埋点数据
原文源自:http://www.woshipm.com/pmd/751876.html
本文作者将从一个埋点系统设计者的角度通俗系统地讲解埋点的全过程,涉及到埋点基础知识、埋点作用、埋点方法、埋点数据流程、埋点应用、埋点管理等信息。
埋点是什么
埋点是互联网领域非常重要的数据信息获取方式。埋点采集信息的过程一般也称作日志采集。
通俗点讲,就是在APP或者web产品中植入一段代码,监控用户行为事件(例如某个页面的曝光)。用户一旦触发了该事件,就会上传埋点代码中定义的、需要上传的有关该事件的信息。
常见的信息包括:用户会话id,用户id,当前页面编码,当前事件编码,触发时间,用户设备id,ip信息等等。
埋点作用
可以看到,除了像电商购物提交的订单报表等信息是用户填写之后,通过业务数据库中进行读取的;用户在APP或web产品上的行为信息,更多需要靠埋点方式进行获取。典型的应用场景就是某个运营活动,页面的点击量(PV)有多少,点击用户数目(UV)有多少,都是用埋点数据进行计算,来对运营活动有数据上的评估。
当然这些信息并不是消费一次就没有用处了。通过埋点收集到的信息,可以作为监控,看到APP的长期表现,也可以作为基础原料,进行复杂的运算,用于用户标签、渠道转化分析、个性推荐等等。
埋点种类
按照信息采集发生的位置来分,埋点可分为客户端埋点、服务端埋点、H5埋点。客户端埋点即监控APP当地发生事件的埋点,例如APP某页面曝光,一旦APP客户端加载了该页面,客户端埋点就会发送相应信息;H5埋点可能是在APP中跳转到的某个H5页面(如运营活动页)上的埋点,也可能是web某页面上的埋点。
下文重点讲的是客户端或H5埋点的方式,服务端埋点一般较少,埋点方式也较为通用。
1、手动埋点

这是埋点最古老的方式。具体的步骤一般是,产品经理在提需求,需要在APP某个页面的某个事件进行埋点,在这个过程中,产品会对该页面和事件按照一套规则进行编码命名(若事件数不多,页面编码命名这一层也可以省略),以便后续通过该编码对上传上来的信息进行辨认;同时,产品也会将这一埋点需要上传的参数告知前端开发。开发明确需求后就会进行埋点。
优点:
- 手动埋点方式简单灵活,来一个埋一个,埋点代码实现过程对开发来说也较为简单,不会占用太多时间。
- 可对埋点中需要上传信息的字段进行个性化选择,满足复杂业务场景。例如页面曝光埋点中,上传的信息只需要是这个页面编码等就可以了,但如果是某个下拉控件的事件,可能上传的信息中还需要带上下拉控件后最终选择了第几项。
缺点:
- 埋点过多时,大量重复性操作较为枯燥且容易出错。新版本发布可能要埋100个点,人工手动去埋,总可能出现某一个忘记埋或者某个应该在A处埋的点埋到了B处的情况。
- 沟通成本较高。需要PM和开发确认。
- 埋点周期长。手动埋点如果出现漏埋情况,必须依赖下一版本发版,补上漏埋的那个埋点,才能看到数据。如果新增一个埋点需求,要看数据也只能等下期了。
2、半自动埋点
看了上面的手动埋点描述,可能很多人都会有疑问,所有的埋点都需要手工去埋是否有必要。就比如100个埋点中,可能有80个埋点都是页面曝光事件,这类埋点非常相似,完全可以用一套埋点手段去解决。那么半自动埋点就是为了解决这种问题,把部分人工的工作进行标准化,做成SDK。阿里埋点实践中的“黄金令箭”方案就是半自动埋点的典型例子。PM提埋点需求时候,直接将自己申请的埋点进行注册,调用符合自己要求的埋点SDK,并进行下发,那么APP或web产品中就会集成该段埋点代码,而不再需要沟通前端开发进行埋点。当然,在半自动埋点不完善的阶段,可能调用SDK的工作是由开发完成的。
