基于Python的Stanford CoreNLP自然语言分析快速入门教程
最近小组汇报正好用到了corenlp,所以想把相关内容整理成博客(汇报ppt和演示代码附在最后了,有需要的话可以自取)。主要参考了corenlp官网教程和网上一些别的入门教程,由于代码比较简短,所以侧重理论描述一点。通过这篇博客 ,你可以:
- 对corenlp框架有初步的了解
- 对corenlp中的词性标注、命名实体、成分句法、依存句法等概念有初步的了解,
- 在python中使用corenlp进行简单的自然语言分析
- 大致读懂相关的输出结果
一、Stanford CoreNLP简介
CoreNLP是斯坦福提供的一套自然语言分析工具。它可以给出单词的基本形式、词类、是否是公司、人的名字等,规范日期、时间和数字量,根据短语和句法依存关系标记句子结构,指出哪些名词短语引用相同的实体,表示情感,提取实体引用之间的特定或开放类关系,获取人们所说的引号等。
它最初是为英语开发的,但现在也为(现代标准)阿拉伯语,(大陆)中文,法语,德语和西班牙语提供不同级别的支持。
如果你有这些需要的话,请选择Stanford CoreNLP:
- 集成的NLP工具包,具有广泛的语法分析工具
- 快速,强大的任意文本注释器,广泛用于生产中
- 定期更新的现代软件包,具有总体上最高质量的文本分析
- 支持多种主要(人类)语言
- 适用于大多数主要现代编程语言的API
- 能够作为简单的Web服务运行
斯坦福大学CoreNLP的目标是使将多种语言分析工具轻松应用于一段文本变得非常容易。只需两行代码,就可以在一段纯文本上运行工具管道。 CoreNLP的设计具有高度的灵活性和可扩展性。使用一个选项,就可以更改应启用和禁用的工具。
Stanford CoreNLP集成了Stanford的许多NLP工具,包括词性(POS)标记器,命名实体识别器(NER),解析器,共指解析系统,情感分析,自举模式学习和开放信息提取工具等。此外,注释程序管道可以包括其他自定义或第三方注释程序。 CoreNLP的分析为高级和特定领域的文本理解应用程序提供了基础构建块。
二、理论基础
2.1 Part of Speech 词性标注
词性标注的主要任务是消除词性兼类歧义。在任何一种自然语言中,词性兼类问题都普遍存在,尤其在汉语中常用词兼类现象更加严重,所以需要词性标注来消除词性兼类歧义。
coreNLP使用的词性标注集是UPenn Treebank词性标注集,一共包含33类词,如NN 名词、NR 专业名词、NT 时间名词、VA可做谓语的形容词、VC“是”、VE“有”作为主要动词、VV 其他动词、AD副词、M量词等。
POS举例:

2.1.1 名词
专有名词:NR
一个专有名词可以是一个特定的人名,政治或地理上定义的地方(城市、国家、河流、山脉等),或者是一种组织(企业、政府或其他组织实体)
时间名词:NT
时间名词可以是介词的宾语,譬如在、从、到、等到。它们可以被问及,如“这个时候”,也可以被用以提问“什么时候”。还可以直接修饰动词短语或者主语。像其他名词一样,时间名词可以是某些动词的论元。
例子:一月、汉朝、当今、何时、今后
其他名词:NN
其他名词包括所有其他名词。其他名词NN,除了地方名词,一般不能修饰动词短语
2.1.2 动词、形容词
谓词性形容词:VA
相当于英语中的形容词和中文语法中的静态动词。包括两类:
第一类:没有宾语且能被“很”修饰的谓语。
第二类:源自第一类的、通过重叠(如红彤彤)或者通过名词加形容词模式如“像N一样A”(如雪白) 的谓语。
系动词:VC
“是”和“为”被标记为VC,如果“非”的意思是“不是”并且句子里没有其他动词时,“非”也被标注为VC。
“是”有几种用法:
·连接两个名词短语或者主语:他 是/VC 学生。
·在分裂句中:他 是/VC 昨天 来 的/SP。
