[CVPR2020论文(目标跟踪方向)]Know Your Surroundings:Exploiting Scene Information for Object Tracking
大家好,马上又要周末了,这周有认真学习,认真科研吗?最近看了一篇新的论文,这里做一下分享。
更新时间:2020.04.27
论文题目:Know Your Surroundings:Exploiting Scene Information for Object Tracking
作者:Goutam Bhat,Martin Danelljan,Luc Van Gool,Radu Timofte
摘要:目前SOTA的跟踪器为了定位目标在每帧中的位置,只依赖于目标外观模型。这样的方法在一些情况中会失败,比如快速的外观变化或干扰物的出现,只有目标外观模型对于鲁棒的跟踪来说是不够的。知道周围场景中其他物体的存在和位置信息对这种情况是十分有利的。这些场景信息可以在序列中传播,并用于,比如,避免干扰物和排除目标的候选区域。
在本文的工作中,我们提出了一个可以利用场景信息的新颖的跟踪框架。我们的跟踪器用稠密局部状态向量来表示这些信息,该向量可以对局部区域是否为目标、背景或干扰物进行编码。这些状态向量在序列中进行传播,并和外观模型输出结合来定位目标。我们的网络通过直接最大化在视频上的跟踪性能来学习高效的利用场景信息。所提出的算法在3个跟踪基准上达到了SOTA,在GOT-10k数据集上的AO分数达到63.6%。
1、引言
目标跟踪是有大量应用的基本视觉问题之一。任务是在给定初始外观的情况下,估计视频序列每一帧中目标物体的状态。大多数最近的方法通过学习初始帧中的外观模型来解决该问题。这个模型就被用于后续帧,通过从周围背景中判别出目标外观来定位目标。尽管获得了不错的结果,这些方法只依赖外观模型,并没有利用场景中的任何信息。
与之相比,在跟踪的时候人们利用更为丰富的提示集。我们对场景有全面的了解,考虑的不仅仅是目标外观,还连续考虑场景中的其他物体。这样的信息对目标定位是非常有帮助的,比如有干扰物的杂乱场景,或当目标经历了快速外观变化时。考虑图1中的例子。仅给定初始目标外观,由于干扰物体的出现,很难定位目标。然而,如果我们利用之前的帧,我们可以很简单的检测到干扰物体的存在。接下来,这些知识就可以被传递到下一帧中,从而更可靠的定位目标。尽管目前的方法利用上一帧更新了外观模型,它不能捕捉场景中其他物体的位置和特性。
![[CVPR2020论文(目标跟踪方向)]Know Your Surroundings:Exploiting Scene Information for Object Tracking_第1张图片](http://img.e-com-net.com/image/info8/6e1db982fc1e456e8697b41a5eb6fd63.jpg)
图1 目前的方法(上面)仅利用了外观模型来跟踪目标。然而,该方法在上面的场景中就失败了。在这里,干扰物的出现让仅仅基于外观进行准确的目标定位变的不可能,尽管目标模型是利用上一帧连续更新的。与之相比,我们的方法(下面)也知道场景中的其他物体。这个场景信息通过计算连续帧之间稠密的相关性(红色箭头)在序列中传播。传播的场景知识很好的简化了目标定位问题,使得跟踪更加可靠。
在本文的工作中,我们的目标是超越传统的基于逐帧检测的跟踪。我们提出了一个新颖的跟踪框架,它可以将有价值的场景信息在序列中传播。这些信息被用于实现提升每帧中场景感知的目标检测。场景信息用局部状态向量的稠密集合来表达。它们对局部区域的有价值的信息进行编码,比如区域是否与目标、背景或者干扰物体相关联。当区域在序列中移动的时候,我们通过利用帧之间的稠密关联映射来传播关联状态向量。因此,我们的跟踪器感知了场景中的每个物体,并且可以利用这些信息来避免干扰物体。场景信息和目标外观模型被用于预测每帧中目标的状态。由状态表达捕捉的场景信息通过循环神经网络模块进行更新。
贡献:主要贡献如下。(1)我们提出了一个新颖的跟踪框架,利用丰富的场景信息,并用稠密局部状态向量来表示。(2)引入传播模块,从而通过预测软连接来映射连续帧中的状态。(3)我们引入预测模块,高效的结合目标外观模型输出和场景信息,从而定位目标。(4)通过循环神经网络模块来用新信息更新状态。(5)我们训练了网络,从而直接在完整的视频上最大化跟踪性能。
我们在5个基准(VOT-2018、GOT-10k、TrackingNet、OTB-100、NFS)上进行了大量的实验。我们的方法在五个数据集上均为SOTA。在具有挑战性的GOT-10k数据集上,我们的跟踪器获得平均重叠度(AO)分数为63.6%,超过之前最好的方法2.5%。我们也做了消融实验,分析跟踪结构中的关键部分的影响。
2、相关工作
大多数的目标跟踪方法通过学习首帧中的目标外观模型来解决问题。一个比较流行的学习目标外观模型的方法是判别相关滤波器(DCF)。该方法利用卷积定理来高效训练傅里叶域中的分类器,并以输入图片的循环移位作为训练数据。其他方法是在首帧中训练或微调深度神经网络中的几层,从而实现目标-背景分类。MDNet在线微调了三个全连接层,DiMP利用元学习的方式预测分类层的权重。最近几年,Siamese网络获得了很大的关注。这些方法通过学习相似性方法来解决跟踪问题,并用于定位目标。
上述讨论的判别类方法利用场景中的背景信息来学习目标外观模型。此外,一些算法尝试在Siamese跟踪器中将背景信息整合到外观模型中。然而,在很多情况下,干扰物体难以与之前的目标外观相区分。因此,在这种情况下,单一的目标模型不足以实现鲁棒的跟踪。更多的,在快速移动的情况下,很难将目标模型快速的应用于新的干扰上。与这些工作相比,我们的方法对不同图像区域的局部信息进行编码,并通过稠密匹配在序列中传播这些信息。与我们的工作很相关,论文46想要发现场景中干扰物的位置。然而,在每帧中,它只利用了手工设计规则将图像区域分类为背景和目标候选区,并利用线性移动模型来获得最终的预测。与之相比,我们提出了一个全学习方法,图像区域编码通过帧之间基于外观的稠密跟踪来学习并传播。此外,我们最终的预测是通过结合清晰的背景表达和外观模型输出来获得。
除了外观提示,一些算法将光流信息用于跟踪。在构建目标模型的时候,Gladh利用从光流图像中提取的深度运动特征来补足外观特征。Zhu利用光流来将之前帧的特征图弯曲到参考帧中,并整合他们,从而学习目标外观模型。然而,这些方法仅利用光流来增强目标模型的鲁棒性。与之相比,我们利用稠密运动信息来传播关于背景物体和结构的信息,从而补足目标模型。
一些工作也研究了使用循环神经网络(RNN)进行目标跟踪。Gan等人使用RNN,并基于图像特征和之前的目标位置来直接回归目标位置。Ning等人利用YOLO检测器来生成初始目标推荐。这些推荐和图像特征一起被送入LSTM网络,从而获得目标框。Yang等人利用LSTM更新目标模型,从而应对序列中目标外观的变化。
3、所提出的方法
我们提出了一个能够利用场景信息来增强跟踪性能的新的跟踪框架。目前SOTA得方法仅依赖目标外观模型来独立的处理每一帧,我们的方法同时传播了前一帧中的场景信息。这提供了大量关于环境的提示,比如干扰物体的位置,这对于目标的定位是非常有帮助的。
我们跟踪框架的结构图如图2所示。我们的跟踪器跟踪场景中的全部区域,并且传播任何关于它们的、有助于目标定位的信息。这通过保持目标邻域内每个区域的状态向量来实现。状态向量可以,比如说,编码某个块是否与目标、背景或干扰物体(很有可能欺骗目标外观模型)相关联。当目标在序列中移动时,通过估计连续帧之间的稠密关联来实现状态向量的传播。接下来,传播的状态向量就和目标外观模型相融合,从而预测最终用于定位的目标置信度值。最后,预测器和目标模型的输出通过卷积门循环单元(ConvGRU)被用于更新状态向量。
![[CVPR2020论文(目标跟踪方向)]Know Your Surroundings:Exploiting Scene Information for Object Tracking_第2张图片](http://img.e-com-net.com/image/info8/f9b55babfb16419888d19052df75ea42.jpg)
图2 跟踪框架。除了使用目标外观模型![]() ,我们的跟踪器也利用了传播的场景信息。每个图像区域的信息被编码到局部状态
,我们的跟踪器也利用了传播的场景信息。每个图像区域的信息被编码到局部状态![]() 里。给定前一帧的状态
里。给定前一帧的状态![]() ,传播模块