友盟、神策分析、growing IO等传统的商用化埋点服务,也均是通过埋点SDK这种手段实现的。另外值得一提的是,近来兴起的可视化埋点方案(腾讯MTA、百度移动统计近期也刚新加入了该功能),也算是半自动埋点的一种。通过可视化埋点的方案,PM可以直接看到APP或web产品的界面,在界面上捕捉需要进行埋点的元素如页面或控件等,再通过可视化的点击录入过程,赋予埋点业务含义。也就是说,可视化埋点方案可以通过所见即所得的方式,方便埋点需求方进行埋点。
优点:
- 将通用的埋点方式进行整合,提高埋点效率,通过同一套SDK,埋点上传的信息也较为规范,便于后续数据处理。
- PM直接调用SDK的方式,使得埋点需求提出过程和埋点过程统一,无需付出复杂劳动,省略了整理埋点需求和沟通的环节,也节约了开发进行埋点的工作量。
- 可视化埋点方案可以更加形象可视地将埋点业务含义和物理代码连接起来,也可以更清晰直观看到哪些控件已有注册埋点。
缺点:
- 同样存在埋点周期长的问题。如果漏埋还是要等下一版本发布。
- 可视化埋点一般只适用于比较简单的APP,如果版本过多,显示的内容不同,需要打开并进行埋点的可视化页面过多,导致管理混乱。
- 公司自行开发可视化埋点方案成本较高。
3、全自动埋点
全自动埋点在一些宣传当中也被称为“无痕埋点”。这种方式和上文的手动和半自动埋点有产生方式上的本质不同。手动和半自动埋点是需求方需要了,才去埋。而全自动埋点则是不管需不需要,将所有的点都埋了。通常这种埋点也是通过SDK实现的,这种SDK不需调用,已经直接嵌入在APP中。因为全自动埋点都是自动生成的,用于对每一个埋点进行标识的埋点编码也是按照既定规则进行生成。通常这种标识是不可读的,需要PM和开发沟通,对埋点编码进行和业务含义上的映射。

全自动埋点方法听起来挺简单粗暴,优点和缺点也同样突出。
优点:
- 根本上解决漏埋问题,缩短埋点周期。
- 无需对页面、控件是否需要进行埋点做区分,需要数据时直接取数据。
缺点:
- 全自动埋点一套SDK对应一套数据上传方式,需要尽可能通用,个性化的数据采集无法满足。一般只能对页面曝光、关闭,控件点击这种通用事件进行全自动埋点。
- 全自动埋点覆盖面广,数据传输压力大,可能有很多上传上来的信息是不需要的。
- 和一些半自动埋点中PM可自行通过SDK自助进行埋点相比,全自动埋点仍需要PM和开发沟通。因为全自动埋点中埋点编码为自动生成,其意义只有开发明白,要想对应到业务含义,必须由开发参与。
- 安卓APP和IOS APP往往是两组开发人员开发的。全自动埋点这种“埋点创造于开发过程而不是需求过程”的模式,很容易导致同一个埋点事件,其埋点物理编码在安卓和IOS上是不同的,这就需要埋点需求方花费时间去做对应。对应过程是复杂而艰辛的。
因而,全自动埋点适用于产品比较小,页面、控件少,上传的数据也较少的情况。同样,全自动埋点也可以配合可视化埋点方案,此时可视化页面中不仅仅是捕捉到页面或控件,同样可以显示其已存在的埋点编码名称,埋点需求方可将该不易读的编码录入到可读的业务含义上。
正如上文所提的,埋点是互联网公司获取数据信息的重要方式。数据的全流程一般涉及到采集、传输、加工、存储、应用等过程。下面就将按照这个顺序,对埋点全流程进行说明。最后,加入了一个埋点系统设计者对埋点管理过程的理解,期待同行的交流~
采集过程
上文提到了埋点信息采集的方式,那么具体埋点信息采集的过程是怎么样的呢?