·为了强调:他 是/VC 喜欢 看 书。现在,在所有这些情况中,“是”被标注为VC。
“有”作为主要动词:VE
只有当“有,没{有}”和“无”作为主要动词时(包括占有的“有”和表存在的“有”等等),被标注为VE。
其他动词:VV
VV包括其他动词,诸如情态动词,提升谓词(如“可能”),控制动词(如“要”、“想”),行为动词(如“走”),心理动词(如“喜欢”、“了解”、“怨恨”),等等。
形容词:JJ、JJR、JJS
-JJ形容词或序数词
-JJR形容词比较级
-JJS形容词最高级
2.1.3 度量词、副词、介词
度量词:M
度量词跟在数字后形成Det+M结构修饰名词或动词,包括类词(如“个”),表示一群的度量词,如“群”,以及公里、升等度量词。
副词:AD
副词包括情态副词、频率副词、程度副词、连接副词等,大部分副词的功能是修饰动词短语或主语。
如:仍然、很、最、大大、又、约
介词:P
介词可以把名词短语或从句作为论元。
注:把和被不标注为P
如:从、对
2.1.4 助词
“的”作为补语标记/名词化标记:DEC
如:吃的DEC
模式是:S/VP DEC{NP}
补语短语 得:DER
在V-得-R和V-得结构中,“得”标记为DER。
注:有些以“得”结尾的搭配不是V-得结构,如记得,获得是动词
“的”作为关联标记或所有格标记:DEG
模式:NP/PP/JJ/DT DEG{NP}
方式“地”:DEV
当“地”出现在“XP地VP”,XP修饰VP。在一些古典文学中,“的”也用于这种情景,此时“的”也标注为DEV
动态助词:AS
动态助词仅包括“着,了,过,的”
句末助词:SP
SP经常出现在句末,如:他好吧[SP]?
有时,句末助词用于表停顿,如:他吧[SP],人很好。
如:了,呢,吧,啊,呀,吗
ETC
ETC用于标注等,等等
其他助词:MSP
“所,以,来,而”,当它们出现在VP前时,标注为MSP。
所:他所[MSP]需要的/DEC
以或来:用……以/MSP(或来)维持
而:为……而[MSP]奋斗
2.1.5 限定词、数词
限定词:DT
限定词包括指示词(如这、那、该)和诸如“每、各、前、后”等词。限定词不包括基数词和序列词。
基数词:CD
CD包括基数词并随意与一些概数词连用,如“来、多、好几”和诸如“好些、若干、半、许多、很多(如很多 学生)”等词。
例子:1245,一百。
序列词:OD
序列词被标注为OD。我们把第+CD看做一个词,并标注它为OD。
例子:第一百。
2.1.6 代词、方位词、连词
方位词:LC
方位词的一个功能是连接前述的名词短语或者主语,从而使整个短语可以作为这些介词的论元或者来修饰动词短语或主语。
一些方位词可以独立使用作为介词或动词的论元。一些方位词可以被“最”修饰。方位词不能被Det+M所修饰。
如:前,后,里,外,内,北,东
如:为止、以来、以内
并列连接词:CC
CC的主要模式是:XP{,},CC XP。
如:与、和、或、或者、还是(or)
代词:PN
代词的功能是作为名词短语的替代物或者表示事先详细说明的或者从上下文可知晓的被叫的人或事。它们一般不受Det+M或者形容词性短语修饰。
如:你、我、这、那、自己
从属连词:CS
从属连词连接两个句子,一个句子从属于另一个,这样的连词标记为CS。CS模式是:CS S1,S2和S2 CS,S1。
如:如果/CS,……就/AD……
2.1.7 感叹词、拟声词、被、把、其他名称修饰语
感叹词:IJ
出现在句首位置的感叹词,如:啊
拟声词:ON
- 修饰“ON地V”中的VP:雨哗哗[ON]地[DEV]下了[AS]一夜
- 修饰“ON中的N”中的NP:砰[ON]的/DEG一声!
- 自行成句:砰砰[ON]!
- 一般不能被副词修饰,如:哗啦啦,咯吱。
长“被”结构:LB
仅包括“被,叫,给,为(口语中)”,当它们出现在被字结构NP0+LB+NP1+VP中
如:他被/LB 我训了/AS 一顿/M .
