ARM数据/地址总线架构简析
ARM架构简析
1,ARM概述
现在大家讲的ARM的概念实际上是很模糊的,他可能指的是一类芯片,或者指的是ARM公司,亦或者是精简指令集,还是千万人手中的饭碗。下面引用一段关于百度百科关于ARM的准确描述
ARM架构,曾称进阶精简指令集机器(Advanced RISC Machine)更早称作Acorn RISC Machine,是一个32位精简指令集(RISC)处理器架构。还有基于ARM设计的派生产品,重要产品包括Marvell的XScale架构和德州仪器的OMAP系列。
ARM家族占比所有32位嵌入式处理器的75%,成为占全世界最多数的32位架构。
在1980年代晚期,苹果电脑开始与Acorn合作开发新版的ARM核心,由于这专案非常重要,Acorn甚至于1990年将设计团队另组成一间名为安谋国际科技(Advanced RISC Machines Ltd.)的新公司。也基于这原因,使得ARM有时候反而称作Advanced RISC Machine而不是Acorn RISC Machine。由于其母公司ARM Holdings plc于1998年的伦敦交易市场和NASDAQ挂牌上市[1],使得Advanced RISC Machines成了ARM Ltd旗下拥有的产品。
这个专案到后来进入了ARM6,首版的式样在1991年释出,然后苹果电脑使用ARM6架构的ARM 610来当作他们Apple Newton PDA的基础。在1994年,Acorn使用ARM 610做为他们Risc PC电脑内的CPU。
这里八卦一下,其实咱们现在主流的手机芯片骁龙,麒麟和苹果A系列都是基于ARM架构,至于为啥苹果芯片在能耗比和性能上甩开同行1~2代差距,大概就是因为苹果电脑是ARM初创股东吧。
2,储存和架构
接下来用的是一款基于ST公司M4内核的芯片STM32F407ZG举例,一个总的系统架构总的来说需要包含数据总线,储存结构****编译器及代码软件,指令解释器和外部电路。
2.1 系统总线概述
STM32F407主系统是一款32位,基于多种AHB总线矩阵构成的,以此来实现多种主控总线的互联互通。
● 八条主控总线:
— Cortex™-M4F 内核 I 总线、D 总线和 S 总线
— DMA1 存储器总线
— DMA2 存储器总线
— DMA2 外设总线
— 以太网 DMA 总线
— USB OTG HS DMA 总线
● 七条被控总线:
— 内部 Flash ICode 总线
— 内部 Flash DCode 总线
— 主要内部 SRAM1 (112 KB)
— 辅助内部 SRAM2 (16 KB)
— 辅助内部 SRAM3 (64 KB)(仅适用于 STM32F42xxx 和 STM32F43xxx 器件)
— AHB1 外设(包括 AHB-APB 总线桥和 APB 外设)
— AHB2 外设
— FSMC
通过主控总线与被控总线与总线矩阵的互联互通,实现主控总线对被控总线上数据的访问,以此实现M4内核对外部代码指令和数据的执行和计算。接下来通过芯片手册中提供的系统总线图来了解西总体框架样式。
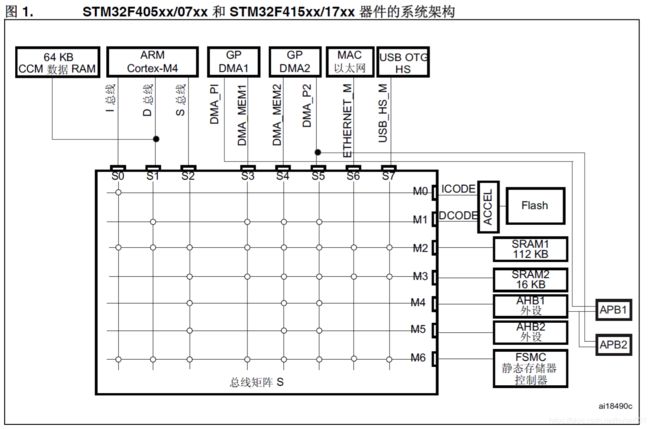
图中所示,各种总线都汇聚在总线矩阵上,通过总线矩阵的流水线实现对所有数据的实时调度,采用的是循环调度算法。
