ANR问题全解析
大部分做安卓的小伙伴相信对于ANR一定不陌生,相比于发生应用程序崩溃,发生ANR更加让人头大,主要原因是崩溃发生的时候会在Logcat中打印出发生异常的位置,开发人员很容易就能定位到崩溃并解决,显然ANR没那么轻松;但是我们大可不必这么忧伤,因为绝大部分ANR都是很容易解决的,只是我们没找到方法而已;
首先要搞定ANR就要对他有一个根本性的认识,和我们了解任何事物一样,只有抓住了事物之根本,才能在应对各种各样复杂的场景时保持镇定,运筹帷幄;
认识问题
那什么是ANR呢?我总结过来说就是Google为了让应用足够快的响应用户引入的一套机制,当主线程的UI绘制变慢的时候就可能导致ANR异常;不过这些基础知识对于各位看官来说都是小儿科了,我们就直奔主题,是什么导致应用程序出现ANR异常,而我们又应该怎么灵巧应对这些异常呢?
我这里给出一个官方的解释,其实我很鼓励大家在遇到问题的时候先看官方文档,因为官方的解释最能抓住问题的根本,与其说这是一种方法,倒不如说是一种解决问题的思维方式;
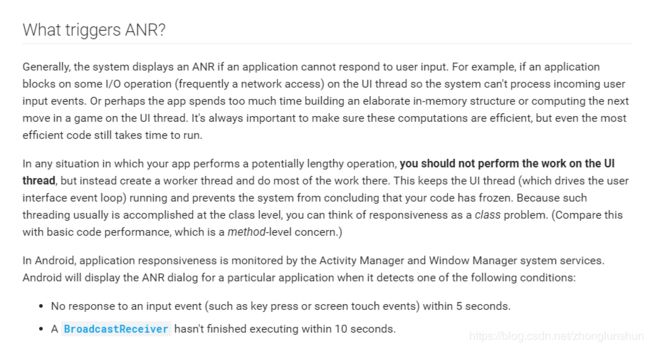
官方标出了重点,就是不要在主线程上做耗时操作,不过我们在解Bug的时候发现远比这一句话来得复杂,及时我们尽量不让主线程执行耗时操作,也会遇到一些头疼的ANR场景,这个是我们今天要解决的重点;
我简单的把这些场景氛围3类:
- KeyDispatchTimeout(主要类型)
按键或触摸事件在特定时间内无响应,谷歌default 5s,MTK平台上是8s;其实这个很好理解,第一种是和用户交互的时候出现的,能和用户直接交互的界面就是运行在主线程上,当程序无法响应用户的交互事件,自然会抛出来ANR; - BroadcastTimeout(10s)
BroadcastReceiver在特定时间内无法处理完成,因为Broadcast是跑在主线程上的,而且Broadcast的生命周期只有10s,10s没有做完就会被安卓系统认为出现了ANR异常; - ServiceTimeout(20s) --小概率类型
Service在特定的时间内无法处理完成,Service是跑在主线程上的,这种情况出现的不多,我相信大部分开发人员能规避这种情景;
解决问题
我想在这里给大家一个解决这类问题的一般思路,基本上顺着这个方法能解决绝大部分的ANR问题;
第一步:获取ANR日志
ANR产生时, 系统会生成一个traces.txt的文件放在/data/anr/下.,这个文件里面保存了产生ANR的相关日志,可以通过adb命令将其导出到本地:
$adb pull data/anr/traces.txt .
获取日志有一点需要注意,发生ANR后,不要选择结束进程,因为这样AMS会kill掉该进程,有些信息会打印不出来(比如MTK平台上会生成db.XX.ANR,写入到aee_exp文件夹下需要时间),最好是ANR发生后等两三分钟左右,再获取日志;
有些时候我们仅仅通过traces.txt无法准确定位到ANR产生的原因,这个时候还需要一些日志辅助定位,以MTK为例,需要如下日志信息:
1.aee_exp文件夹(MTK日志目录下,发生ANR会生成)
2.MTK目录下的mobilelog文件夹
这里的aee_exp文件夹一般都是需要的, 对DB进行dump解析,得到ANR发生时场景信息,比如主线程callstack,CPU,memory等,在分析比较难的ANR问题时很关键。
第二步:分析日志
找到日志后,我们需要通过日志快速定位到问题,我解决问题的思路是从我最常见到的问题入手,尽可能少的通过关键资料得到问题结果,如果不能再复杂化;这样做是为了节省时间,我可不想每次分析一个ANR就分析一遍堆栈占用,Cpu线程等等,这样很容易让人搞不清楚主次而浪费时间;
下面是我分析日志的常规思路,当然如果你有更好的方法欢迎指正;
第一类:能直接从traces.txt .看出原因的ANR
![]()
你看,人家说的很明白了,界面都没出来,点了肯定是没办法响应的,这种情况下一般是在Application或者Activity创建的时候做了耗时操作,因此规避方法也很简单就是尽可能把耗时操作挪到子线程去做;
第二类 主线程做了耗时操作