注:当叫作为兼语动词时,“叫”标注为VV,如:他叫/VV你去。
短“被”结构:SB
NP0+SB+VP,他被/SB 训了/AS一顿/M。
注:“给”有其他标记:LB,VV和P。
如:你给/P他写封/M信。
把字结构:BA
仅包括“把,将”,当它们出现在把字结构中(NP0+BA+NP1+VP)。
如:他把/BA你骗了/AS。
注:“将”有其他标记:AD和VV,如:他将/VV了[AS]我的[DEG]军。
其他名词修饰语:JJ
- 区别词 只修饰模式JJ+的+{N}或JJ+N中的名词,且一定要有“的”,它们不能被程度副词修饰。如:共同/JJ的/DEG目标/NN,她是[VC]女/JJ的/DEG。
- 带有连字符的复合词通常为双音节词 JJ+N 如留美/JJ学者/NN
- 形容词:新/JJ消息/NN模式:JJ+N注:当“的/DEC”在形容词和名词中间时,形容词标记为VA
外来词:FW
FW仅被用于:当词性标注标记在上下文中不是很清楚时。外来词不包括外来词的翻译,不包括混合中文的词(如卡拉OK/NN,A型/NN),不包括词义和词性在文中都是清楚的词
标点:PU
当标点是词的一部分时,不用标注为PU,如123,456/CD
2.2 Named Entities 命名实体
命名实体识别是识别一个句子中有特定意义的实体并将其区分为人名,机构名,日期,地名,时间等类别的工作。
命名实体识别本质上是一个模式识别任务, 即给定一个句子, 识别句子中实体的边界和实体的类型,是自然语言处理任务中一项重要且基础性的工作。

2.3 Constituency Parsing 成分句法
成分句法分析是识别出句子中的短语结构以及短语之间的层次句法关系,如ROOT要处理文本的语句、IP简单从句、NP名词短语、VP动词短语、LCP方位词短语、PP介词短语、CP由‘的’构成的表示修饰性关系的短语、DNP由‘的’构成的表示所属关系的短语、ADVP副词短语、ADJP形容词短语、DP限定词短语、QP量词短语、CC并列关系等。
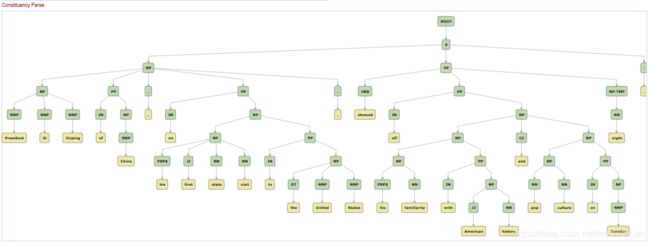
2.4 Dependency Parsing 依存句法
依存句法分析是识别句子中词汇与词汇之间的相互依存关系,如nsubj名词性主语、obj 宾语、dobj直接宾语、iobj间接宾语、nmod 复合名词修饰、amod形容词修饰、advmod状语、appos同位词、cc并列关系、conj 连接两个并列的词、csubj 从主关系、csubjpass主从被动关系等

三、CoreNLP实践
3.1 库包准备
- 下载stanford-corenlp-4.0.0压缩包和中文jar包(如果需要处理中文的话),并将压缩包解压,注意记住自己解压的路径
- 把中文jar包命名为stanford-chinese-corenlp-yyyy-MM-dd-models.jar格式并放置于解压的文件夹中,yyyy-mm-dd是时间,可以随便填

3.2 在python中安装stanfordcorenlp
在python中镜像安装,输入如下命令
pip install stanfordcorenlp -i http://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn
3.3 调用stanfordcorenlp
stanfordcorenlp是CoreNLP的一个python接口,主要功能包括分词、词性标注、命名实体识别、句法结构分析和依存句法分析等。
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'F:\coder\jars\stanford-corenlp-4.0.0',lang='zh') # 本地jar包所在目录路径,中文分析:lang='zh'
# nlp = StanfordCoreNLP('http://localhost', port=9000) #通过服务器访问
sentence = '金角大王,是在电视剧《西游记》中登场的虚拟人物。与兄弟银角大王是平顶山莲花洞的两个妖怪。原是太上老君门下看守金炉的童子。'
print('Tokenize:', nlp.word_tokenize(sentence)) # 令牌化
print('Part of Speech:', nlp.pos_tag(sentence)) # 词性标注
print('Named Entities:', nlp.ner(sentence)) # 命名实体
print('Constituency Parsing:', nlp.parse(sentence)) # 语法树,成分句法把句子组织成短语的形式
print('Dependency Parsing:', nlp.dependency_parse(sentence)) # 依存句法 揭示句子中词的依赖关系