2.1 主控总线
2.1.1 S0:I 总线
此总线用于将 Cortex™-M4F 内核的指令总线连接到总线矩阵。内核通过此总线获取指令。 此总线访问的对象是包含代码的存储器(内部 Flash/SRAM 或通过 FSMC 的外部存储器)。
2.1.2 S1:D 总线
此总线用于将 Cortex™-M4F 数据总线和 64 KB CCM 数据 RAM 连接到总线矩阵。内核通过 此总线进行立即数加载和调试访问。此总线访问的对象是包含代码或数据的存储器(内部Flash 或通过 FSMC 的外部存储器)。
2.1.3 S2:S 总线
此总线用于将 Cortex™-M4F 内核的系统总线连接到总线矩阵。此总线用于访问位于外设 或 SRAM 中的数据。也可通过此总线获取指令(效率低于 ICode)。此总线访问的对象是 112 KB、64 KB 和 16 KB 的内部 SRAM、包括 APB 外设在内的 AHB1 外设、AHB2 外设以 及通过 FSMC 的外部存储器。
2.1.4 S3、S4:DMA 存储器总线
此总线用于将 DMA 存储器总线主接口连接到总线矩阵。DMA 通过此总线来执行存储器数据 的传入和传出。此总线访问的对象是数据存储器:内部 SRAM(112 KB、64 KB、16 KB) 以及通过 FSMC 的外部存储器。
2.1.5 S5:DMA 外设总线
此总线用于将 DMA 外设主总线接口连接到总线矩阵。DMA 通过此总线访问 AHB 外设或执 行存储器间的数据传输。此总线访问的对象是 AHB 和 APB 外设以及数据存储器:内部 SRAM 以及通过 FSMC 的外部存储器。
2.1.6 S6:以太网 DMA 总线
此总线用于将以太网 DMA 主接口连接到总线矩阵。以太网 DMA 通过此总线向存储器存取 数据。此总线访问的对象是数据存储器:内部 SRAM(112 KB、64 KB 和 16 KB)以及通过 FSMC 的外部存储器。
这里附带说一句,其实M4内核在访问FLASH上的软件是分成两个部分进行的,分别是:I总线和S总线,一个访问指令,一个访问数据,这种将指令和数据分开的结构称之为哈佛结构,反之使用一条总线访问数据和指令则称之为冯诺依曼结构,至于孰优孰劣则取决于嵌入式平台应用场景了以及处理复杂程度和系统的实时性。
2.1.7 S7:USB OTG HS DMA 总线
此总线用于将 USB OTG HS DMA 主接口连接到总线矩阵。USB OTG DMA 通过此总线向存储 器加载/存储数据。此总线访问的对象是数据存储器:内部 SRAM(112 KB、64 KB 和 16 KB) 以及通过 FSMC 的外部存储器。
2.2 被控总线
2.2.1 AHB/APB 总线桥 (用一个不恰当的比喻就是类似于电脑里面的南北桥)
借助两个 AHB/APB 总线桥 APB1 和 APB2,可在 AHB 总线与两个 APB 总线之间实现完全 同步的连接,从而灵活选择外设频率。
AHB,是Advanced High performance Bus的缩写,译作高级高性能总线,这是一种“系统总线”。AHB主要用于高性能模块(如CPU、DMA和DSP等)之间的连接。AHB系统由主模块、从模块和基础结构(Infrastructure)3部分组成,整个AHB总线上的传输都由主模块发出,由从模块负责回应。
APB,是Advanced Peripheral Bus的缩写,这是一种外围总线。APB主要用于低带宽的周边外设之间的连接,例如UART、1284等,它的总线架构不像 AHB支持多个主模块,在APB里面唯一的主模块就是APB 桥。再往下,APB2负责AD,I/O,高级TIM,串口1;APB1负责DA,USB,SPI,I2C,CAN,串口2345,普通TIM。
这两者都是总线,符合AMBA规范。AHB为系统资源总线,使用系统最高时钟,主要应用在主屏较高的外设资源通信上,例如以太网,USB等通信协议;而APB则是经过系统时钟分频后总线,主要面向外接设备总线通信,例如:IIC,SPI,UART,AD,TIM等。通过芯片手册中描述的系统时钟树便可以清晰了解到这种结构。
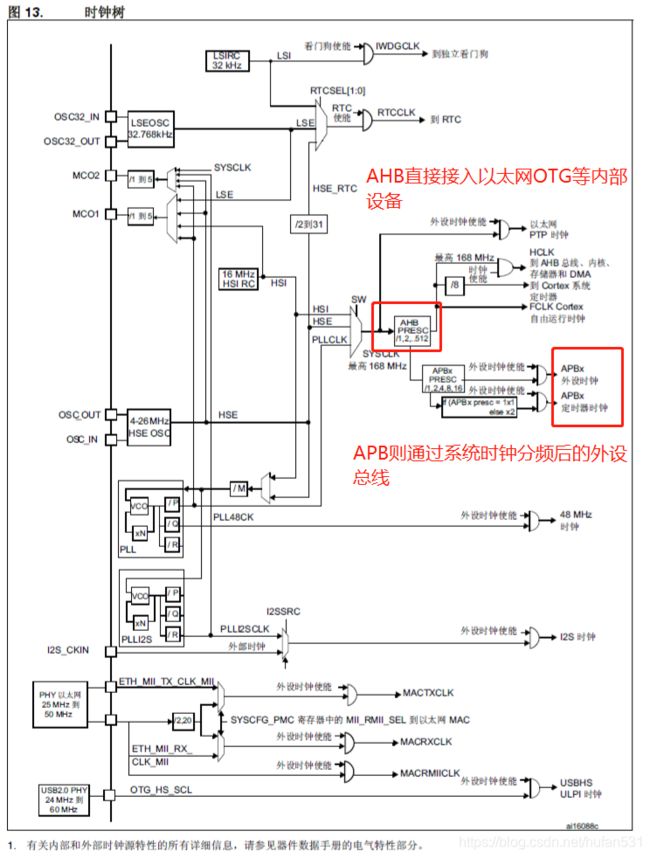
2.3 外设总线
上一节中提到外设总线挂载APBX的系统总线上,外设总线根据传输类型来区分主要分为:
1,并行传输
通过多根数据线在一个时钟周期内,同时访问多个寄存器地址,若数据线有8根,那么单次操作则可以获取1个字节的数据长度。较为典型的外设通信协议有:FMSC(静态储存控制器),主要用来外接SDRAM。
2,串行协议
串行通信协议实际上将来自系统总线的并行数据进行拆分,将一个字节分成8位传输,以此实现串口通信。目前ARM外设总线扩展基本都是基于串口协议。串口协议相对于并行传输速度慢,但是物理引脚少,易于封装以及外设接口的通用性收到广泛应用。我们常说的SPI,IIC,UART和CAN等通信都是串行通信。
我们在熟悉ARM系统总线后,若是要提高开发产品的能力,还必须学习外部总线扩展协议,无论是SOC还是MCU始终只是一个芯片,离开了外设他也将毫无价值。我们也必须清楚以上几个常用的串行协议在电平时序和电平电压上及电路抗干扰特点,根据应用场景选择最适合且成本最低的通信方式。关于以上几个常用的串行通信做个简单归纳则为:
① IIC应用场景
多主多从,片上通信(抗干扰差),速度低,端口少(2PIN),半双工异步收发。
② UART(RS232 485 645…)
一主多从,片外通信(抗干扰一般,可以接线),距离一般,端口少(2PIN),全双工同步收发。
③ SPI
一主多从,片内通信(抗干扰较IIC强些而已),速度快(在IIC基础上独立的片选来控制启停,而IIC需要一个ACK电平,双向收发IO),距离短,端口多(较IIC增加两个端口)
④CAN
多主模式(加入了仲裁优先级,光这一点秒杀上述所有协议),片外通信(可外部接线50米来着),距离远(与采用12V差分信号RS485一样),速度快(多主模式下的优势),端口少,成本贵(每个CAN节点均配备独立的CAN控制器和稍复杂的协议驱动)
2.4 储存器组织结构##
上面一整节描述的都是各种各样的总线结构,总线只不过是人们对架构设计时候虚构出来的通道而已,设计总线的目的只不过是对一整个系统中海量的数据设计一个相对安全有序的通道,但是这些数据最终是要保存在硬件设备上的,依托的这个设备就是我们非常常见的储存器了,这也是所有芯片运行最基本硬件了。
2.4.1 储存映射
存储器映射是指把芯片中或芯片外的FLASH,RAM,外设,BOOT,BLOCK等进行统一编址。即用地址来表示对象。这个地址绝大多数是由厂家规定好的,用户只能用而不能改。用户只能在挂外部RAM或FLASH的情况下可进行自定义。
