相加
steps.py:
#encoding=utf-8
from lettuce import *
# 用于计算整数的阶乘函数
def sum(a,b):
return a+b
@step('I have the number (\d),(\d)')
def have_the_number(step, number1,number2):
# 将通过正则表达式匹配的数字存于全局变量world中
world.number1 = int(number1)
world.number2 = int(number2)
print "number1:",number1#这样打印显示不了
print "number2:",number2#这样打印显示不了
@step('I compute its sum')
def compute_its_sum(step):
# 从全局变量world中取出匹配的数字,
# 计算其阶乘,并将结果再存回world中
world.number = sum(world.number1,world.number2)
print "world.number:",world.number#这样打印显示不了
@step('I see the number (\d+)')
def check_number(step, expected):
# 通过正则匹配到预期数字
expected = int(expected)
print "expected:",expected#这样打印显示不了
# 断言计算阶乘结果是否等于预期
assert world.number == expected, "Got %d" %world.number
feature:
Feature: Compute sum
In order to play with Lettuce
As beginners
We'll implement sum
Scenario: sum of 1,2
Given I have the number 1,2
When I compute its sum
Then I see the number 3
结果:
D:\test\xingweiqudong\test>lettuce
Feature: Compute sum # \features\zero.feature:1
In order to play with Lettuce # \features\zero.feature:2
As beginners # \features\zero.feature:3
We'll implement sum # \features\zero.feature:4
Scenario: sum of 1,2 # \features\zero.feature:6
Given I have the number 1,2 # \features\steps.py:9
number1: 1
Given I have the number 1,2 # \features\steps.py:9
When I compute its sum # \features\steps.py:17
When I compute its sum # \features\steps.py:17
Then I see the number 3 # \features\steps.py:24
Then I see the number 3 # \features\steps.py:24
1 feature (1 passed)
1 scenario (1 passed)
3 steps (3 passed)