Sharding-JDBC4.0学习与实践(一)
一、概述
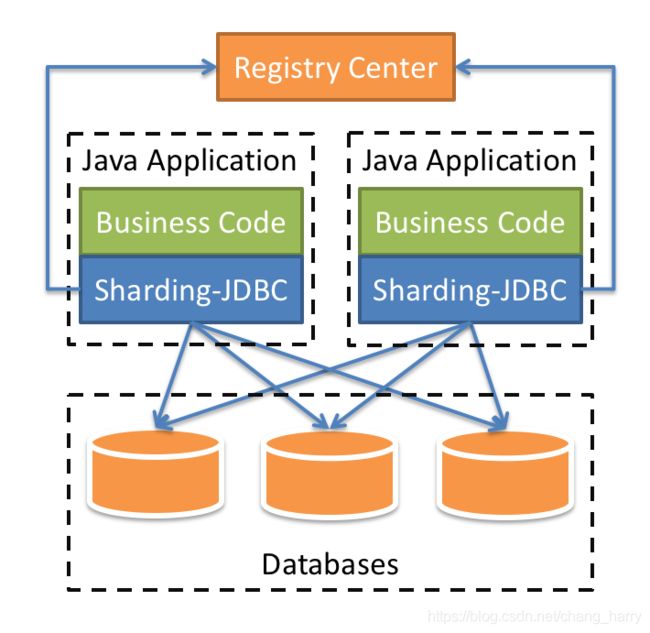
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
二、功能列表
1. 数据分片
分库 & 分表
读写分离
分片策略定制化
无中心化分布式主键
2. 分布式事务
标准化事务接口
XA强一致事务
柔性事务
3. 数据库治理
配置动态化
编排 & 治理
数据脱敏
可视化链路追踪
弹性伸缩(规划中)
三、项目状态

四、数据分片
背景
传统的将数据集中存储至单一数据节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足互联网的海量数据场景。
- 从性能方面来说,由于关系型数据库大多采用B+树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的IO次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
- 从可用性的方面来讲,服务化的无状态型,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
- 从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于DBA的运维压力就会增大。数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在1TB之内,是比较合理的范围。
NoSQL的不足
在传统的关系型数据库无法满足互联网场景需要的情况下,将数据存储至原生支持分布式的NoSQL的尝试越来越多。 但NoSQL对SQL的不兼容性以及生态圈的不完善,使得它们在与关系型数据库的博弈中始终无法完成致命一击,而关系型数据库的地位却依然不可撼动。
数据分片
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。
数据分片的有效手段是对关系型数据库进行分库和分表。
分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
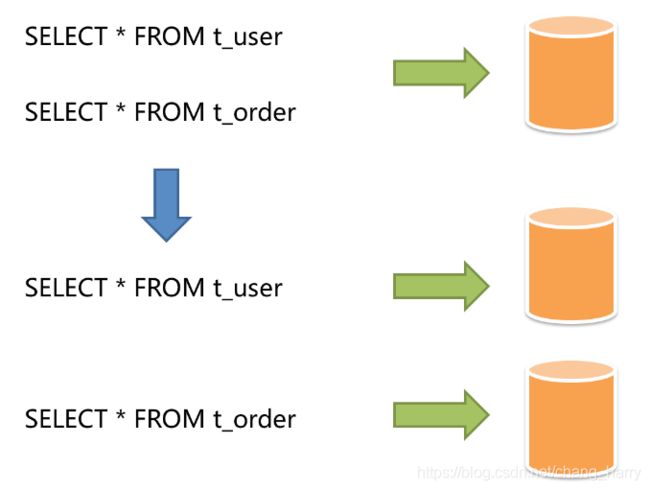
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表),如下图所示。
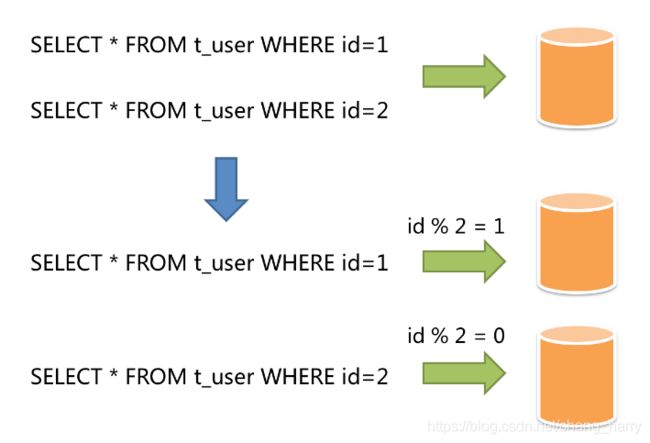
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案。
挑战
虽然数据分片解决了性能、可用性以及单点备份恢复等问题,但分布式的架构在获得了收益的同时,也引入了新的问题。
- 面对如此散乱的分库分表之后的数据,应用开发工程师和数据库管理员对数据库的操作变得异常繁重就是其中的重要挑战之一。他们需要知道数据需要从哪个具体的数据库的分表中获取。
- 另一个挑战则是,能够正确的运行在单节点数据库中的SQL,在分片之后的数据库中并不一定能够正确运行。例如,分表导致表名称的修改,或者分页、排序、聚合分组等操作的不正确处理。
- 跨库事务也是分布式的数据库集群要面对的棘手事情。
合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。
在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于XA的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。
目标
尽量透明化分库分表所带来的影响,让使用方尽量像使用一个数据库一样使用水平分片之后的数据库集群,是ShardingSphere数据分片模块的主要设计目标。
核心概念
SQL
- 逻辑表
水平拆分后数据库表的逻辑总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
2. 真实表(物理表)
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
3. 数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
4. 绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
5. 广播表
指所有的分片数据源中都存在的表。它的表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与其他有海量数据的表进行关联查询的场景,例如:字典表。
分片
- 分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
2.分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
1)精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键,并用=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
2)范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
3)复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多个键作为分片键进行分片的场景,包含多个分片键的逻辑较为复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