Cortex-M4支持4GB的存储空间,它的存储系统采用统一编址的方式; 程序存储器、数据存储器、寄存器被组织在4GB的线性地址空间内,以小端格式(little-endian)存放。由于Cortex-M3是32位的内核,因此其PC指针可以指向2^32=4G的地址空间,也就是0x0000_0000——0xFFFF_FFFF这一大块空间。
上面描述了两个点:
①统一编址:将IO映射到内存中的架构(区别于51等的独立编码而言),目前主流的大型计算机多使用这种编码方式,其优点是在设计芯片时候可以根据储存大小很容易扩充IO管脚数量,缺点嘛就是浪费了这一块内存了,还有就是访问IO实际上要访问一遍储存,比较消耗时间不适用于小型系统。
②地址总线:M4内核支持16,32,64,128位寻址,而STM32F4则设计为32位系统,意思是他们地址总线有32根,单个周期内能够获取4个字节数据,同时STM32储存器地址被映射为4字节长度表达,所以这款芯片最长寻址地址为:0xff ff ff ff,也就是4GB空间了,当然是不是可以通过两条指令实现64位寻址呢,啊哈哈哈。
还是和上面一样来一张芯片手册山的储存映射图吧,不过4G内存较大导致图片太长了,就不打算用手册上那张详细的图了。
我找了一写网上关于映射储存的描述图片,都不太满意,过两天我把我自己手动画的贴上去吧。
2.4.2 储存分块及其对应功能
① 0x00 00 00 00 —> 0x1f ff ff ff
512M的code区,主要的RW,RO,ZI区域,具体可以看图,想了解详细软件运行过程及数据存放区域自行百度。
② 0x20 00 00 00 —> 0x3f ff ff ff
SRAM内核外部储存器部分
③ 0x40 00 00 00 —> 0x5f ff ff ff
内核外设模块使用空间,主要有APB2,APB1,AHB2
⑥ 0x60 00 00 00 —> 0xbf ff ff ff
外部FSMC的SRAM外部地址总线扩展(其实也不叫扩展,分明就是预留给他的)。
⑦ 0xc0 00 00 00 —> 0xdf ff ff ff
not used
⑧ 0xe0 00 00 00 —> 0xff ff ff ff
芯片内核外设资源储存快
结束语:
其实吧了解上面这些对你开发似乎带来不了什么裨益,但是我们可以学习这种设计思路。可以看到ARM架构在设置之处就非常讲究分层,从总线的分层到时钟的分层,整个流程宛如一个树状图,数据从各个分支汇总到系统总线上,再通过各个途径返回外设各分支总线上。
对于我们编程开发而言,关心的其实只有外设总线那个部分,所以对于我们来说如何在现有的通信协议基础上对通信数据存取进行优化,目前除了系统在带的DMA功能很好用之外,也可以通过一些软件的手段来优化通信数据存取,例如环形链表之类的操作。
后面的话主要讲一下软件工程架构之类的主要和重要细节吧,今天就先说到这儿了。
回外设各分支总线上。
对于我们编程开发而言,关心的其实只有外设总线那个部分,所以对于我们来说如何在现有的通信协议基础上对通信数据存取进行优化,目前除了系统在带的DMA功能很好用之外,也可以通过一些软件的手段来优化通信数据存取,例如环形链表之类的操作。
后面的话主要讲一下软件工程架构之类的主要和重要细节吧,今天就先说到这儿了。