以H5网页某页面曝光埋点为例子,先讲一下网页页面展现的流程。框图如下: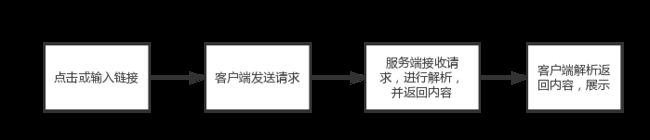
具体细节如下:
- 用户点击或输入某页面链接。
- APP客户端或浏览器向服务器发送HTTP请求。该请求内容一般包括请求的URL、请求方法、请求报头(一些必要的内容例如用户cookie等)、请求内容。
- 服务器接受HTTP请求,进行解析,并将内容返回给客户端或浏览器。返回内容一般包括返回状态(是否成功,例如著名的404就是在这里进行添加的),返回具体内容(请求的网页中包含的内容如图片等),返回报头(cookie等)
- 客户端或浏览器对返回内容进行解析,并把内容展示给用户。
这样就完成了一个页面的曝光展示。如果对该曝光事件加上埋点,前两步是没有影响的,在第三步:服务器在返回HTTP内容时,会加入一段与埋点相关的脚本代码(如上文埋点方式部分所说,这段代码可能是手动埋点写入的,也可能是半自动或全自动埋点方式写入的)。
客户端或浏览器解析到这部分内容时,会向埋点日志接收服务器(以下简称埋点服务器)发送一个请求。这个请求中即带有我们通过埋点想获得的宝贵的数据信息。埋点服务器接受到请求后,会返回一个已接收的信息给客户端。同时,埋点服务器会将这些信息传输到后续环节。如下图:
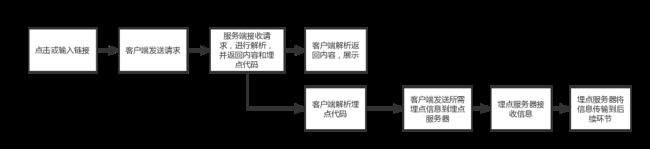
这里再说一下和数据准确性有关的内容。在客户端向埋点服务器发送信息的过程中,可能存在丢包,即数据发送失败信息没有传输过去的情况。该发送过程一般通过POST格式,发送JSON串信息,具体方式分两种:一种是单条发送;一种是在本地打包成zip包,积累一定量后发送。两种方式中,zip的丢包情况更严重些。所以PM在看数据时候,也应当清楚,数据会有一定误差。(据作者实践经验,单条POST格式数据误差一般不超过2%)
传输流程:
埋点数据产生之后,被埋点服务器接收,有些时候会进行解析操作,然后会通过消息订阅通道例如kafka之类进行消息的分发,进入离线或实时的储存中,用于后续的计算和分析。
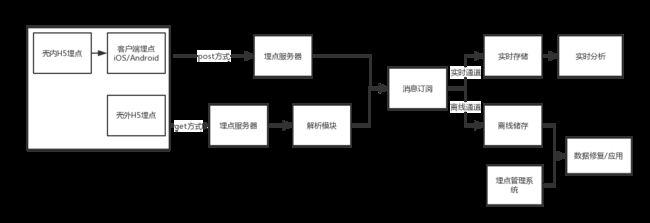
加工存储
加工:经过加工存储这一步后,埋点数据基本可以从收集到的原材料状态变为可以为业务服务的有用数据了。上文提到,埋点数据都是一条一条,是用户触发埋点对应事件时上传的。
这些数据可能包括:用户会话id,用户id,当前页面编码,当前事件编码,触发时间,用户设备id,ip信息等,这些零散的信息需要通过加工处理进行聚合,变成更加通用常用的数据,便于后续调用。
例如一些通用的处理:针对APP首页曝光事件,选取当日首页曝光事件上传的数据条数,对用户id去重并加和即可以得到当日的UV。
存储:对于离线存储来说,埋点原始数据会以表(类似excel表)的形式存储于数据仓库的原始数据层,经过上述处理过的数据,会以另外一张表的形式存储于数据仓库的汇总层。如果数据仓库建设比较完善,通用的业务数据,直接从汇总层甚至更上层的应用层中取即可,而不必再去取原始层的埋点数据,省去了每次计算的工作量。
埋点管理过程
最原始的埋点管理方式是用文档或表格记录下来埋点的编码命名、业务含义及其他必备信息,在埋点业务方内部共享即可。
但当公司的产品越做越多越做越大,相应的埋点就会越多(多达成千甚至上万)。对互联网规模企业,管理大量埋点往往也需要配套的工具:埋点信息管理系统。
埋点信息管理系统主要有的功能:
- 提供埋点信息的录入功能。
- 记录各埋点是否存在,进行埋点层级管理。因为埋点较多,往往需要按照APP-页面-控件的层级进行分类、记录和查询。
- 展示并可查询某埋点的详细信息。例如物理编码信息和对应的业务含义信息,埋点的上线版本和时间,埋点管理员责任人,埋点信息储存的数仓表名称以及必要的埋点数据结构体(对个性化埋点可能出现的上传数据中新加字段的解释)。
- 辅助功能。如埋点数据量的监控,埋点信息预览,埋点数据通用分析及可视化展示等。
埋点管理是建立在埋点生成、传输、储存等过程的基础之上的。管理的重点和难点,在于大量埋点物理编码(命名编码)和业务含义的对应。这个对应是将不可读的英文编码字段和易于理解的汉语业务含义连接起来的过程。对应可能是一对多,多对一,甚至多对多的。
1.对应过程在手动埋点中,反应在PM与开发沟通及开发具体埋点行为中。首先PM需要根据业务含义,选择要埋的点并取或生成一个物理编码;之后开发按照这个对应关系,将物理编码写入到业务含义对应的页面或事件上。这个过程是抽象且容易出错的。
2.对应过程在全自动埋点中,反应在PM和开发沟通并“认领”自动埋点的行为中。PM需要向开发了解,已经存在的某物理编码代表的是什么意思即其业务含义是什么,然后将这两者关联。往往还需要将IOS和安卓两个不同的物理编码关联到同一业务含义上,因为这两个物理编码实际就是同一页面或控件。这个过程,也是抽象易错的。
抽象易错,主要是因为需要凭脑中想象将两种文字编码级的内容进行关联。上文提到的可视化埋点则可通过直观的APP展现,显示出物理编码及业务含义,解决抽象的问题。伴随着产品迭代埋点数目增长,似乎有效的可视化埋点是大公司做埋点管理有必要尝试的方向。
原文源自:http://www.woshipm.com/pmd/751876.html
本文作者将从一个埋点系统设计者的角度通俗系统地讲解埋点的全过程,涉及到埋点基础知识、埋点作用、埋点方法、埋点数据流程、埋点应用、埋点管理等信息。
埋点是什么
埋点是互联网领域非常重要的数据信息获取方式。埋点采集信息的过程一般也称作日志采集。
通俗点讲,就是在APP或者web产品中植入一段代码,监控用户行为事件(例如某个页面的曝光)。用户一旦触发了该事件,就会上传埋点代码中定义的、需要上传的有关该事件的信息。
常见的信息包括:用户会话id,用户id,当前页面编码,当前事件编码,触发时间,用户设备id,ip信息等等。
埋点作用
可以看到,除了像电商购物提交的订单报表等信息是用户填写之后,通过业务数据库中进行读取的;用户在APP或web产品上的行为信息,更多需要靠埋点方式进行获取。典型的应用场景就是某个运营活动,页面的点击量(PV)有多少,点击用户数目(UV)有多少,都是用埋点数据进行计算,来对运营活动有数据上的评估。
当然这些信息并不是消费一次就没有用处了。通过埋点收集到的信息,可以作为监控,看到APP的长期表现,也可以作为基础原料,进行复杂的运算,用于用户标签、渠道转化分析、个性推荐等等。
埋点种类
按照信息采集发生的位置来分,埋点可分为客户端埋点、服务端埋点、H5埋点。客户端埋点即监控APP当地发生事件的埋点,例如APP某页面曝光,一旦APP客户端加载了该页面,客户端埋点就会发送相应信息;H5埋点可能是在APP中跳转到的某个H5页面(如运营活动页)上的埋点,也可能是web某页面上的埋点。
下文重点讲的是客户端或H5埋点的方式,服务端埋点一般较少,埋点方式也较为通用。
1、手动埋点
这是埋点最古老的方式。具体的步骤一般是,产品经理在提需求,需要在APP某个页面的某个事件进行埋点,在这个过程中,产品会对该页面和事件按照一套规则进行编码命名(若事件数不多,页面编码命名这一层也可以省略),以便后续通过该编码对上传上来的信息进行辨认;同时,产品也会将这一埋点需要上传的参数告知前端开发。开发明确需求后就会进行埋点。
优点:
- 手动埋点方式简单灵活,来一个埋一个,埋点代码实现过程对开发来说也较为简单,不会占用太多时间。
- 可对埋点中需要上传信息的字段进行个性化选择,满足复杂业务场景。例如页面曝光埋点中,上传的信息只需要是这个页面编码等就可以了,但如果是某个下拉控件的事件,可能上传的信息中还需要带上下拉控件后最终选择了第几项。
缺点:
- 埋点过多时,大量重复性操作较为枯燥且容易出错。新版本发布可能要埋100个点,人工手动去埋,总可能出现某一个忘记埋或者某个应该在A处埋的点埋到了B处的情况。
- 沟通成本较高。需要PM和开发确认。
- 埋点周期长。手动埋点如果出现漏埋情况,必须依赖下一版本发版,补上漏埋的那个埋点,才能看到数据。如果新增一个埋点需求,要看数据也只能等下期了。
2、半自动埋点
看了上面的手动埋点描述,可能很多人都会有疑问,所有的埋点都需要手工去埋是否有必要。就比如100个埋点中,可能有80个埋点都是页面曝光事件,这类埋点非常相似,完全可以用一套埋点手段去解决。那么半自动埋点就是为了解决这种问题,把部分人工的工作进行标准化,做成SDK。阿里埋点实践中的“黄金令箭”方案就是半自动埋点的典型例子。PM提埋点需求时候,直接将自己申请的埋点进行注册,调用符合自己要求的埋点SDK,并进行下发,那么APP或web产品中就会集成该段埋点代码,而不再需要沟通前端开发进行埋点。当然,在半自动埋点不完善的阶段,可能调用SDK的工作是由开发完成的。
友盟、神策分析、growing IO等传统的商用化埋点服务,也均是通过埋点SDK这种手段实现的。另外值得一提的是,近来兴起的可视化埋点方案(腾讯MTA、百度移动统计近期也刚新加入了该功能),也算是半自动埋点的一种。通过可视化埋点的方案,PM可以直接看到APP或web产品的界面,在界面上捕捉需要进行埋点的元素如页面或控件等,再通过可视化的点击录入过程,赋予埋点业务含义。也就是说,可视化埋点方案可以通过所见即所得的方式,方便埋点需求方进行埋点。
优点:
- 将通用的埋点方式进行整合,提高埋点效率,通过同一套SDK,埋点上传的信息也较为规范,便于后续数据处理。
- PM直接调用SDK的方式,使得埋点需求提出过程和埋点过程统一,无需付出复杂劳动,省略了整理埋点需求和沟通的环节,也节约了开发进行埋点的工作量。
- 可视化埋点方案可以更加形象可视地将埋点业务含义和物理代码连接起来,也可以更清晰直观看到哪些控件已有注册埋点。
缺点:
- 同样存在埋点周期长的问题。如果漏埋还是要等下一版本发布。
- 可视化埋点一般只适用于比较简单的APP,如果版本过多,显示的内容不同,需要打开并进行埋点的可视化页面过多,导致管理混乱。
- 公司自行开发可视化埋点方案成本较高。
3、全自动埋点
全自动埋点在一些宣传当中也被称为“无痕埋点”。这种方式和上文的手动和半自动埋点有产生方式上的本质不同。手动和半自动埋点是需求方需要了,才去埋。而全自动埋点则是不管需不需要,将所有的点都埋了。通常这种埋点也是通过SDK实现的,这种SDK不需调用,已经直接嵌入在APP中。因为全自动埋点都是自动生成的,用于对每一个埋点进行标识的埋点编码也是按照既定规则进行生成。通常这种标识是不可读的,需要PM和开发沟通,对埋点编码进行和业务含义上的映射。
全自动埋点方法听起来挺简单粗暴,优点和缺点也同样突出。
优点:
- 根本上解决漏埋问题,缩短埋点周期。
- 无需对页面、控件是否需要进行埋点做区分,需要数据时直接取数据。
缺点:
- 全自动埋点一套SDK对应一套数据上传方式,需要尽可能通用,个性化的数据采集无法满足。一般只能对页面曝光、关闭,控件点击这种通用事件进行全自动埋点。
- 全自动埋点覆盖面广,数据传输压力大,可能有很多上传上来的信息是不需要的。
- 和一些半自动埋点中PM可自行通过SDK自助进行埋点相比,全自动埋点仍需要PM和开发沟通。因为全自动埋点中埋点编码为自动生成,其意义只有开发明白,要想对应到业务含义,必须由开发参与。
- 安卓APP和IOS APP往往是两组开发人员开发的。全自动埋点这种“埋点创造于开发过程而不是需求过程”的模式,很容易导致同一个埋点事件,其埋点物理编码在安卓和IOS上是不同的,这就需要埋点需求方花费时间去做对应。对应过程是复杂而艰辛的。
因而,全自动埋点适用于产品比较小,页面、控件少,上传的数据也较少的情况。同样,全自动埋点也可以配合可视化埋点方案,此时可视化页面中不仅仅是捕捉到页面或控件,同样可以显示其已存在的埋点编码名称,埋点需求方可将该不易读的编码录入到可读的业务含义上。
正如上文所提的,埋点是互联网公司获取数据信息的重要方式。数据的全流程一般涉及到采集、传输、加工、存储、应用等过程。下面就将按照这个顺序,对埋点全流程进行说明。最后,加入了一个埋点系统设计者对埋点管理过程的理解,期待同行的交流~
采集过程
上文提到了埋点信息采集的方式,那么具体埋点信息采集的过程是怎么样的呢?
以H5网页某页面曝光埋点为例子,先讲一下网页页面展现的流程。框图如下:
具体细节如下:
- 用户点击或输入某页面链接。
- APP客户端或浏览器向服务器发送HTTP请求。该请求内容一般包括请求的URL、请求方法、请求报头(一些必要的内容例如用户cookie等)、请求内容。
- 服务器接受HTTP请求,进行解析,并将内容返回给客户端或浏览器。返回内容一般包括返回状态(是否成功,例如著名的404就是在这里进行添加的),返回具体内容(请求的网页中包含的内容如图片等),返回报头(cookie等)
- 客户端或浏览器对返回内容进行解析,并把内容展示给用户。
这样就完成了一个页面的曝光展示。如果对该曝光事件加上埋点,前两步是没有影响的,在第三步:服务器在返回HTTP内容时,会加入一段与埋点相关的脚本代码(如上文埋点方式部分所说,这段代码可能是手动埋点写入的,也可能是半自动或全自动埋点方式写入的)。
客户端或浏览器解析到这部分内容时,会向埋点日志接收服务器(以下简称埋点服务器)发送一个请求。这个请求中即带有我们通过埋点想获得的宝贵的数据信息。埋点服务器接受到请求后,会返回一个已接收的信息给客户端。同时,埋点服务器会将这些信息传输到后续环节。如下图:
这里再说一下和数据准确性有关的内容。在客户端向埋点服务器发送信息的过程中,可能存在丢包,即数据发送失败信息没有传输过去的情况。该发送过程一般通过POST格式,发送JSON串信息,具体方式分两种:一种是单条发送;一种是在本地打包成zip包,积累一定量后发送。两种方式中,zip的丢包情况更严重些。所以PM在看数据时候,也应当清楚,数据会有一定误差。(据作者实践经验,单条POST格式数据误差一般不超过2%)