,传播模块![]() 将前一帧中的这些状态映射到当前帧的位置。传播的状态
将前一帧中的这些状态映射到当前帧的位置。传播的状态![]() 、传播可靠度
、传播可靠度![]() 和外观模型分数
和外观模型分数![]() 被一起送到预测器
被一起送到预测器![]() 中,从而输出最终的目标置信度分数
中,从而输出最终的目标置信度分数![]() 。状态更新模块
。状态更新模块![]() 利用当前帧的预测结果来提供新的状态
利用当前帧的预测结果来提供新的状态![]() 。
。
3、1利用场景传播的跟踪
我们的跟踪器预测基于两个提示:(1)当前帧中的外观和(2)随时间传播的场景信息。外观模型![]() 用于从背景中区分目标物体。通过将帧
用于从背景中区分目标物体。通过将帧![]() 中提取的深度特征图
中提取的深度特征图![]() 作为输入,外观模型
作为输入,外观模型![]() 预测了分数图
预测了分数图![]() 。其中,每个空间位置
。其中,每个空间位置![]() 处的分数
处的分数![]() 表示了该位置是目标中心的可能性。
表示了该位置是目标中心的可能性。
目标模型有从遮挡中恢复和提供长期鲁棒性的能力。然而,它忽略了周围场景中的内容。为了提取这样的信息,我们的跟踪器为目标邻域内的每个区域保持一个状态向量。具体地,对于深度特征表达![]() 中的每个空间位置
中的每个空间位置![]() ,我们为那个单元的位置保持了一个S维的状态向量
,我们为那个单元的位置保持了一个S维的状态向量![]() ,
,![]() 。状态向量包含单元中的信息,这对于单目标跟踪是十分有益的。比如,它可以编码某个单元是否和目标、背景或与目标相似的干扰物相关联。注意到我们没有强制任何这样的编码,仅仅是让
。状态向量包含单元中的信息,这对于单目标跟踪是十分有益的。比如,它可以编码某个单元是否和目标、背景或与目标相似的干扰物相关联。注意到我们没有强制任何这样的编码,仅仅是让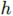 作为一个一般表达,它的编码是通过最小化跟踪损失来端到端训练的。
作为一个一般表达,它的编码是通过最小化跟踪损失来端到端训练的。
状态向量在初始帧中利用一个小网络![]() 来初始化,该网络以首帧目标标注
来初始化,该网络以首帧目标标注![]() 为输入,生成明确目标位置的单通道标签图。该标签图经过两个卷积层来获得初始状态向量
为输入,生成明确目标位置的单通道标签图。该标签图经过两个卷积层来获得初始状态向量![]() 。状态向量包含对应图像区域的局部信息。因此,当目标在序列中移动时,我们相应的传播状态向量。给定新帧
。状态向量包含对应图像区域的局部信息。因此,当目标在序列中移动时,我们相应的传播状态向量。给定新帧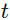 ,我们将状态
,我们将状态![]() 从前一帧的位置变换到当前帧的位置。这通过状态传播模块
从前一帧的位置变换到当前帧的位置。这通过状态传播模块![]() 来实现,
来实现,
![]()
其中,![]() 和
和![]() 分别是当前帧和前一帧的深度特征表达。输出
分别是当前帧和前一帧的深度特征表达。输出![]() 表示空间传播状态,弥补了场景中目标和背景的移动。传播可靠度图
表示空间传播状态,弥补了场景中目标和背景的移动。传播可靠度图![]() 表示了状态传播的可靠性。即,高的
表示了状态传播的可靠性。即,高的![]() 表示
表示![]() 处的状态
处的状态![]() 比较有把握的被传播。因此,可靠度图
比较有把握的被传播。因此,可靠度图![]() 可以被用于在定位目标时,判断传播的状态向量
可以被用于在定位目标时,判断传播的状态向量![]() 是否可以相信。
是否可以相信。
为了预测目标的位置,我们使用了外观模型输出![]() 和传播状态
和传播状态![]() 。后者捕捉了场景中所有物体的有价值的信息,这弥补了外观模型中获得的以目标为中心的信息。我们将传播状态向量
。后者捕捉了场景中所有物体的有价值的信息,这弥补了外观模型中获得的以目标为中心的信息。我们将传播状态向量![]() 、可靠度分数
、可靠度分数![]() 和外观模型预测