虽然第一类也是属于这种,但是区别在于这一类问题一般发生在应用运行过程中,这种情况是ANR类型问题里遇到最多的,比如网络访问,访问数据库之类的,都很容易造成主线程堵塞;
我解决这类问题的时候不是直接看tractView.txt,因为android studio提供了一个非常好的性能分析工具供我们跟踪这个问题,我们只需要打开android studio的性能分析页面:
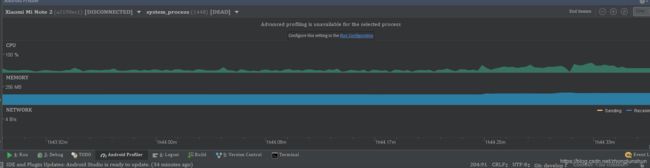
进入到Cpu页面,第一个线程就是主线程,我们只要看主线程上cpu的占用(绿色块)就知道在什么时候要发生ANR了,因为发生ANR的时候,主线程会有很大块的绿色占用,我们使用录制工具,录制这段时间的cpu占用,就可以很快定位到问题,这一类的教程很多,我这里不再赘述;
第三类:死锁导致ANR
这类问题相比前两类要麻烦一些,很多初级开发是不知道的;
首先我们要确定ANR的发生时因为用户点击还是自己就发生了,因为如果测试人员没有点击就发生了ANR,那很可能是出现了死锁,死锁在日志上的表现是很直接的,因为我们知道死锁导致的ANR的根源是是因为一个线程持有了锁主线程在等待这个线程释放锁;当等待时间一场,必然发生ANR;
这种情况下我们直接在日志里面找下面这些字样:
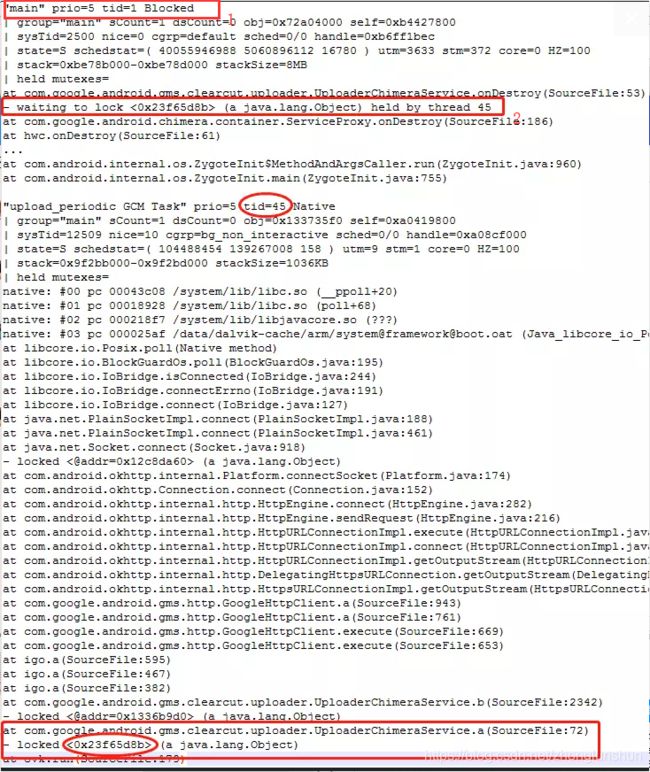
大家看我标红的位置,一看就知道是这里主线程阻塞了,原因是在等待45号线程持有的锁释放;通常这个时候还会在上面打印出来是发生在哪一行代码中,这个时候我们定位到对应的代码,再去解决这个问题就相当容易;
第四类:卡IO
这种情况一般是和文件操作相关,判断是否是这种情况,可以看mainlog中搜索关键字"ANR in",看这段信息的最下边,比如下面的信息
ANRManager: 100% TOTAL: 2% user + 2.1% kernel + 95% iowait + 0.1% softirq
很明显,IO占比很高,这个时候就需要查看trace日志看当时的callstack,或者在这段ANR点往前看0~4s,看看当时做的什么文件操作,这种场景有遇到过,常见解决方法是对耗时文件操作采取异步操作;
第五类:Binder线程池被占满
这一类问题出现的很少见,但是少不代表没有;
系统对每个process最多分配15个binder线程,这个是谷歌的设计(/frameworks/native/libs/binder/ProcessState.cpp)
如果另一个process发送太多重复binder请求,那么就会导致接收端binder线程被占满,从而处理不了其它的binder请求
这本身就是系统的一个限制,如果应用未按照系统的要求来实现对应逻辑,那么就会造成问题。
而系统端是不会(也不建议)通过修改系统行为来兼容应用逻辑,否则更容易造成其它根据系统需求正常编写的应用反而出现不可预料的问题。
判断Binder是否用完,可以在trace中搜索关键字"binder_f",如果搜索到则表示已经用完,然后就要找log其他地方看是谁一直在消耗binder或者是有死锁发生
之前有遇到过压力测试手电筒应用,出现BInder线程池被占满情况,解决的思路就是降低极短时间内大量Binder请求的发生,修复的手法是发送BInder请求的函数中做时间差过滤,限定在500ms内最多执行一次;
第六类:主线程Binder调用等待超时
一般是上面的我发现都不好使了,我才会使用这种方案,大家看一下下面这段:

很明显当时在做Binder通信,并没有waiting to lock等代表死锁的字样,那么说明这个案例即有可能是在等Binder对端响应,我们知道Binder通信对于发起方来说是阻塞等待响应,只有有了返回结果后才会继续执行下去
所以,如上这个案例中需要找到对端是哪个进程,这个进程当时在做什么,这时候就需要找到anr文件夹下另外一个文件binderinfo,这里需要找到与我们发起方进程1461通信的是哪个进程;

可以看到是1666号这个进程,再回到trace中看下,这个进程当时在做什么

可以看到当时对端在做消息的读取,也就是说这里出了问题,很明显这里我们无法修改,我们这个问题在于主线程执行了Binder请求,对端迟迟未返回便很容易出现这个问题,当前做法异步中执行;