《Siamese RPN:High Performance Visual Tracking with Siamese Region Proposal Network》论文笔记
参考代码:DaSiamRPN
1. 概述
导读:这篇文章提出了一种端到端的离线训练网络Siamese region proposal network(Siamese-RPN),它使用大量的成对数据完成网络训练。其中包含的特征提取部分是Siamese网络,以及完成目标分类和边界框回归的RPN子网络部分。在进行infer的时候只需要一次计算目标的特征之后通过correlation layer完成目标的匹配,之后用于目标的跟踪,此外这个方法的一个亮点就是速度很快,能达到160FPS(AlexNet,GTX1060)。从检测网络的角度来看就是one-shot 检测器。
对现有的目标跟踪算法进行分析,可以将其分为两个大类:
- 1)基于correlation filter的跟踪方法,在早些的方法中它通过利用循环相关的特性和在傅立叶域中执行运算来训练回归器,这样带来的好处就是可以进行online的目标跟踪并且同步更新filter的权重。之后有将深度学习的特征引入提升准确率,但是却使得速度模型更新的下降;
- 2)使用CNN的方法目标特征,在运行过程中并不更新模型,由于其没有使用domain specific信息使得其性能相较第一种方法的低一些。现在这一分支的跟踪网络也很厉害了;
2. 方法设计
2.1 网络结构
而文章的方法受检测网络中RPN网络的影响,在Siamese网络的基础上设计出了Siamese-RPN,极大提升了网络的性能。不同的是使用两个特征提取支路得到的correlation特征作为RPN网络的输入,从而再去回归目标的位置。
文章的网络结构设计为如下图中的结构形式:

可以看到文章使用的是Siamese网络去抽取输入图像的特征,从而得到模板和检测帧的特征输出 φ ( z ) , φ ( x ) \varphi (z),\varphi (x) φ(z),φ(x),之后就是在这两个输出的基础上使用RPN网络部分去获取对应的分类与坐标框的回归。
2.2 RPN子网络
这部分网络可以更近一步细分为相关性提取与回归监督部分。首先对于相关性部分是在模板与检测特征的结果上分别使用两个卷积进行组合,从而再得到相关性特征图。值得注意的是这里对模板特征图对应了一个channel上的参数 k k k,这个参数代表的是使用了多少个anchor,在这篇文章中作者将其值设置为: r a t i o = [ 0.33 , 0.5 , 1 , 2 , 3 ] ratio=[0.33,0.5,1,2,3] ratio=[0.33,0.5,1,2,3],而scale上作者认为变化不大使用的是固定值。而后面的监督部分就是对前景背景做二分类,在anchor的基础上对目标框进行回归。因而这部分的运算过程可以描述为:
A w ∗ h ∗ 2 k c l s = [ φ ( x ) ] c l s ∗ [ φ ( z ) ] c l s A_{w*h*2k}^{cls}=[\varphi (x)]_{cls}*[\varphi (z)]_{cls} Aw∗h∗2kcls=[φ(x)]cls∗[φ(z)]cls
A w ∗ h ∗ 4 k r e g = [ φ ( x ) ] r e g ∗ [ φ ( z ) ] r e g A_{w*h*4k}^{reg}=[\varphi (x)]_{reg}*[\varphi (z)]_{reg} Aw∗h∗4kreg=[φ(x)]reg∗[φ(z)]reg
那么对于回归部分这里就是使用很常见的Faster RCNN中的回归方式了(这样的回归方式也比较老了,在检测里面也有很多的改进方法了),对于分类采用的是交叉熵损失函数,而对于边界框的损失是根据SmoothL1损失函数做了相应修改而来的。这里使用 A x , A y , A w , A h A_x,A_y,A_w,A_h Ax,Ay,Aw,Ah表示anchor的中心点与宽高, T x , T y , T w , T h T_x,T_y,T_w,T_h Tx,Ty,Tw,Th表示GT的中心点与宽高,那么基于上面的两个值就可以得到网络需要回归的具体数值:
δ [ 0 ] = T x − A x A w , δ [ 1 ] = T y − A y A h \delta[0]=\frac{T_x-A_x}{A_w},\delta[1]=\frac{T_y-A_y}{A_h} δ[0]=AwTx−Ax,δ[1]=AhTy−Ay
δ [ 2 ] = l n T w A w , δ [ 3 ] = l n T h A h \delta[2]=ln\frac{T_w}{A_w},\delta[3]=ln\frac{T_h}{A_h} δ[2]=lnAwTw,δ[3]=lnAhTh
文章中对原始的SmoothL1损失函数进行了修改,其形式为:

因而将4个分量的值加起来就是整个的边界框回归的损失值:
L r e g = ∑ i = 0 3 s m o o t h L 1 ( δ [ i ] , σ ) L_{reg}=\sum_{i=0}^3smooth_{L1}(\delta[i],\sigma) Lreg=i=0∑3smoothL1(δ[i],σ)
整个网络回归部分的损失函数为:
l o s s = L c l s + L r e g loss=L_{cls}+L_{reg} loss=Lcls+Lreg
对于具体的训练过程也是很大程度上参考了Faster RCNN网络的训练思路,在RPN中设置了两个IoU的阈值 t h h i = 0.6 , t h l o = 0.3 th_{hi}=0.6,th_{lo}=0.3 thhi=0.6,thlo=0.3,那么将高于大阈值的作为正样本,而低于低阈值的作为副样本。在训练的时候对于一个图像对选择64个样本(其中正样本16个)进行训练。
3. 基于one-shot检测的跟踪
3.1 问题归纳
在文章中将跟踪问题转换为了one-shot的检测问题(使用了模板图像)。因而文章的跟踪任务就可以描述为:
min W 1 n ∑ i = 1 n L ( R ( ψ ( x i ; W ) ; ψ ( z i ; W ) ) , L I ) \min_W\frac{1}{n}\sum_{i=1}^nL(R(\psi(x_i;W);\psi(z_i;W)),L_I) Wminn1i=1∑nL(R(ψ(xi;W);ψ(zi;W)),LI)
其描述的含义就是RPN网络的输出与GT的目标框应该尽可能的接近。
3.2 跟踪网络的infer
由于模板分支在确定跟踪目标的时候就能够确定下来,因而infer的时候主要是在检测分支上进行运算。这里的检测分支其实就是一个检测网络,因而其输出的处理过程也是和检测网络一致的。其流程可见下图所示:

3.3 Proposal区域的选择
文章的方法很大程度上参考了检测网络的设计,但是一些设计在跟踪的场景下就不是那么合适,对此文章给出了两个策略用于选择Proposal,从而更进一步加快网络速度提高准确率:
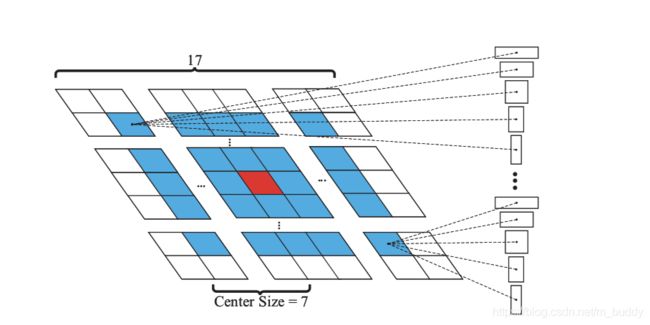
- 1)给可能的区域设定一个范围。基于在相邻帧之间目标的位移并不是那么巨大,因而就可以限定搜索的范围了,因而就可以在之前目标所在位置半径为 k = 7 k=7 k=7的空间内进行搜索,见下图所示:
- 2)使用cosine window和尺度变化去约束proposal的得分,从而获取更加合适的一个结果。这里用cosine window去抑制大的位移变化,并额外设定了一个惩罚去抑制在scale与ratio上的差异。
p e n a l t y = e k ∗ m a x ( r r ‘ , f r a c r ‘ r ) ∗ m a x ( s s ‘ , f r a c s ‘ s ) penalty=e^{k*max(\frac{r}{r^{‘}},frac{r^{‘}{r}})*max(\frac{s}{s^{‘}},frac{s^{‘}{s}})} penalty=ek∗max(r‘r,fracr‘r)∗max(s‘s,fracs‘s)
其中, r , r ‘ r,r^{‘} r,r‘分别代表的是当前与之前的目标框ratio。对于参数 s s s也是类似的,在文章中将其定义为:
s 2 = ( w + p ) ∗ ( h + p ) s^2=(w+p)*(h+p) s2=(w+p)∗(h+p)
其中, p p p是将不足的边补充到 w + h 2 \frac{w+h}{2} 2w+h所需的padding大小。
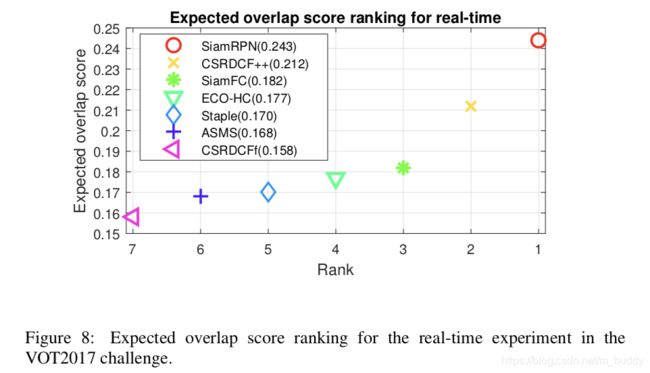
3. 实验结果
VOT-2015:

VOT-2017: