CS224N笔记——词向量表示
目录
Word meaning
Word2vec introduction
Word2vec目标函数的梯度
-
Word meaning
如何表示一个词的词义?
在韦氏词典中meaning的词义为:
(1)用单词、短语等表示的想法;
(2)人们想要通过单词、符号等表示的想法;
(3)在写作、艺术等作品中表达的思想。
如何用计算机处理词义?
最常用的方法:用分类资源来处理词义,如果是英语,最著名的分类资源是WordNet,能够查询一类东西的上位词(熊猫-肉食动物-哺乳动物-物体)和同义词(good:honorable,respectable)
离散化表征的问题
同义词资源很多但会遗漏大量的细微差别,例如:good的一组同义词是adept,expert,good,practiced,proficient,skillful,但会遗漏一些新词(不太可能持续更新到同义词集中),例如:wicked,badass,nifty,crack,ace,wizard,genius,ninja。
人们往同义词集里加什么词是一个非常主观的选择,也需要大量人力多年的努力,同时很难对词汇的相似性给出准确的定义。
几乎所有的基于规则和统计的NLP研究都使用了原子符号来表示单词,例如使用one-hot编码来表示单词。
从符号化到离散化表征
如果使用one-hot编码,查询向量和文档向量正交,他们之间没有天然的近似含义
可以建立词汇之间一套完全独立的相似性关系,或者探索一种直接的方法,一个单词编码表示的含义是可以直接阅读的,在这些表示中,就可以看出相似性,我们要做的就是构造这些向量,然后做一种类似求解点积的操作,这样就可以让我们了解词汇之间有多少相似性。
基于分布相似性的表征
只需通过观察某个词汇出现的上下文,并对这些上下文做一些处理来得到大量表示这个词汇含义的值。
例如下面这句话:

就可以用banking的上下文中的词来表示banking的含义。
词义是由向量形式定义的
给每一个单词构造一个密集型向量,让它可以预测目标单词所在文本的其他词汇。

学习神经网络词嵌入的通用方法
定义一个模型,根据中心词汇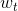 预测它上下文词汇(context)出现的概率
预测它上下文词汇(context)出现的概率![]() ,其损失函数为
,其损失函数为![]() ,这里的-t表示围绕在t中心词周围的其他单词。在大型语料库的各个地方t重复这样的操作,调整词汇表示,从而使损失最小化。
,这里的-t表示围绕在t中心词周围的其他单词。在大型语料库的各个地方t重复这样的操作,调整词汇表示,从而使损失最小化。
-
Word2vec introduction
word2vec尝试去做的最基本的事情就是利用语言的意义理论,来预测每个单词和它上下文的词汇。
两个用于生成词向量的算法:Skip-gram(跳词模型),CBOW(连续词袋模型)
两个效率中等的训练方法:Hierarchical softmax(层序softmax),Negative sampling(逆采样)
Skip-gram

Skip-gram在每一个估算步都取一个词作为中心词汇,预测它一定范围内的上下文的词汇。这个模型将定义一个概率分布,即给定一个中心词汇,某个单词在它上下文中出现的概率。选取词汇的向量表示,让概率分布值最大化。
word2vec细节
定义一个“半径”m,然后从中心词汇开始,到距离为m的位置,来预测周围的词汇。然后在多处进行多次重复操作,选择词汇向量,以便让预测的概率达到最大。
目标函数:J`

 就是词汇的向量表示,也是每个词汇的向量表示的唯一参数。
就是词汇的向量表示,也是每个词汇的向量表示的唯一参数。
根据由单词向量构造而成的中心词汇来得出其上下文单词的概率分布:

其中,c(中心单词)和o(输出单词)分别代表单词在词汇表空间中的索引以及它的类型,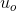 是索引为o的单词所对应的向量,
是索引为o的单词所对应的向量,![]() 是中心词汇对应的向量。
是中心词汇对应的向量。
利用Softmax模型确定相应的概率分布,选取两个向量的点积,将它们转换成Softmax形式。
点积

首先求两个单词向量的点积,这种求积类似于一种粗糙衡量相似性的方法,两个向量的相似性越大,那么这个点积就越大。
Softmax:将数值转换成概率的标准方法

最终的Skip-gram模型

:中心词汇,是一个one-hot向量
 :所有中心词汇的表示组成的矩阵
:所有中心词汇的表示组成的矩阵
![]() :中心词汇的表示
:中心词汇的表示
![]() :存储上下文词汇的表示
:存储上下文词汇的表示
然后进行中心词汇和上下文表示的点积和Softmax操作。
训练模型:计算所有的向量梯度
将模型中所有的参数都放进一个大的向量里。对每个单词,都有一个d维的小向量,不管它是中心词汇还是上下文词汇,同时有一个包含V个单词的单词表,每一个单词都有一个代表上下文的词向量和一个代表中心词汇的词向量,这个向量的总长度就是2dV。
然后进行优化,通过改变这些参数让模型的目标方程J`最大化。
-
Word2vec目标函数的梯度
推导中心词的梯度:




其中利用到了链式法则和对向量求偏导数的公式:

