大数据_实时数据处理(Flume+Kafka+Sparkstreaming)
版本:
kafka的版本:kafka_2.11-0.11.0.0
spark的版本:spark-2.3.1-bin-hadoop2.6
flume的本班:apache-flume-1.7.0-bin
实现目的:
采集实时生成的日志数据,通过flume将数据传递给kafka 做缓冲,由spark streaming做数据处理入库
具体代码的实现:
可以通过Java测试代码生成日志
flume采集的配置
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = master
a1.sources.r1.port = 4141
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test1
a1.sinks.k1.kafka.bootstrap.servers = master:9092
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
>>>>>>>>>>>>>>>>>>>>>>>kafka对接sparkstreaming并实时更新mysql中的数据
object test2 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("sparkflume").setMaster("local[2]")
val ssc=new StreamingContext(conf,Seconds(1))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.126.129:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "test-consumer-group",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
》》》获取mysql对应用户的money,然后做修改
val topics = Array("test1")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val dStream1 = stream.map {
x => {
var a=x.value().split(":")
val conn = DB.getConnection //ConnectPoolUtil是我创建的一个数据库连接池,getConnection是它的一个方法
conn.setAutoCommit(false) //设为手动提交
val stmt = conn.createStatement()
//查询数值
var m=0;
var rs= stmt.executeQuery("select test.money from money test where test.username='"+a(0)+"'")
// select user0_.id as id1_, user0_.username as username1_, user0_.password as password1_ from user user0_ where user0_.username=’Haha‘
while(rs.next){
m= rs.getInt(1)//等价于rs.getInt("id");
}
if(a(1).substring(0,1).equals("-")){
if((m - a(1).substring(1).toInt)<0){
m=0;
}else{
m= m - a(1).substring(1).toInt
}
}else{
m= m+a(1).substring(1).toInt
}
stmt.addBatch("update money set money="+m+" where username='"+a(0)+"'")
stmt.executeBatch()
conn.commit()
conn.close()
}
}
dStream1.print()
// stream.map(s =>(s.key(),s.value())).print();
ssc.start()
ssc.awaitTermination()
}
}
mysql的数据表:
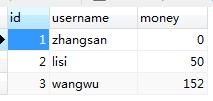
数据库连接
object DB { private var bs:BasicDataSource = null
/**
* 创建数据源
* @return
*/
def getDataSource():BasicDataSource={
if(bs==null){
bs = new BasicDataSource()
bs.setDriverClassName("com.mysql.jdbc.Driver")
bs.setUrl("jdbc:mysql://IP/test")
bs.setUsername("root")
bs.setPassword("mysql")
bs.setMaxActive(200) //设置最大并发数
bs.setInitialSize(30) //数据库初始化时,创建的连接个数
bs.setMinIdle(50) //最小空闲连接数
bs.setMaxIdle(200) //数据库最大连接数
bs.setMaxWait(1000)
bs.setMinEvictableIdleTimeMillis(60*1000) //空闲连接60秒中后释放
bs.setTimeBetweenEvictionRunsMillis(5*60*1000) //5分钟检测一次是否有死掉的线程
bs.setTestOnBorrow(true)
}
bs
}
/**
* 释放数据源
*/
def shutDownDataSource(){
if(bs!=null){
bs.close()
}
}
/**
* 获取数据库连接
* @return
*/
def getConnection():Connection={
var con:Connection = null
try {
if(bs!=null){
con = bs.getConnection()
}else{
con = getDataSource().getConnection()
}
} catch{
case e:Exception => println(e.getMessage)
}
con
}
/**
* 关闭连接
*/
def closeCon(rs:ResultSet ,ps:PreparedStatement,con:Connection){
if(rs!=null){
try {
rs.close()
} catch{
case e:Exception => println(e.getMessage)
}
}
if(ps!=null){
try {
ps.close()
} catch{
case e:Exception => println(e.getMessage)
}
}
if(con!=null){
try {
con.close()
} catch{
case e:Exception => println(e.getMessage)
}
}
}
}
》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》
启动
### 1.开启hdfs
$HADOOP_HOME/sbin/start-dfs.sh &
###2.开启spark
$SPARK_HOME/sbin/start-all.sh &
###3.开启zookeeeper
$KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties &
###4.开启kafka
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties &
###5.开启flume流程
#$FLUME_HOME/bin/flume-ng agent --conf conf --conf-file $FLUME_HOME/conf/example.conf --name a1 -Dflume.root.logger=INFO,console
###6.启动日志生成代码或jar
###7.启动sparkStreaming程序
###8.打开页面的连接
搭建这段代码主要遇见的问题:不报错,不打印,原因很多都是因为kafka的配置或者版本

我更换了版本,并且kafka的配置文件中
listeners=PLAINTEXT://:9092添加了ip
listeners=PLAINTEXT://192.168.126.129:9092
注意如果困到这一步,先尝试写scala往kafka中写数据,和取数据做测试,直到测通,那么sparkstreaming
就一定能取kafka中的数据了
测试写入:
package com.itstar;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
/**
* @AUTHOR COCO
* 2018/8/2
**/
public class KafkaProducer extends Thread{
private String topic;
private Producer producer;
public KafkaProducer(String topic) {
this.topic = topic;
Properties properties=new Properties();
properties.put("metadata.broker.list","192.168.126.129:9092");
properties.put("serializer.class", "kafka.serializer.StringEncoder");
properties.put("request.required.acks","1");
producer=new Producer(new ProducerConfig(properties));
}
@Override
public void run(){
int m=1;
while(true){
String message="message_"+m;
producer.send(new KeyedMessage(topic,message));
System.out.println(message);
m++;
try {
Thread.sleep(5000);
}catch (Exception e){
e.printStackTrace();
}
}
}
}
测试读取;
package com.itstar;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* 2018/8/2
**/
public class KafkaConsumer extends Thread{
private String topic;
public KafkaConsumer(String topic) {
this.topic = topic;
}
private ConsumerConnector createconsumer(){
Properties properties=new Properties();
properties.put("zookeeper.connect","192.168.126.129:2181");
properties.put("group.id","test");//随意写一个名
return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
@Override
public void run() {
ConsumerConnector connectcreate=createconsumer();
Map topicmap=new HashMap();
topicmap.put(topic,1);
//String topic
//List> 数据流
Map>> messagestreaming= connectcreate.createMessageStreams(topicmap);
KafkaStream streaming= messagestreaming.get(topic).get(0); //获取每次接收到的数据
ConsumerIterator it=streaming.iterator();
while(it.hasNext()){
String message=new String(it.next().message());
System.out.println(message);
}
}
}
main方法:
public class KafkaTest {
public static void main(String[] args) {
new KafkaProducer(KafkaProperties.TOPIC).start();
new KafkaConsumer(KafkaProperties.TOPIC).start();
}
}
实时处理数据的结果(datav):
可以直接打开链接https://datav.aliyun.com/share/e1af597f076db0461c398dca7e80789b查看,
由于数据处理流程未启动,图片数据不改变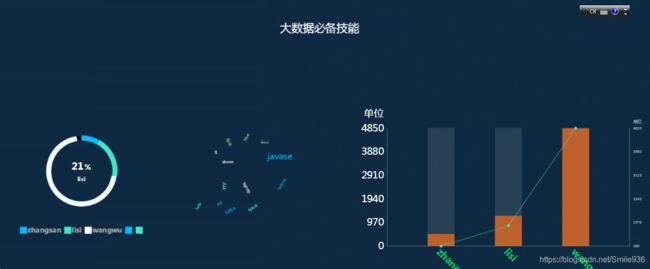
补充:
flume的使用