4)Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
3. 分片策略
包含分片键和分片算法,由于分片算法的独立性,将其单独抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
1)标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
2)复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符传给分片算法,完全由应用开发者实现,提供最大的灵活度。
3)行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
4)Hint分片策略
对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
5)不分片策略
对应NoneShardingStrategy。不进行分片的策略。
SQL Hint
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。
五、数据分片试验
shardingsphere的官网https://shardingsphere.apache.org/document/current/cn/overview/文字描述含混不清,网上的帖子也比较陈旧。试验它的配置,连蒙带猜干了一下午,终于跑通了一个例子。记下来为初学者填一些坑。
用下列组件完成实例:
MySQL8.0.18
SpringBoot2.1.2
MyBatis3.4.2
Sharding-JDBC4.0.0
- 准备分片后的数据库和表
init.sql文件
以下SQL写在init.sql文件中,用于生成数据库表。
CREATE DATABASE ds0;
USE ds0;
DROP TABLE IF EXISTS t_order0;
CREATE TABLE t_order0 (
order_id bigint(20) NOT NULL,
user_id bigint(20) NOT NULL,
order_name varchar(100) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (order_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
DROP TABLE IF EXISTS t_order1;
CREATE TABLE t_order1 (
order_id bigint(20) NOT NULL,
user_id bigint(20) NOT NULL,
order_name varchar(100) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (order_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE DATABASE ds1;
USE ds1;
DROP TABLE IF EXISTS t_order0;
CREATE TABLE t_order0 (
order_id bigint(20) NOT NULL,
user_id bigint(20) NOT NULL,
order_name varchar(100) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (order_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
DROP TABLE IF EXISTS t_order1;
CREATE TABLE t_order1 (
order_id bigint(20) NOT NULL,
user_id bigint(20) NOT NULL,
order_name varchar(100) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (order_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
在MySQL WorkBench中连接本地MySQL数据库后执行这些SQL语句。最后得到如下库表:
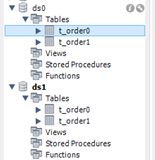
t_order{0,1}的四个表的表结构完全相同。
- 创建Maven工程
在IDEA中创建Maven工程。
pom.xml文件
pom.xml内容如下:
xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.harrygroupId>
<artifactId>springbootShardingJDBCartifactId>
<version>1.0-SNAPSHOTversion>
<packaging>warpackaging>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.1.2.RELEASEversion>
parent>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>1.2.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.13version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-dbcp2artifactId>
<version>2.7.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<fork>truefork>
configuration>
<executions>
<execution>
<goals>
<goal>repackagegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.mybatis.generatorgroupId>
<artifactId>mybatis-generator-maven-pluginartifactId>
<version>1.3.2version>
<configuration>
<verbose>trueverbose>
<overwrite>trueoverwrite>
configuration>
plugin>
plugins>
build>
project>
工程结构
工程结构如下:
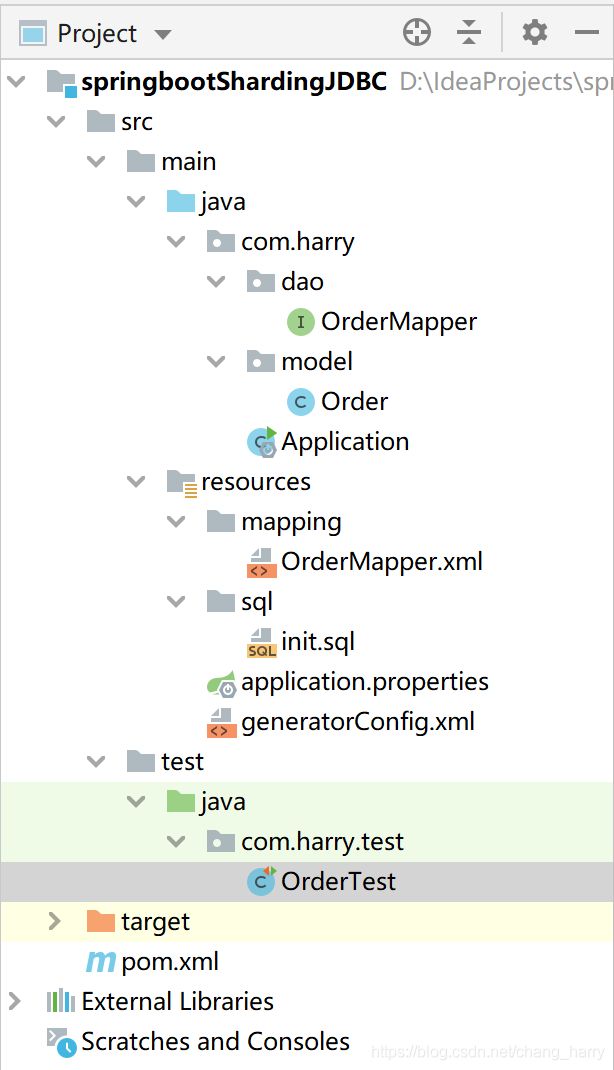
基本上是最简单的结构。
- 生成Model, DAO,和Mapper.xml文件
generatorConfig.xml文件
编写generatorConfig.xml文件
xml version="1.0" encoding="UTF-8"?>
generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<classPathEntry location="D:\Java\apache-maven-3.6.3\repository\mysql\mysql-connector-java\8.0.13\mysql-connector-java-8.0.13.jar"/>
<context id="DB2Tables" targetRuntime="MyBatis3">
<commentGenerator>
<property name="suppressDate" value="true"/>
<property name="suppressAllComments" value="true"/>
commentGenerator>
<jdbcConnection
driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://127.0.0.1:3306/ds0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true"
userId="root"
password="root"/>
<javaTypeResolver>
<property name="forceBigDecimals" value="false"/>
javaTypeResolver>
<javaModelGenerator targetPackage="com.harry.model" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
<property name="trimStrings" value="true"/>
javaModelGenerator>
<sqlMapGenerator targetPackage="mapping" targetProject="src/main/resources">
<property name="enableSubPackages" value="true"/>
sqlMapGenerator>
<javaClientGenerator type="XMLMAPPER" targetPackage="com.harry.dao" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
javaClientGenerator>
<table tableName="t_order0" domainObjectName="Order" enableCountByExample="false" enableUpdateByExample="false" enableDeleteByExample="false" enableSelectByExample="false" selectByExampleQueryId="false">table>
context>
generatorConfiguration>
运行Maven窗口里的
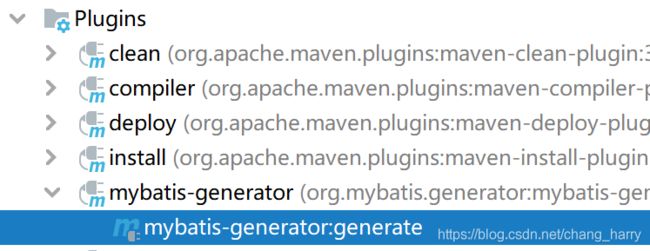
它会在你设置的目录里自动生成model,dao和mapper.xml文件。
这样我们就基本上不用怎么写代码了。
Order.java文件
Order.java的内容:
package com.harry.model;
public class Order {
private Long orderId;
private Long userId;
private String orderName;
public Order(Long orderId,Long userId,String orderName){
this.orderId = orderId;
this.userId = userId;
this.orderName = orderName;
}
public Long getOrderId() {
return orderId;
}
public void setOrderId(Long orderId) {
this.orderId = orderId;
}
public Long getUserId() {