和外观模型预测![]() 输入预测模块
输入预测模块![]() 中。预测器提供融合的目标置信度分数
中。预测器提供融合的目标置信度分数![]() ,
,
![]()
接下来,目标就通过在![]() 帧中选择有最高分数
帧中选择有最高分数![]() 的位置
的位置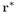 来定位。最终,我们利用融合的置信度分数
来定位。最终,我们利用融合的置信度分数![]() 和外观模型输出
和外观模型输出![]() 来更新状态向量,
来更新状态向量,
![]()
循环状态更新模块![]() 可以利用分数图中的当前帧信息去做,比如重设不正确的状态向量
可以利用分数图中的当前帧信息去做,比如重设不正确的状态向量![]() 或将新进入的目标标记为干扰物。这些更新的状态向量
或将新进入的目标标记为干扰物。这些更新的状态向量![]() 被用于后续帧中目标的跟踪。我们的跟踪步骤详见算法1。
被用于后续帧中目标的跟踪。我们的跟踪步骤详见算法1。
![[CVPR2020论文(目标跟踪方向)]Know Your Surroundings:Exploiting Scene Information for Object Tracking_第3张图片](http://img.e-com-net.com/image/info8/b70b988885674c588408f9a8bee723bd.jpg)
3.2、状态传播
状态向量包含目标邻域内每个区域的局部信息。这些区域会因为比如目标或相机的移动而在序列中移动,因此我们需要相应地传播它们的状态,从而补偿它们运动。这通过状态传播模块![]() 来实现。该模块的输入是从前一帧和当前帧中提取的深度特征图
来实现。该模块的输入是从前一帧和当前帧中提取的深度特征图![]() 和
和![]() 。注意到深度特征
。注意到深度特征![]() 不需要和用于目标模型的特征相同。然而,我们假设两种特征图都有相同的空间分辨率
不需要和用于目标模型的特征相同。然而,我们假设两种特征图都有相同的空间分辨率![]() 。
。
为了将状态从前一帧传播到当前帧位置,我们首先计算两帧之间的稠密关联。我们用概率分布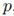 来表示该关联,
来表示该关联,![]() 是当前帧中的位置
是当前帧中的位置![]() 来源于前一帧中的位置
来源于前一帧中的位置![]() 的概率。稠密关联通过构建4D cost volume
的概率。稠密关联通过构建4D cost volume![]() 来估计,它常用于光流估计方法(比如:FlowNet)。cost volume包含前一帧和当前帧的每个图像位置对的匹配损失。cost volume中的元素
来估计,它常用于光流估计方法(比如:FlowNet)。cost volume包含前一帧和当前帧的每个图像位置对的匹配损失。cost volume中的元素![]() 通过计算前一帧特征
通过计算前一帧特征![]() 中以
中以![]() 为中心的
为中心的![]() 窗口和当前帧
窗口和当前帧![]() 中以
中以![]() 为中心的
为中心的![]() 窗口之间的相关性来获得。为了计算高效,我们只构建了部分cost volume,这通过假定每个特征单元的最大移位
窗口之间的相关性来获得。为了计算高效,我们只构建了部分cost volume,这通过假定每个特征单元的最大移位![]() 来实现。
来实现。
我们将cost volume输入一个网络模块,从而获得鲁棒的稠密关联。我们将前一帧中每个单元![]() 的cost volume切片
的cost volume切片![]() 输入两个卷积块,从而获得处理后的匹配代价
输入两个卷积块,从而获得处理后的匹配代价![]() 。然后,我们求了该输出在当前帧位置上的softmax,从而获得初始关联
。然后,我们求了该输出在当前帧位置上的softmax,从而获得初始关联![]() 。softmax操作整合了当前帧维度上的信息,并提供了两帧位置之间的软关联。为了整合之前帧位置的信息,我们将
。softmax操作整合了当前帧维度上的信息,并提供了两帧位置之间的软关联。为了整合之前帧位置的信息,我们将![]() 输入另外两个卷积块,然后在前一帧位置上做softmax。这提供了所需的当前帧位置
输入另外两个卷积块,然后在前一帧位置上做softmax。这提供了所需的当前帧位置![]() 处的概率分布
处的概率分布![]() 。
。
估计的帧之间的关联![]() 可以用于确定当前帧位置
可以用于确定当前帧位置![]() 处的传播状态向量
处的传播状态向量![]() ,这通过评估前一帧状态向量的下述期望来实现。
,这通过评估前一帧状态向量的下述期望来实现。
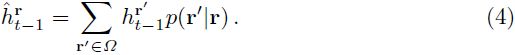
当使用传播状态向量![]() 来定位目标时,明确特定的状态向量是否合理是非常有帮助的,即它是否被正确的从上一帧中传播。我们可以使用位置
来定位目标时,明确特定的状态向量是否合理是非常有帮助的,即它是否被正确的从上一帧中传播。我们可以使用位置![]() 处的关联概率分布
处的关联概率分布![]() 来估计该位置处的可靠度
来估计该位置处的可靠度![]() 。
。![]() 中的单模式表明我们对位置
中的单模式表明我们对位置![]() 在前一帧中的来源非常自信。均匀分布的
在前一帧中的来源非常自信。均匀分布的![]() 则表示不确定状态。在这种情况下,期望(4)变为前一帧状态向量
则表示不确定状态。在这种情况下,期望(4)变为前一帧状态向量 的简单平均,导致不可靠的
的简单平均,导致不可靠的![]() 。因此,我们使用分布
。因此,我们使用分布![]() 的香农熵的负数来获得状态
的香农熵的负数来获得状态![]() 的可靠度分数
的可靠度分数![]() ,(为什么用负数?这样可靠度分数越大,才能说明越可靠,香农熵越大说明信息的不确定性越大,越接近均一分布,因为你不知道它的概率分布)
,(为什么用负数?这样可靠度分数越大,才能说明越可靠,香农熵越大说明信息的不确定性越大,越接近均一分布,因为你不知道它的概率分布)
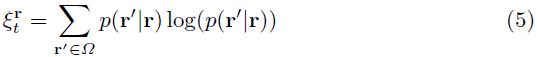
在预测最终的目标置信度分数时,可靠度![]() 被用于确定
被用于确定![]() 是否可信。
是否可信。
3.3、目标置信度分数预测
在本节中,我们描述确定目标在当前帧中的位置的预测模块![]() 。我们利用外观模型输出
。我们利用外观模型输出![]() 和由
和由![]() 编码的场景信息来定位目标。仅仅基于当前帧的外观,外观模型分数
编码的场景信息来定位目标。仅仅基于当前帧的外观,外观模型分数![]() 表明位置
表明位置![]() 是目标还是背景。状态向量
是目标还是背景。状态向量![]() 包含每个位置
包含每个位置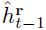 之前的信息。它可以做,比如,编码单元
之前的信息。它可以做,比如,编码单元![]() 在前一帧中被分类为目标还是背景,该位置的跟踪器预测的确定度有多少,等等。相关联的可靠度分数
在前一帧中被分类为目标还是背景,该位置的跟踪器预测的确定度有多少,等等。相关联的可靠度分数![]() 进一步展示了状态向量 是否可靠。这可以在确定目标位置时被用于决定赋予状态向量信息多大的权重。
进一步展示了状态向量 是否可靠。这可以在确定目标位置时被用于决定赋予状态向量信息多大的权重。
预测模块![]() 被训练来高效的结合来自
被训练来高效的结合来自![]() 、
、![]() 和
和![]() 的信息,从而输出最终的目标置信度分数
的信息,从而输出最终的目标置信度分数![]() 。我们在通道维度上连接了外观模型输出
。我们在通道维度上连接了外观模型输出![]() 、传播状态向量
、传播状态向量![]() 和状态可靠度分数
和状态可靠度分数![]() ,并将结果张量输入两个卷积块。为了获得中间分数
,并将结果张量输入两个卷积块。为了获得中间分数![]() ,我们将输出经过sigmoid层,映射到
,我们将输出经过sigmoid层,映射到![]() 间。尽管可以直接利用该分数,但是在遮挡情况中,它是不可靠的。因为目标的状态向量可能会泄露到遮挡物体上,尤其是两个物体缓慢交叉的时候。融合分数在这种情况下会引起错误。为了解决这个问题,我们将