传输流程:
埋点数据产生之后,被埋点服务器接收,有些时候会进行解析操作,然后会通过消息订阅通道例如kafka之类进行消息的分发,进入离线或实时的储存中,用于后续的计算和分析。
加工存储
加工:经过加工存储这一步后,埋点数据基本可以从收集到的原材料状态变为可以为业务服务的有用数据了。上文提到,埋点数据都是一条一条,是用户触发埋点对应事件时上传的。
这些数据可能包括:用户会话id,用户id,当前页面编码,当前事件编码,触发时间,用户设备id,ip信息等,这些零散的信息需要通过加工处理进行聚合,变成更加通用常用的数据,便于后续调用。
例如一些通用的处理:针对APP首页曝光事件,选取当日首页曝光事件上传的数据条数,对用户id去重并加和即可以得到当日的UV。
存储:对于离线存储来说,埋点原始数据会以表(类似excel表)的形式存储于数据仓库的原始数据层,经过上述处理过的数据,会以另外一张表的形式存储于数据仓库的汇总层。如果数据仓库建设比较完善,通用的业务数据,直接从汇总层甚至更上层的应用层中取即可,而不必再去取原始层的埋点数据,省去了每次计算的工作量。
埋点管理过程
最原始的埋点管理方式是用文档或表格记录下来埋点的编码命名、业务含义及其他必备信息,在埋点业务方内部共享即可。
但当公司的产品越做越多越做越大,相应的埋点就会越多(多达成千甚至上万)。对互联网规模企业,管理大量埋点往往也需要配套的工具:埋点信息管理系统。
埋点信息管理系统主要有的功能:
- 提供埋点信息的录入功能。
- 记录各埋点是否存在,进行埋点层级管理。因为埋点较多,往往需要按照APP-页面-控件的层级进行分类、记录和查询。
- 展示并可查询某埋点的详细信息。例如物理编码信息和对应的业务含义信息,埋点的上线版本和时间,埋点管理员责任人,埋点信息储存的数仓表名称以及必要的埋点数据结构体(对个性化埋点可能出现的上传数据中新加字段的解释)。
- 辅助功能。如埋点数据量的监控,埋点信息预览,埋点数据通用分析及可视化展示等。
埋点管理是建立在埋点生成、传输、储存等过程的基础之上的。管理的重点和难点,在于大量埋点物理编码(命名编码)和业务含义的对应。这个对应是将不可读的英文编码字段和易于理解的汉语业务含义连接起来的过程。对应可能是一对多,多对一,甚至多对多的。
1.对应过程在手动埋点中,反应在PM与开发沟通及开发具体埋点行为中。首先PM需要根据业务含义,选择要埋的点并取或生成一个物理编码;之后开发按照这个对应关系,将物理编码写入到业务含义对应的页面或事件上。这个过程是抽象且容易出错的。
2.对应过程在全自动埋点中,反应在PM和开发沟通并“认领”自动埋点的行为中。PM需要向开发了解,已经存在的某物理编码代表的是什么意思即其业务含义是什么,然后将这两者关联。往往还需要将IOS和安卓两个不同的物理编码关联到同一业务含义上,因为这两个物理编码实际就是同一页面或控件。这个过程,也是抽象易错的。
抽象易错,主要是因为需要凭脑中想象将两种文字编码级的内容进行关联。上文提到的可视化埋点则可通过直观的APP展现,显示出物理编码及业务含义,解决抽象的问题。伴随着产品迭代埋点数目增长,似乎有效的可视化埋点是大公司做埋点管理有必要尝试的方向。