return userId;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public String getOrderName() {
return orderName;
}
public void setOrderName(String orderName) {
this.orderName = orderName == null ? null : orderName.trim();
}
}
OrderMapper.java文件
OrderMapper.java的内容:
package com.harry.dao;
import com.harry.model.Order;
public interface OrderMapper {
int deleteByPrimaryKey(Long orderId);
int insert(Order record);
int insertSelective(Order record);
Order selectByPrimaryKey(Long orderId);
int updateByPrimaryKeySelective(Order record);
int updateByPrimaryKey(Order record);
}
OrderMapper.xml文件
OrderMapper.xml的内容:
xml version="1.0" encoding="UTF-8"?>
mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.harry.dao.OrderMapper">
<resultMap id="BaseResultMap" type="com.harry.model.Order">
<id column="order_id" jdbcType="BIGINT" property="orderId" />
<result column="user_id" jdbcType="BIGINT" property="userId" />
<result column="order_name" jdbcType="VARCHAR" property="orderName" />
resultMap>
<sql id="Base_Column_List">
order_id, user_id, order_name
sql>
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from t_order
where order_id = #{orderId,jdbcType=BIGINT}
select>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Long">
delete from t_order
where order_id = #{orderId,jdbcType=BIGINT}
delete>
<insert id="insert" parameterType="com.harry.model.Order">
insert into t_order (order_id, user_id, order_name
)
values (#{orderId,jdbcType=BIGINT}, #{userId,jdbcType=BIGINT}, #{orderName,jdbcType=VARCHAR}
)
insert>
<insert id="insertSelective" parameterType="com.harry.model.Order">
insert into t_order
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="orderId != null">
order_id,
if>
<if test="userId != null">
user_id,
if>
<if test="orderName != null">
order_name,
if>
trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="orderId != null">
#{orderId,jdbcType=BIGINT},
if>
<if test="userId != null">
#{userId,jdbcType=BIGINT},
if>
<if test="orderName != null">
#{orderName,jdbcType=VARCHAR},
if>
trim>
insert>
<update id="updateByPrimaryKeySelective" parameterType="com.harry.model.Order">
update t_order
<set>
<if test="userId != null">
user_id = #{userId,jdbcType=BIGINT},
if>
<if test="orderName != null">
order_name = #{orderName,jdbcType=VARCHAR},
if>
set>
where order_id = #{orderId,jdbcType=BIGINT}
update>
<update id="updateByPrimaryKey" parameterType="com.harry.model.Order">
update t_order
set user_id = #{userId,jdbcType=BIGINT},