间。尽管可以直接利用该分数,但是在遮挡情况中,它是不可靠的。因为目标的状态向量可能会泄露到遮挡物体上,尤其是两个物体缓慢交叉的时候。融合分数在这种情况下会引起错误。为了解决这个问题,我们将![]() 输入另一个层,该层隐藏分数图
输入另一个层,该层隐藏分数图![]() 中的一些区域,这些区域的外观模型分数
中的一些区域,这些区域的外观模型分数![]() 小于阈值
小于阈值![]() 。因此,在遮挡的情况下,我们让外观模型凌驾于预测器输出之上。最终的分数图
。因此,在遮挡的情况下,我们让外观模型凌驾于预测器输出之上。最终的分数图![]() 为
为![]() 。其中,
。其中,![]() 是指示函数,当
是指示函数,当![]() 时,值为1,否则为0,·表示元素乘。注意到隐藏(masking)操作是可微分的,并在网络内部实现。
时,值为1,否则为0,·表示元素乘。注意到隐藏(masking)操作是可微分的,并在网络内部实现。
3.4、状态更新
当3.2节中描述的状态传播将状态映射到新一帧中,它就不再用场景中的新信息来更新它。这通过循环神经网络模块来实现,该模块在每个时间步长中进化状态。至于场景中的跟踪信息,我们输入来自外观模型![]() 的分数
的分数![]() 和来自预测模块
和来自预测模块![]() 的
的![]() 。因此,更新模块就会标记新进入场景的干扰物或修正没有被正确传播的状态。状态更新通过循环模块(公式3)来实现。
。因此,更新模块就会标记新进入场景的干扰物或修正没有被正确传播的状态。状态更新通过循环模块(公式3)来实现。
更新模块![]() 包含卷积门循环单元(ConvGRU)。我们连接分数
包含卷积门循环单元(ConvGRU)。我们连接分数![]() 、
、![]() 以及它们的最大值,从而获得ConvGRU的输入
以及它们的最大值,从而获得ConvGRU的输入![]() 。上一帧中的传播状态
。上一帧中的传播状态![]() 被当做是上一时间步长的ConvGRU的隐藏状态。然后ConvGRU利用当前帧观察
被当做是上一时间步长的ConvGRU的隐藏状态。然后ConvGRU利用当前帧观察![]() 来更新新的状态
来更新新的状态![]() 。我们的跟踪器所用的表达的可视化如图3所示。
。我们的跟踪器所用的表达的可视化如图3所示。
![[CVPR2020论文(目标跟踪方向)]Know Your Surroundings:Exploiting Scene Information for Object Tracking_第4张图片](http://img.e-com-net.com/image/info8/215be5ecb25c4264b45b815652604245.jpg)
图3 用于跟踪的中间表达的可视化结果。前一帧(第一列)中的绿色框表示要跟踪的目标。对于当前帧(第三列)中的每个位置,我们绘制了与上一帧(第二列)中标记区域的关联。利用估计关联传播到当前帧中的状态在第四列中按通道绘制。由于干扰物的存在,外观模型分数(第五列)不能准确的定位目标。与之相比,我们的方法能解决这些场景,并利用传播的场景信息来提供鲁棒的目标置信度分数(最后一列)。
3.5、目标外观模型
我们的方法可以被整合到任何跟踪外观模型中去。在本文的工作中,由于DiMP强大的性能,我们利用它作为我们的目标模型部分。DiMP是一个可以端到端训练的跟踪框架,预测外观模型![]() ,由单个卷积层的权重
,由单个卷积层的权重![]() 来参数化。网络整合了优化模块来最小化下面的判别学习损失,
来参数化。网络整合了优化模块来最小化下面的判别学习损失,
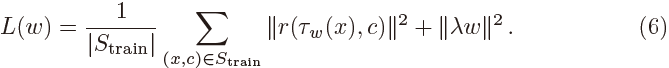
其中,![]() 是正则化参数。训练集
是正则化参数。训练集![]() 包含从训练图片中提取的深度特征图
包含从训练图片中提取的深度特征图![]() 和相关联的目标注释
和相关联的目标注释![]() 。残差方程
。残差方程![]() 计算了跟踪器预测
计算了跟踪器预测![]() 和ground truth之间的误差。在首帧中,训练集通过不同的数据增强手段来构建。详情见DiMP论文。
和ground truth之间的误差。在首帧中,训练集通过不同的数据增强手段来构建。详情见DiMP论文。