OpenCV+OpenGL 双目立体视觉三维重建
0.绪论
这篇文章主要为了研究双目立体视觉的最终目标——三维重建,系统的介绍了三维重建的整体步骤。双目立体视觉的整体流程包括:图像获取,摄像机标定,特征提取(稠密匹配中这一步可以省略),立体匹配,三维重建。我在做双目立体视觉问题时,主要关注的点是立体匹配,本文主要关注最后一个步骤三维重建中的:三角剖分和纹理贴图以及对应的OpenCV+OpenGL代码实现。
1.视差计算
1.1基于视差信息的三维重建
特征提取
由双目立体视觉进行三位重建的第一步是立体匹配,通过寻找两幅图像中的对应点获取视差。OpenCV 中的features2d库中包含了很多常用的算法,其中特征点定位的算法有FAST, SIFT, SURF ,MSER, HARRIS等,特征点描述算法有SURF, SIFT等,还有若干种特征点匹配算法。这三个步骤的算法可以任选其一,自由组合,非常方便。经过实验,选择了一种速度、特征点数量和精度都比较好的组合方案:FAST角点检测算法+SURF特征描述子+FLANN(Fast Library for Approximate Nearest Neighbors) 匹配算法。
在匹配过程中需要有一些措施来过滤误匹配。一种比较常用的方法是比较第一匹配结果和第二匹配结果的得分差距是否足够大,这种方法可以过滤掉一些由于相似造成的误匹配。还有一种方法是利用已经找到的匹配点,使用RANSAC算法求得两幅视图之间的单应矩阵,然后将左视图中的坐标P用单应矩阵映射到右视图的Q点,观察与匹配结果Q’的欧氏距离是否足够小。当然由于图像是具有深度的,Q与Q’必定会有差距,因此距离阈值可以设置的稍微宽松一些。我使用了这两种过滤方法。
另外,由于图像有些部分的纹理较多,有些地方则没有什么纹理,造成特征点疏密分布不均匀,影响最终重建的效果,因此我还采取了一个措施:限制特征点不能取的太密。如果新加入的特征点与已有的某一特征点距离太小,就舍弃之。最终匹配结果如下图所示,精度和均匀程度都较好。

代码:
// choose the corresponding points in the stereo images for 3d reconstruction
void GetPair( Mat &imgL, Mat &imgR, vector detector = FeatureDetector::create( DETECTOR_TYPE ); // factory mode
vector de = DescriptorExtractor::create( DESCRIPTOR_TYPE );
//SurfDescriptorExtractor de(4,2,true);
de->compute( imgL, keypointsL, descriptorsL );
de->compute( imgR, keypointsR, descriptorsR );
tt = ((double)getTickCount() - tt)/getTickFrequency(); // 620*555 pic, about 2s for SURF, 120s for SIFT
Ptr matcher = DescriptorMatcher::create( MATCHER_TYPE );
vector<vectorvector<char> matchesMask( passedMatches.size(), 0 );
int cnt = 0;
for( size_t i1 = 0; i1 < ptsLtemp.size(); i1++ )
{
Point2f prjPtR = ptsLt.at((int)i1,0); // prjx = ptsLt.at((int)i1,0), prjy = ptsLt.at((int)i1,1);
// inlier
if( abs(ptsRtemp[i1].x - prjPtR.x) < HOMO_FILTER_TH &&
abs(ptsRtemp[i1].y - prjPtR.y) < 2) // restriction on y is more strict
{
vector p.s. 源代码中的基于特征点的视差计算有点问题,还在调试中,希望有经验的大牛共同解决一下。
最新回复,特别鸣谢大神:G3fire(update 20180718)
代码在opencv2.4.9版本下运行的,由于SIFT和SURF的专利约束需要nofree的引用.
在Reconstuction3d.cpp中添加initModule_nonfree();
同样在head.h中添加
#pragma comment(lib,"opencv_nonfree249d.lib"),
把Algorithm g_algo 改成= FEATURE_PT
就可以运行基于特征点的视差计算了
楼24的修改特征点检测的创建方法没有运行通特别感谢24楼的回复
博主的特征点匹配这边运行时会崩溃,我用VS2013+opencv2.4.10版本,然后修改特征点检测的创建方法就可以用了。
例如:
SurfFeatureDetector detector;
detector.detect(imgL1, keypointsL);
detector.detect(imgR1, keypointsR);1.2基于块匹配的视差计算
上面提取特征点的过程中实际上忽略了一个辅助信息:对应点应当是取在对应极线上的一个区间内的。利用这个信息可以大幅简化对应点的匹配,事实上只要用L1距离对一个像素周围的block计算匹配距离就可以了,也就是OpenCV中实现的块匹配算法的基本思路。比起特征点匹配,这是一种“稠密”的匹配算法,精度也可以接受。下图中浅色表示视差较大,对应深度较浅。左侧有一块区域是左右视图不相交的部分,因此无法计算视差。

可以发现视差计算结果中有很多噪声。事实上在纹理平滑的区域,还有左右视图中不同遮挡的区域,是很难计算视差的。因此我利用最近邻插值和数学形态学平滑的方法对视差图进行了修复(见cvFuncs2.cpp中的FixDisparity函数):

// roughly smooth the glitches on the disparity map
void FixDisparity( Mat_<float> & disp, int numberOfDisparities )
{
Mat_<float> disp1;
float lastPixel = 10;
float minDisparity = 23;// algorithm parameters that can be modified
for (int i = 0; i < disp.rows; i++)
{
for (int j = numberOfDisparities; j < disp.cols; j++)
{
if (disp(i,j) <= minDisparity) disp(i,j) = lastPixel;
else lastPixel = disp(i,j);
}
}
int an = 4; // algorithm parameters that can be modified
copyMakeBorder(disp, disp1, an,an,an,an, BORDER_REPLICATE);
Mat element = getStructuringElement(MORPH_ELLIPSE, Size(an*2+1, an*2+1));
morphologyEx(disp1, disp1, CV_MOP_OPEN, element);
morphologyEx(disp1, disp1, CV_MOP_CLOSE, element);
disp = disp1(Range(an, disp.rows-an), Range(an, disp.cols-an)).clone();
}对应点的选取
上面提到,为了获得较好的重构效果,特征点最好取在深度变化较大的区域。基于这种猜想,我首先对上面的视差图求梯度,然后找到梯度最大的点,观察梯度的方向,如果是偏x方向,就在该点左右若干像素各取一个点;否则就在上下若干像素各取一个点。然后根据这两个点的视差值就可以计算出另外一个视图中的对应点的坐标。特征点还不能分布过密,因此我取完一对特征点后,将其周围一圈像素的梯度置零,然后在寻找下一个梯度最大值,这样一直下去,直到取够特征点数。
特征点也不能全取在深度变化剧烈的区域,在平坦的区域也可以取一些。最终我取的特征点如下图:

其中紫色的点是在较平坦的区域取到的,其他颜色是在边界区域取到的。这些算法实现在ChooseKeyPointsBM函数中。
2.计算世界坐标
一般双目立体视觉中使用的实验图像都是经过外极线矫正的,计算3D坐标也比较方便,其实利用外极线约束(以及其他的约束条件)可以极大的降低立体匹配的计算量。见下图:

如果(x1,y1),(x2,y2)用各自图像上的像素坐标表示,L和(X,Y,Z)用毫米表示,f用像素表示的话,用相似三角形的知识就可以推出:

其中W和H是图像的宽高(像素数),y是y1和y2的均值,Z加负号是为了保持右手坐标系,而Y加负号是由于图像成像过程中上下发生了倒转。三维世界原点取为左摄像机的焦点。计算的代码见cvFunc.cpp中的StereoTo3D函数。
// calculate 3d coordinates.
// for rectified stereos: pointLeft.y == pointRight.y
// the origin for both image is the top-left corner of the left image.
// the x-axis points to the right and the y-axis points downward on the image.
// the origin for the 3d real world is the optical center of the left camera
// object -> optical center -> image, the z value decreases.
void StereoTo3D( vector3.三角剖分
3.1 三角剖分简介
三角剖分是为了之后的纹理贴图,我用了OpenCV中的Delaunay三角剖分函数,这种剖分算法的可以使所形成的三角形的最小角最大。剖分的示例如下:

OpenCV使用Delaunay算法将平面分割成小的三角形区域(该三角形确保包括所有的分割点)开始不断迭代完成。在这种情况下,对偶划分就是输入的二维点集的Voronoi图表。这种划分可以用于对一个平面进行三维分段变换、形态变换、平面点的快速 定位以及建立特定的图结构(如NNG,RNG)。

同时由表可以看出,三角网生成法的时间效率最低,分治算法的时间效率最高,逐点插入法效率居中。
3.2 Bowyer-Watson算法
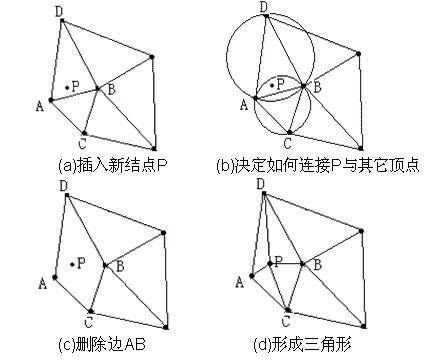
目前采用逐点插入方式生成的Delaunay三角网的算法主要基于Bowyer-Watson算法,Bowyer-Watson算法的主要步骤如下:
1)建立初始三角网格:针对给定的点集V,找到一个包含该点集的矩形R,我们称R为辅助窗口。连接R的任意一条对角线,形成两个三角形,作为初始Delaunay三角网格。
2)逐点插入:假设目前已经有一个Delaunay三角网格T,现在在它里面再插入一个点P,需要找到该点P所在的三角形。从P所在的三角形开始,搜索该三角形的邻近三角形,并进行空外接圆检测。找到外接圆包含点P的所有的三角形并删除这些三角形,形成一个包含P的多边形空腔,我们称之为Delaunay空腔。然后连接P与Delaunay腔的每一个顶点,形成新的Delaunay三角网格。
3)删除辅助窗口R:重复步骤2),当点集V中所有点都已经插入到三角形网格中后,将顶点包含辅助窗口R的三角形全部删除。
在这些步骤中,快速定位点所在的三角形、确定点的影响并构建Delaunay腔的过程是每插入一个点都会进行的。随着点数的增加,三角形数目增加很快,因此缩短这两个过程的计算时间,是提高算法效率的关键。
算法执行图示如下:
3.3 三角剖分代码分析
三角剖分的代码见cvFuncs.cpp中的TriSubDiv函数,我将特征点存储到一个vector变量中,剖分结果存储到一个vector变量中,Vec3i中存储的是3个表示顶点编号的整数。
我们需要存储Delaunay的内存空间和一个外接矩形(该矩形盒子用来确定虚拟三角形)
// STORAGE AND STRUCTURE FOR DELAUNAY SUBDIVISION //存储和结构 for三角剖分
//
CvRect rect = { 0, 0, 600, 600 }; //Our outer bounding box //我们的外接边界盒子
CvMemStorage* storage; //Storage for the Delaunay subdivsion //用来存储三角剖分
storage = cvCreateMemStorage(0); //Initialize the storage //初始化存储器
CvSubdiv2D* subdiv; //The subdivision itself // 细分
subdiv = init_delaunay( storage, rect); //See this function below //函数返回CvSubdiv类型指针
init_delaunay函数如下,它是一个OpenCV函数,是一个包含一些OpenCV函数的函数包。//INITIALIZATION CONVENIENCE FUNCTION FOR DELAUNAY SUBDIVISION //为三角剖分初始化便利函数
//
CvSubdiv2D* init_delaunay(CvMemStorage* storage,CvRect rect) {
CvSubdiv2D* subdiv;
subdiv = cvCreateSubdiv2D(CV_SEQ_KIND_SUBDIV2D,sizeof(*subdiv),sizeof(CvSubdiv2DPoint),sizeof(CvQuadEdge2D),storage);//为数据申请空间
cvInitSubdivDelaunay2D( subdiv, rect ); //rect sets the bounds
return subdiv;//返回申请空间的指针
} 我们知道三角剖分是对散点集进行处理的,我们知道了散点集就可以获得点集的三角剖分。如何传入(插入)散点集呢?
这些点必须是32位浮点型,并通过下面的方式插入点:
CvPoint2D32f fp; //This is our point holder//这是我们点的持有者(容器)
for( i = 0; i < as_many_points_as_you_want; i++ ) {
// However you want to set points //如果我们的点集不是32位的,在这里我们将其转为CvPoint2D32f,如下两种方法。
//
fp = your_32f_point_list[i];
cvSubdivDelaunay2DInsert( subdiv, fp );
} 转换为CvPoint2D32f的两种方法:
1)通过宏cvPoint2D32f(double x,double y)
2)通过cxtype.h下的cvPointTo32f(CvPoint point)函数将整形点方便的转换为32位浮点型。
当可以通过输入点(散点集)得到Delaunay三角剖分后,接下来,我们用一下两个函数设置和清除相关的Voronoi划分:
cvCalcSubdivVoronoi2D( subdiv ); // Fill out Voronoi data in subdiv //在subdiv中填充Vornoi的数据
cvClearSubdivVoronoi2D( subdiv ); // Clear the Voronoi from subdiv//从subdiv中清除Voronoi的数据 CvSubdiv2D结构如下:
#define CV_SUBDIV2D_FIELDS() \
CV_GRAPH_FIELDS() \
int quad_edges; \
int is_geometry_valid; \
CvSubdiv2DEdge recent_edge; \
CvPoint2D32f topleft; \
CvPoint2D32f bottomright;
typedef struct CvSubdiv2D
{
CV_SUBDIV2D_FIELDS()
}
CvSubdiv2D; #define CV_GRAPH_FIELDS() \
CV_SET_FIELDS() /* set of vertices */ \
CvSet *edges; /* set of edges */ #define CV_SET_FIELDS() \
CV_SEQUENCE_FIELDS() /*inherits from [#CvSeq CvSeq] */ \
struct CvSetElem* free_elems; /*list of free nodes */ 整体代码如下:
void TriSubDiv( vector平面划分是将一个平面分割为一组不重叠的、能够覆盖整个平面的区域。结构CvSubdiv2D描述了建立在二维点集上的划分结构,其中点集互相连接且构成平面图形,该图形通过结合一些无线连接外部划分点(称为凸形点)的边缘,将一个平面用按照其边缘划分成很多小区域。
对于每一个划分操作,都有一个对偶划分与之对应。对偶的意思是小区域与点(划分的顶点)变换角色,即在对偶划分中,小区域被当做一个顶点(以下称为虚拟点)而原始的划分顶点被当做小区域。如下图所示,原始的划分用实线表示,而对偶划分用虚线表示。
4.三维重构
为了保证三维重建的效果,一般地要对深度图像进行后续处理。要从深度图像中恢复高质量的视差图,对深度图像的要求有:
①深度图像中,物体的边界必需与图像中物体的边界对齐;
②在场景图中,深度图像要尽可能均勻和平滑,即对图像进行平滑处理。
三维重构的思路很简单,用OpenGL中纹理贴图功能,将平面图像中的三角形逐个贴到计算出的三维坐标上去就可以了。为了便于观察3D效果,我还设计了交互功能:用方向键可以上下左右旋转重构的模型,用鼠标滚轮可以放大或缩小。用gluLookAt函数可以实现视点旋转的功能。三维重构的代码实现在glFuncs.cpp中。
纹理贴图:
GLuint Create3DTexture( Mat &img, vector::iterator iterPts3D = pts3D.begin();
Point2f pt2D[3];
Point3f pt3D[3];
glDisable(GL_BLEND);
glEnable(GL_TEXTURE_2D);
for ( ; iterTri != tri.end(); iterTri++)
{
Vec3i &vertices = *iterTri;
int ptIdx;
for (int i = 0; i < 3; i++)
{
ptIdx = vertices[i];
if (ptIdx == -1) break;
//else cout<
pt2D[i].x = pts2DTex[ptIdx].x / img.cols;
pt2D[i].y = pts2DTex[ptIdx].y / img.rows;
pt3D[i] = (pts3D[ptIdx] - center3D) * (1.f / max(size3D[0],size3D[1]));
//pt3D[i].z -= offset;
}
if (ptIdx != -1)
{
MapTexTri(texImg, pt2D, pt3D);
//cout<
}
}
glDisable(GL_TEXTURE_2D);
glEndList();
return tex;
} 效果展示及不足
Cloth图像是重构效果比较好的一组:

可以比较明显的看出3D效果,也比较符合直觉。然而其他图像效果就差强人意了:

仔细分析造成这种效果的原因,一方面,特征点的匹配可能有些误差,造成3D坐标的计算不太精确,但大部分坐标还是准确的。另一方面,左右视图可能会有不同的遮挡、偏移等情况,因此匹配得到的特征点可能实际上并不是3维世界中的同一点,这种误差是无法消除的。但造成效果变差的最重要的原因,还是图像中深度变化较大,而特征点选取的比较稀疏,因此正面看还比较正常,一旦旋转纹理就显得扭曲变形了。为了解决这个问题,应当试图把特征点取到深度变化较剧烈的地方,一般是图像中的边界处。然而特征点检测一般都检测出的是角点和纹理密集的区域,因此可以考虑更换对应点匹配的方法。
如果要进一步改进效果,可以先对视差图像进行分割,将图像分成视差比较连续的几块区域分别贴图,视差变化剧烈的区域就不必把扭曲的纹理贴上去了。我尝试了以下分割的效果,如下图所示,应该可以达到更好的效果,不过由于时间所限,就没有进一步实现下去了。
关于上面实现的两种求取视差的算法,在main函数的前面设置了一个变量g_algo,可以用来切换不同的算法。
参考文献:
立体匹配原理:
http://blog.csdn.net/wangyaninglm/article/details/51533549
http://blog.csdn.net/wangyaninglm/article/details/51531333
三维重建原理:http://blog.csdn.net/wangyaninglm/article/details/51558656
http://blog.csdn.net/wangyaninglm/article/details/51558310
三角剖分原理:http://blog.csdn.net/newthinker_wei/article/details/45598769
http://www.learnopencv.com/delaunay-triangulation-and-voronoi-diagram-using-opencv-c-python/
这篇文章其实主要是针对早期下到的一个代码和文档的总结,和一些个人资料的总结,由于时间比较早,找不到出处了,如果原作者看到了觉的不妥,那我就把它改成转载啦,嘿嘿嘿。
代码下载
CSDN: http://download.csdn.net/detail/wangyaninglm/9597622
github:https://github.com/wynshiter/OpenCV-OpenGL–Reconstuction3d