nlp.close()nlp = StanfordCoreNLP(r'F:\coder\jars\stanford-corenlp-4.0.0',lang='zh') # 本地jar包所在目录路径,第一个参数是存放jar包的corenlp路径,如果处理中文的话需要附上lang=‘zh’
输出: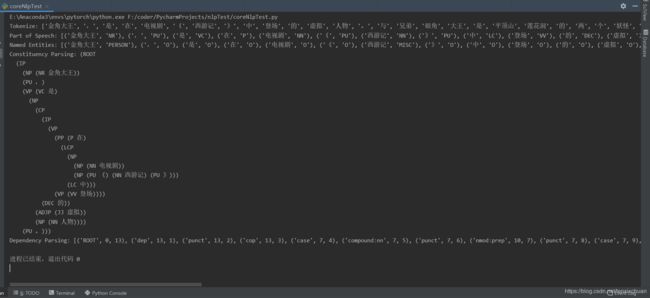
3.3.1 令牌化
将句子划分为单词,如示例句子被划分为金角大王、是、在、电视剧等,如:
Tokenize: [‘金角大王’, ‘,’, ‘是’, ‘在’, ‘电视剧’, ‘《’, ‘西游记’, ‘》’, ‘中’, ‘登场’, ‘的’, ‘虚拟’, ‘人物’, ‘。’, ‘与’, ‘兄弟’, ‘银角’, ‘大王’, ‘是’, ‘平顶山’, ‘莲花洞’, ‘的’, ‘两’, ‘个’, ‘妖怪’, ‘。’, ‘原是’, ‘太上老君’, ‘门下’, ‘看守’, ‘金炉’, ‘的’, ‘童子’, ‘。’]
3.3.2 词性标注
标注单词的词性以避免歧义,如:
Part of Speech: [(‘金角大王’, ‘NR’), (’,’, ‘PU’), (‘是’, ‘VC’), (‘在’, ‘P’), (‘电视剧’, ‘NN’), (’《’, ‘PU’), (‘西游记’, ‘NN’), (’》’, ‘PU’), (‘中’, ‘LC’), (‘登场’, ‘VV’), (‘的’, ‘DEC’), (‘虚拟’, ‘JJ’), (‘人物’, ‘NN’), (’。’, ‘PU’), (‘与’, ‘P’), (‘兄弟’, ‘NN’), (‘银角’, ‘NN’), (‘大王’, ‘NN’), (‘是’, ‘VC’), (‘平顶山’, ‘NR’), (‘莲花洞’, ‘NN’), (‘的’, ‘DEG’), (‘两’, ‘CD’), (‘个’, ‘M’), (‘妖怪’, ‘VA’), (’。’, ‘PU’), (‘原是’, ‘AD’), (‘太上老君’, ‘NR’), (‘门下’, ‘VV’), (‘看守’, ‘VV’), (‘金炉’, ‘NN’), (‘的’, ‘DEC’), (‘童子’, ‘NN’), (’。’, ‘PU’)]
![]()
- “金角大王”在这里是人名,’平顶山’是地名,等词标记为NR,即专业名词;
“,”、“《”、“》”、标记为PU,即标点; - '是’标记为VC,即系动词
- “在”、“与”被标记为P,即介词;
- “电视剧”、“西游记”、“兄弟”等被标记为NN,即其他名词
- ‘中’,被标记为LC,即方位词
- ‘登场’,‘看守’等被标记为VV,即其他动词
- “的”,被标记为DEC,即补语标记
- …
(其实我感觉标记的还是不够准确,比如银角大王作为名字也应该跟金角大王一样合在一起标记为专有名词NR,莲花洞作为地名也应该被标记为NR吧)
3.3.3 命名实体
识别句子中具有特定意义的实体,如人名、机构名、日期、地名、时间、数量等,如:
Named Entities: [(‘金角大王’, ‘PERSON’), (’,’, ‘O’), (‘是’, ‘O’), (‘在’, ‘O’), (‘电视剧’, ‘O’), (’《’, ‘O’), (‘西游记’, ‘MISC’), (’》’, ‘O’), (‘中’, ‘O’), (‘登场’, ‘O’), (‘的’, ‘O’), (‘虚拟’, ‘O’), (‘人物’, ‘O’), (’。’, ‘O’), (‘与’, ‘O’), (‘兄弟’, ‘O’), (‘银角’, ‘O’), (‘大王’, ‘O’), (‘是’, ‘O’), (‘平顶山’, ‘CITY’), (‘莲花洞’, ‘LOCATION’), (‘的’, ‘O’), (‘两’, ‘NUMBER’), (‘个’, ‘O’), (‘妖怪’, ‘O’), (’。’, ‘O’), (‘原是’, ‘O’), (‘太上老君’, ‘O’), (‘门下’, ‘O’), (‘看守’, ‘O’), (‘金炉’, ‘O’), (‘的’, ‘O’), (‘童子’, ‘O’), (’。’, ‘O’)]
 - ‘金角大王’, ‘PERSON’,人
- ‘金角大王’, ‘PERSON’,人
- ‘平顶山’, ‘CITY’,城市
- ‘莲花洞’, ‘LOCATION’,位置
- ‘两’, ‘NUMBER’,数
- …
3.3.4 成分句法
也就是语法树,用来识别句子中的短语结构和短语间的层次关系,如:
Constituency Parsing: (ROOT
(IP
(NP (NR 金角大王))
(PU ,)
(VP (VC 是)
(NP
(CP
(IP
(VP
(PP (P 在)
(LCP
(NP
(NP (NN 电视剧))
(NP (PU 《) (NN 西游记) (PU 》)))
(LC 中)))
(VP (VV 登场))))
(DEC 的))
(ADJP (JJ 虚拟))
(NP (NN 人物))))
(PU 。)))
- (NP (NP (NN 电视剧)) (NP (PU 《) (NN 西游记) (PU 》))) 表示“电视剧《西游记》”被划分为名词短语,共同表示名词成分
- (LCP (NP (NP (NN 电视剧)) (NP (PU 《) (NN 西游记) (PU 》))) (LC 中))) 表示“电视剧《西游记》中”被划分为方位词短语,共同表示定位
- (PP (P 在) (LCP (NP (NP (NN 电视剧)) (NP (PU 《) (NN 西游记) (PU 》))) (LC 中))) 表示“在电视剧《西游记》中”被划分为介词短语
- …
3.3.5 依存句法
识别句子中词汇与词汇之间的依存关系,如主谓宾定状补等
Dependency Parsing: [(‘ROOT’, 0, 13), (‘dep’, 13, 1), (‘punct’, 13, 2), (‘cop’, 13, 3), (‘case’, 7, 4), (‘compound:nn’, 7, 5), (‘punct’, 7, 6), (‘nmod:prep’, 10, 7), (‘punct’, 7, 8), (‘case’, 7, 9), (‘acl’, 13, 10), (‘mark’, 10, 11), (‘amod’, 13, 12), (‘punct’, 13, 14), (‘ROOT’, 0, 11), (‘case’, 4, 1), (‘compound:nn’, 3, 2), (‘compound:nn’, 4, 3), (‘nmod:prep’, 11, 4), (‘cop’, 11, 5), (‘nmod:assmod’, 7, 6), (‘nmod:assmod’, 11, 7), (‘case’, 7, 8), (‘nummod’, 11, 9), (‘mark:clf’, 9, 10), (‘punct’, 11, 12), (‘ROOT’, 0, 3), (‘advmod’, 3, 1), (‘nsubj’, 3, 2), (‘acl’, 7, 4), (‘dobj’, 4, 5), (‘mark’, 4, 6), (‘dobj’, 3, 7), (‘punct’, 3, 8)]

3.4 启动CoreNLP服务器命令来调用stanfordcorenlp
在windows中,cmd进入到Stanford CoreNLP目录中再执行命令java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000
f: # 先进入放cornlp目录的盘
cd F:\coder\jars\stanford-corenlp-4.0.0 #这里是自己的cornlp解压的目录
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000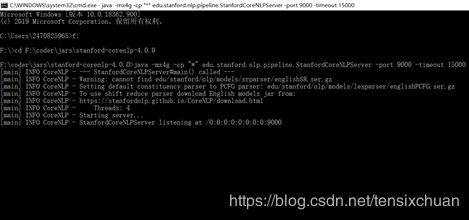
然后nlp = StanfordCoreNLP('http://localhost', port=9000) #通过服务器访问

或者直接在浏览器中输入localhost:9000/访问,这样可以得到更加直观的图像反映

术语速查:
ROOT:要处理文本的语句
IP:简单从句
NP:名词短语
VP:动词短语
PU:断句符,通常是句号、问号、感叹号等标点符号
LCP:方位词短语
PP:介词短语
CP:由‘的’构成的表示修饰性关系的短语
DNP:由‘的’构成的表示所属关系的短语
ADVP:副词短语
ADJP:形容词短语
DP:限定词短语
QP:量词短语
NN:常用名词
NR:固有名词
NT:时间名词
PN:代词
VV:动词
VC:是
CC:表示连词
VE:有
VA:表语形容词
AS:内容标记(如:了)
VRD:动补复合词
CD: 表示基数词
DT: determiner 表示限定词
EX: existential there 存在句
FW: foreign word 外来词
IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识
MD: modal auxiliary 情态助动词
PDT: pre-determiner 前位限定词
POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词
RB: adverb 副词
RBR: adverb, comparative 副词比较级
RBS: adverb, superlative 副词最高级
RP: particle 小品词
SYM: symbol 符号
TO:”to” as preposition or infinitive marker 作为介词或不定式标记
WDT: WH-determiner WH限定词
WP: WH-pronoun WH代词
WP$: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词
关系表示
abbrev: abbreviation modifier,缩写
acomp: adjectival complement,形容词的补充;
advcl : adverbial clause modifier,状语从句修饰词
advmod: adverbial modifier状语
agent: agent,代理,一般有by的时候会出现这个
amod: adjectival modifier形容词
appos: appositional modifier,同位词
attr: attributive,属性
aux: auxiliary,非主要动词和助词,如BE,HAVE SHOULD/COULD等到
auxpass: passive auxiliary 被动词
cc: coordination,并列关系,一般取第一个词
ccomp: clausal complement从句补充
complm: complementizer,引导从句的词好重聚中的主要动词
conj : conjunct,连接两个并列的词。
cop: copula。系动词(如be,seem,appear等),(命题主词与谓词间的)连系
csubj : clausal subject,从主关系
csubjpass: clausal passive subject 主从被动关系
dep: dependent依赖关系
det: determiner决定词,如冠词等
dobj : direct object直接宾语
expl: expletive,主要是抓取there
infmod: infinitival modifier,动词不定式
iobj : indirect object,非直接宾语,也就是所以的间接宾语;
mark: marker,主要出现在有“that” or “whether”“because”, “when”,
mwe: multi-word expression,多个词的表示
neg: negation modifier否定词
nn: noun compound modifier名词组合形式
npadvmod: noun phrase as adverbial modifier名词作状语
nsubj : nominal subject,名词主语
nsubjpass: passive nominal subject,被动的名词主语
num: numeric modifier,数值修饰
number: element of compound number,组合数字
parataxis: parataxis: parataxis,并列关系
partmod: participial modifier动词形式的修饰
pcomp: prepositional complement,介词补充
pobj : object of a preposition,介词的宾语
poss: possession modifier,所有形式,所有格,所属
possessive: possessive modifier,这个表示所有者和那个’S的关系
preconj : preconjunct,常常是出现在 “either”, “both”, “neither”的情况下
predet: predeterminer,前缀决定,常常是表示所有
prep: prepositional modifier
prepc: prepositional clausal modifier
prt: phrasal verb particle,动词短语
punct: punctuation,这个很少见,但是保留下来了,结果当中不会出现这个
purpcl : purpose clause modifier,目的从句
quantmod: quantifier phrase modifier,数量短语
rcmod: relative clause modifier相关关系
ref : referent,指示物,指代
rel : relative
root: root,最重要的词,从它开始,根节点
tmod: temporal modifier
xcomp: open clausal complement
xsubj : controlling subject 掌控者
中心语为谓词
subj — 主语
nsubj — 名词性主语(nominal subject) (同步,建设)
top — 主题(topic) (是,建筑)
npsubj — 被动型主语(nominal passive subject),专指由“被”引导的被动句中的主语,一般是谓词语义上的受事 (称作,镍)
csubj — 从句主语(clausal subject),中文不存在
xsubj — x主语,一般是一个主语下面含多个从句 (完善,有些)
中心语为谓词或介词
obj — 宾语