order_name = #{orderName,jdbcType=VARCHAR}
where order_id = #{orderId,jdbcType=BIGINT}
update>
mapper>
Application.java文件
Application.java的内容:
package com.harry;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.harry.dao")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
application.properties文件
分布分表的策略和方法都定义在application.properties中。这里我们采用了最简单的inline的方法。application.properties的内容如下:
mybatis.mapperLocations=classpath:mapping/*.xml
# Sharding-JDBC配置项
#数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.names=ds0,ds1
#数据库连接池类名称
spring.shardingsphere.datasource.ds0.type=org.apache.commons.dbcp2.BasicDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://127.0.0.1:3306/ds0?useUnicode\=true&characterEncoding\=utf-8&useSSL\=false&serverTimezone\=GMT&allowPublicKeyRetrieval\=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root
spring.shardingsphere.datasource.ds1.type=org.apache.commons.dbcp2.BasicDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://127.0.0.1:3306/ds1?useUnicode\=true&characterEncoding\=utf-8&useSSL\=false&serverTimezone\=GMT&allowPublicKeyRetrieval\=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
#默认数据库分片策略,即分库策略,为inline
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#分库算法
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
# t_order是
# actual-data-nodes
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
# 分表策略为inline
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
# 分表算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
测试类
下面是我们的测试类。
package com.harry.test;
import com.harry.Application;
import com.harry.dao.OrderMapper;
import com.harry.model.Order;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
@SpringBootTest(classes = Application.class)
@RunWith(SpringRunner.class)
public class OrderTest {
@Resource
private OrderMapper orderMapper;
@Test
public void testAddOrder(){
Order order0_0 = new Order(0L,0L,"order0_0");
Order order0_1 = new Order(1L,0L,"order0_1");
Order order1_2 = new Order(2L,1L,"order1_2");
Order order1_3 = new Order(3L,1L,"order1_3");
orderMapper.insert(order0_0);
orderMapper.insert(order0_1);
orderMapper.insert(order1_2);
orderMapper.insert(order1_3);
}
}
- 执行测试类
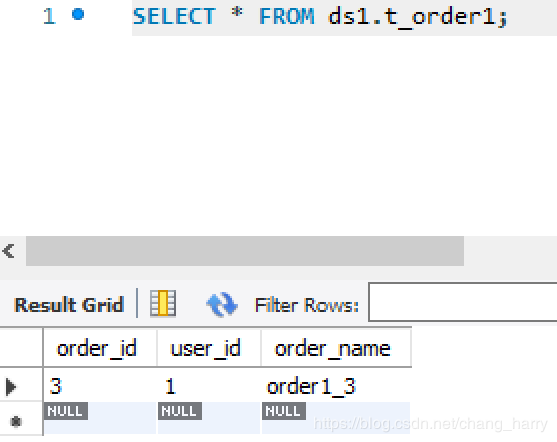
执行测试类,它将按照预定义的分库分表的规则(按user_id % 2分库,按order_id % 2分表)向ds0.t_order0, ds0.t_order1, ds1.t_order0, ds1.t_order1四个表中分别插入一条数据。
执行结果
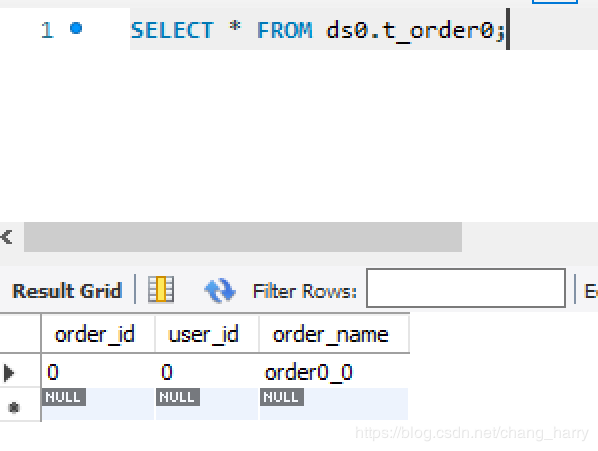
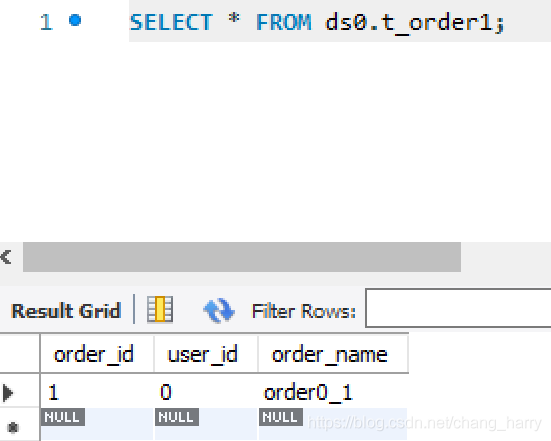
有了这个例子,再试验Sharding-JDBC的其他功能就比较方便快捷了。