dobj — 直接宾语 (颁布,文件)
iobj — 间接宾语(indirect object),基本不存在
range — 间接宾语为数量词,又称为与格 (成交,元)
pobj — 介词宾语 (根据,要求)
lobj — 时间介词 (来,近年)
中心语为谓词
comp — 补语
ccomp — 从句补语,一般由两个动词构成,中心语引导后一个动词所在的从句(IP) (出现,纳入)
xcomp — x从句补语(xclausal complement),不存在
acomp — 形容词补语(adjectival complement)
tcomp — 时间补语(temporal complement) (遇到,以前)
lccomp — 位置补语(localizer complement) (占,以上)
— 结果补语(resultative complement)
中心语为名词
mod — 修饰语(modifier)
pass — 被动修饰(passive)
tmod — 时间修饰(temporal modifier)
rcmod — 关系从句修饰(relative clause modifier) (问题,遇到)
numod — 数量修饰(numeric modifier) (规定,若干)
ornmod — 序数修饰(numeric modifier)
clf — 类别修饰(classifier modifier) (文件,件)
nmod — 复合名词修饰(noun compound modifier) (浦东,上海)
amod — 形容词修饰(adjetive modifier) (情况,新)
advmod — 副词修饰(adverbial modifier) (做到,基本)
vmod — 动词修饰(verb modifier,participle modifier)
prnmod — 插入词修饰(parenthetical modifier)
neg — 不定修饰(negative modifier) (遇到,不)
det — 限定词修饰(determiner modifier) (活动,这些)
possm — 所属标记(possessive marker),NP
poss — 所属修饰(possessive modifier),NP
dvpm — DVP标记(dvp marker),DVP (简单,的)
dvpmod — DVP修饰(dvp modifier),DVP (采取,简单)
assm — 关联标记(associative marker),DNP (开发,的)
assmod — 关联修饰(associative modifier),NP|QP (教训,特区)
prep — 介词修饰(prepositional modifier) NP|VP|IP(采取,对)
clmod — 从句修饰(clause modifier) (因为,开始)
plmod — 介词性地点修饰(prepositional localizer modifier) (在,上)
asp — 时态标词(aspect marker) (做到,了)
partmod– 分词修饰(participial modifier) 不存在
etc — 等关系(etc) (办法,等)
中心语为实词
conj — 联合(conjunct)
cop — 系动(copula) 双指助动词????
cc — 连接(coordination),指中心词与连词 (开发,与)
其它
attr — 属性关系 (是,工程)
cordmod– 并列联合动词(coordinated verb compound) (颁布,实行)
mmod — 情态动词(modal verb) (得到,能)
ba — 把字关系
tclaus — 时间从句 (以后,积累)
— semantic dependent
cpm — 补语化成分(complementizer),一般指“的”引导的CP (振兴,的)
…
缩写:
链接: https://pan.baidu.com/s/1eRJlbBg5-om923n4DDDH2A 提取码: qcw3
汇报ppt:
链接: https://pan.baidu.com/s/1IhQbDsrXm96iNOCh2wbc2A 提取码: cw2j
参考资料:
CoreNLP官网教程
Stanford CoreNLP在python3中的安装使用+词性学习
斯坦福大学Stanford coreNLP 宾州树库依存句法标注体系
宾州中文树库词性标注指南 The Part-Of-Speech Tagging Guidelines for the Penn Chinese Treebank
链接:https://pan.baidu.com/s/1167iB6S4XsZYR-ZFwyHWrw
提取码:5zoj
最后,码字不易,吐血整理的干货长文,如果有帮助的话可以点个赞呀,给你小心心~
![]()
