自动驾驶算法学习:多传感器信息融合(标定, 数据融合, 任务融合)
文章目录
- 1. 引言
- 2. 多传感器标定
- 2.1 标定场地
- 2.2 相机到相机
- 2.2 相机到多线激光雷达标定
- 2.3 相机到毫米波雷达标定
- 2.4 相机到IMU标定
- 2.5 论文总结
- 3. 数据层融合
- 3.1 融合的传统方法
- 3.2 深度学习方法
- 4. 任务层融合
- 4.1 传统之障碍物检测跟踪
- 4.2 传统之多传感器定位
- 4.3 深度学习之障碍物检测跟踪
- 4.4 深度学习之定位
1. 引言
自动驾驶感知和定位中传感器融合成了无人驾驶领域的趋势,融合按照实现原理分为硬件层的融合, 如禾赛和Mobileye等传感器厂商, 利用传感器的底层数据进行融合;数据层, 利用传感器各种得到的后期数据,即每个传感器各自独立生成目标数据,再由主处理器进行融合这些特征数据来实现感知任务;任务层, 先由各传感器完成感知或定位任务, 如障碍物检测,车道线检测,语义分割和跟踪以及车辆自身定位等, 然后添加置信度进行融合。
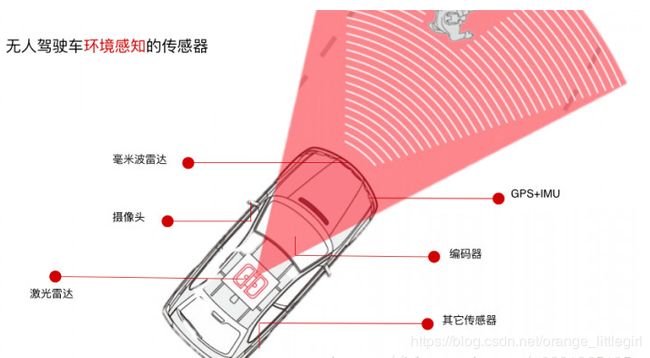
2. 多传感器标定
传感器标定是自动驾驶的基本需求,良好的标定是多传感器融合的基础, 一个车上装了多个/多种传感器,而它们之间的坐标关系是需要确定的。
这个工作可分成两部分:内参标定和外参标定,内参是决定传感器内部的映射关系,比如摄像头的焦距,偏心和像素横纵比(+畸变系数),而外参是决定传感器和外部某个坐标系的转换关系,比如姿态参数(旋转和平移6自由度)。
摄像头的标定曾经是计算机视觉中3-D重建的前提,张正友老师著名的的Zhang氏标定法,利用Absolute Conic不变性得到的平面标定算法简化了控制场。
另外在自动驾驶研发中,GPS/IMU和摄像头或者激光雷达的标定,雷达和摄像头之间的标定也是常见的。不同传感器之间标定最大的问题是如何衡量最佳,因为获取的数据类型不一样:
- 摄像头是RGB图像的像素阵列;
- 激光雷达是3-D点云距离信息(有可能带反射值的灰度值);
- GPS-IMU给的是车身位置姿态信息;
- 雷达是2-D反射图。
另外,标定方法分targetless和target两种,前者在自然环境中进行,约束条件少,不需要用专门的target;后者则需要专门的控制场,有ground truth的target,比如典型的棋盘格平面板。
这里仅限于targetless方法的讨论,主要利用Apollo中的标定工具对标定各个传感器进行研究。
2.1 标定场地
我们的标定方法是基于自然场景的,所以一个理想的标定场地可以显著地提高标定结果的准确度。我们建议选取一个纹理丰富的场地,如有树木,电线杆,路灯,交通标志牌,静止的物体和清晰车道线。下图是一个较好的标定环境示例:

2.2 相机到相机
智能车一般会有多个相机, 长焦距的用来检测远处场景(视野小), 短焦距检测近处(视野大).以Apollo的标定方法为例:
基本方法:根据长焦相机投影到短焦相机的融合图像进行判断,绿色通道为短焦相机图像,红色和蓝色通道是长焦投影后的图像,目视判断检验对齐情况。在融合图像中的融合区域,选择场景中距离较远处(50米以外)的景物进行对齐判断,能够重合则精度高,出现粉色或绿色重影(错位),则存在误差,当误差大于一定范围时(范围依据实际使用情况而定),标定失败,需重新标定(正常情况下,近处物体因受视差影响,在水平方向存在错位,且距离越近错位量越大,此为正常现象。垂直方向不受视差影响)。
结果示例:如下图所示,图2为满足精度要求外参效果,图3为不满足精度要求的现象,请重新进行标定过程。
- 良好的相机到相机标定结果,中间部分为融合结果,重叠较好:

- 错误的相机到相机标定结果,,中间部分为融合结果,有绿色重影:

2.2 相机到多线激光雷达标定
基本方法:在产生的点云投影图像内,可寻找其中具有明显边缘的物体和标志物,查看其边缘轮廓对齐情况。如果50米以内的目标,点云边缘和图像边缘能够重合,则可以证明标定结果的精度很高。反之,若出现错位现象,则说明标定结果存在误差。当误差大于一定范围时(范围依据实际使用情况而定),该外参不可用。
- 良好的相机到多线激光雷达标定结果:

- 错误的相机到多线激光雷达标定结果:

2.3 相机到毫米波雷达标定
基本方法:为了更好地验证毫米波雷达与相机间外参的标定结果,引入激光雷达作为桥梁,通过同一系统中毫米波雷达与相机的外参和相机与激光雷达的外参,计算得到毫米波雷达与激光雷达的外参,将毫米波雷达数据投影到激光雷达坐标系中与激光点云进行融合,并画出相应的鸟瞰图进行辅助验证。在融合图像中,白色点为激光雷达点云,绿色实心圆为毫米波雷达目标,通过图中毫米波雷达目标是否与激光雷达检测目标是否重合匹配进行判断,如果大部分目标均能对应匹配,则满足精度要求,否则不满足,需重新标定。
- 良好的毫米波雷达到激光雷达投影结果:

- 错误的毫米波雷达到激光雷达投影结果:

2.4 相机到IMU标定
虽然Apollo中没有, 但这是视觉slam中的常见传感器标定, 本人在近期会写一个相关的博客。
利用Kalibr 对 Camera-IMU 进行标定
2.5 论文总结
最近相关的标定方面的论文也出现了不少, 奇点的黄裕博士的知乎专栏有总结
3. 数据层融合
有些传感器之间很难在硬件层融合,比如摄像头或者激光雷达和毫米波雷达之间,因为毫米波雷达的目标分辨率很低(无法确定目标大小和轮廓),但可以在数据层层上探索融合,比如目标速度估计,跟踪的轨迹等等。
这里主要介绍一下激光雷达和摄像头的数据融合,实际是激光雷达点云投影在摄像头图像平面形成的深度和图像估计的深度进行结合,理论上可以将图像估计的深度反投到3-D空间形成点云和激光雷达的点云融合,但很少人用。原因是,深度图的误差在3-D空间会放大,另外是3-D空间的点云分析手段不如图像的深度图成熟,毕竟2.5-D还是研究的历史长,比如以前的RGB-D传感器,Kinect或者RealSense。
相机和激光雷达的数据层融合原因:
在无人驾驶环境感知设备中,激光雷达和摄像头分别有各自的优缺点。
摄像头的优点是成本低廉,用摄像头做算法开发的人员也比较多,技术相对比较成熟。摄像头的劣势,第一,获取准确三维信息非常难(单目摄像头几乎不可能,也有人提出双目或三目摄像头去做);另一个缺点是受环境光限制比较大。
激光雷达的优点在于,其探测距离较远,而且能够准确获取物体的三维信息;另外它的稳定性相当高,鲁棒性好。但目前激光雷达成本较高,而且产品的最终形态也还未确定。
3.1 融合的传统方法
- bayesia filter
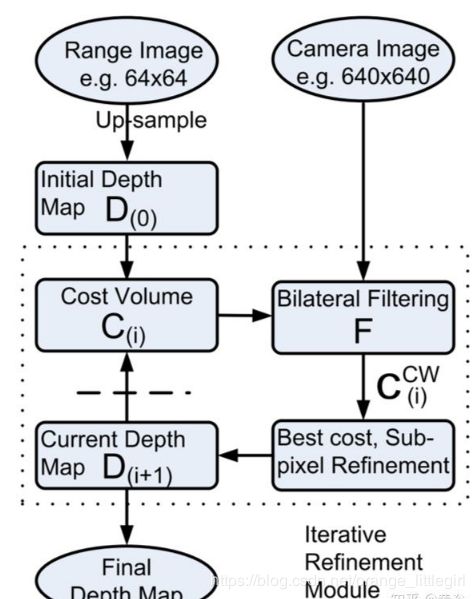
- guided image filtering
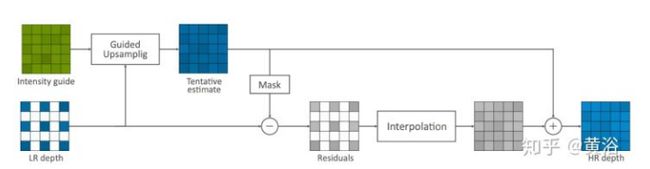
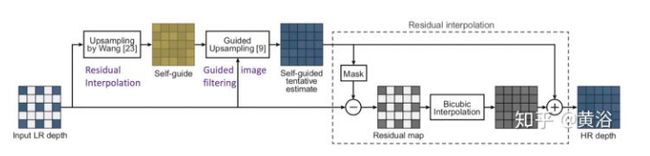
- 传统形态学滤波法
3.2 深度学习方法
(1) “Propagating Confidences through CNNs for Sparse Data Regression“, 提出normalized convolution (NConv)layer的改进思路,训练的时候NConv layer通过估计的confidence score最大化地融合 multi scale 的 feature map, 算法如下图:
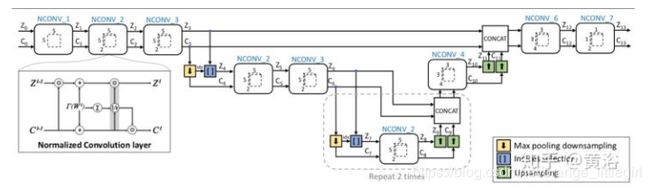
(2)ICRA的论文High-precision Depth Estimation with the 3D LiDAR and Stereo Fusion
只是在合并RGB image和depth map之前先通过几个convolution layer提取feature map:

(3)法国INRIA的工作,“Sparse and Dense Data with CNNs: Depth Completion and Semantic Segmentation“
作者发现CNN方法在早期层将RGB和深度图直接合并输入性能不如晚一些合并(这个和任务层的融合比还是early fusion),这也是它的第二个发现,这一点和上个论文观点一致。算法流程:
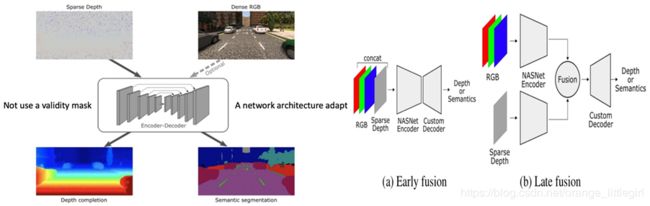
前后两种合并方式的结果示意:

4. 任务层融合
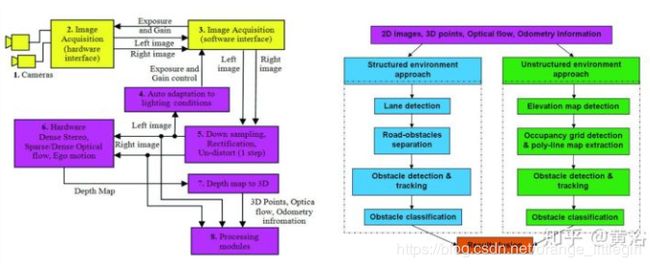
对于摄像头和激光雷达摄像头的感知任务来说, 都可用于进行车道线检测。除此之外,激光雷达还可用于路牙检测。对于车牌识别以及道路两边,比如限速牌和红绿灯的识别,主要还是用摄像头来完成。如果对障碍物的识别,摄像头可以很容易通过深度学习把障碍物进行细致分类。但对激光雷达而言,它对障碍物只能分一些大类,但对物体运动状态的判断主要靠激光雷达完成。任务级融合:障碍物检测/分类,跟踪,分割和定位。有时候融合可能在某一级的特征空间进行,这个也会随任务不同而变化。
4.1 传统之障碍物检测跟踪
- 双目和激光雷达融合
法国INRIA利用做十字路口安全驾驶系统的障碍物检测[1]。
双目算法:
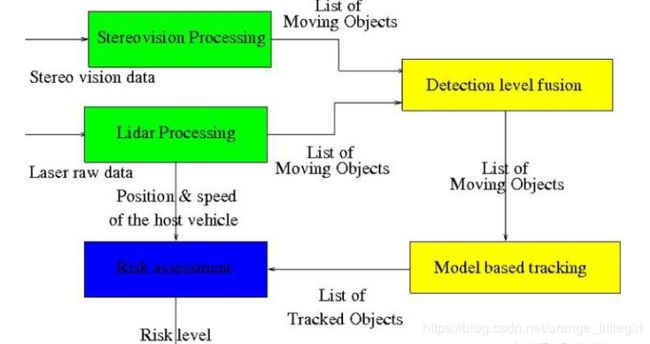
- 激光雷达和单摄像头融合
用一个Bayesian分类器合并两个检测器的结果送进跟踪器[2], 算法流程:
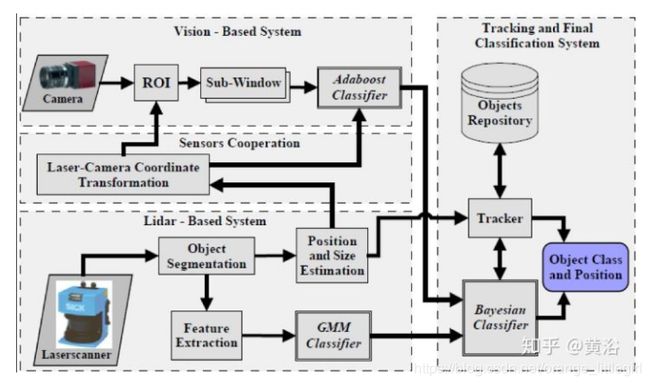
- 单目和激光雷达融合
图像数据的检测器用DPM算法,激光雷达点云数据检测采用自己提出的3D Morph算法,融合方式如加权和[3], 算法流程:

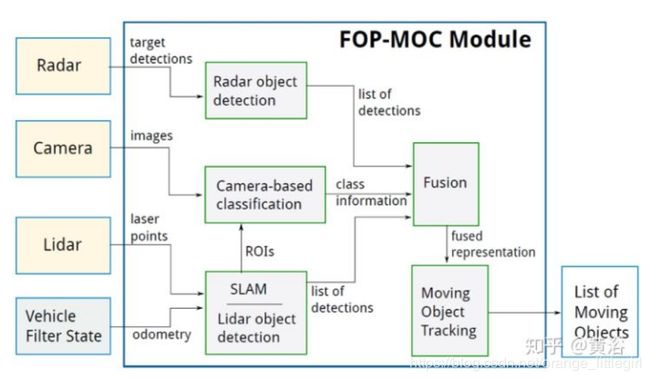
- 激光雷达,摄像头和毫米波雷达融合
把激光雷达,摄像头和毫米波雷达的数据在障碍物检测任务进行融合, 基于D-S证据理论[4]
4.2 传统之多传感器定位
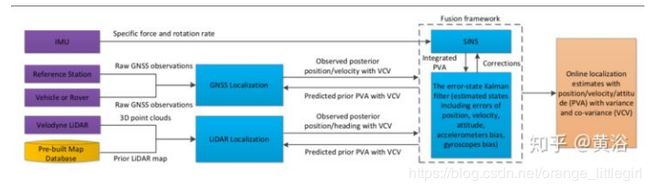
- 激光雷达64线,雷达,摄像头,GPS-IMU(RTK),还有HD Map
百度Apollo传感器融合用于车辆定位, 传感器配置有激光雷达64线,雷达,摄像头,GPS-IMU(RTK),还有HD Map。整个融合框架是基于EKF(扩展卡尔曼滤波器):估计最优的position, velocity, attitude (PVA)[5]。

-视觉里程计和激光里程计
该方法是在VO的基础上增加激光雷达点云信息[6]。这是系统框架:

4.3 深度学习之障碍物检测跟踪
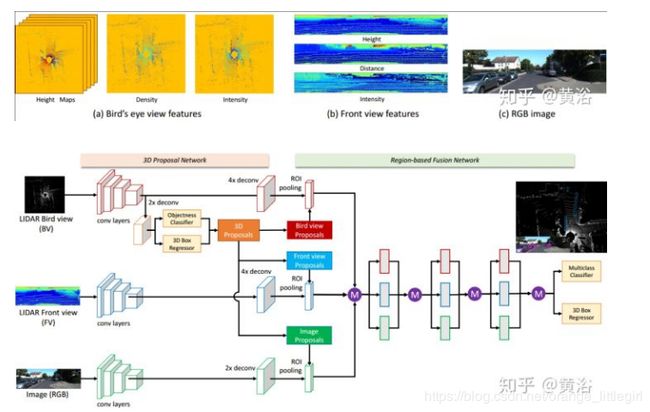
- 最常见的是利用激光雷达和相机进行障碍物检测:
采用激光雷达点云的鸟瞰图和前视图像两个方向的投影和RGB图像共同构成目标检测的输入,检测器类似两步法,其中region proposal被3D proposal导出的bird view/frontal view proposal和2D image proposal结合所取代[7]。
- 利用激光雷达和相机进行障碍物跟踪层融合:
还是采用tracking by detection思路,训练了三个CNN模型,即detectionnet,matchingnet和scoringnet[8]。
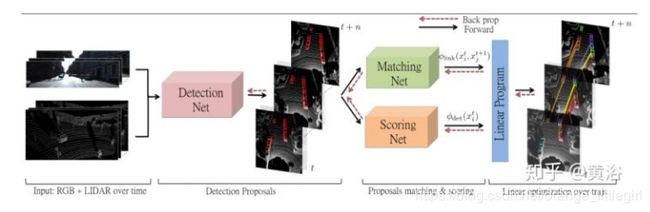
4.4 深度学习之定位
- 定位
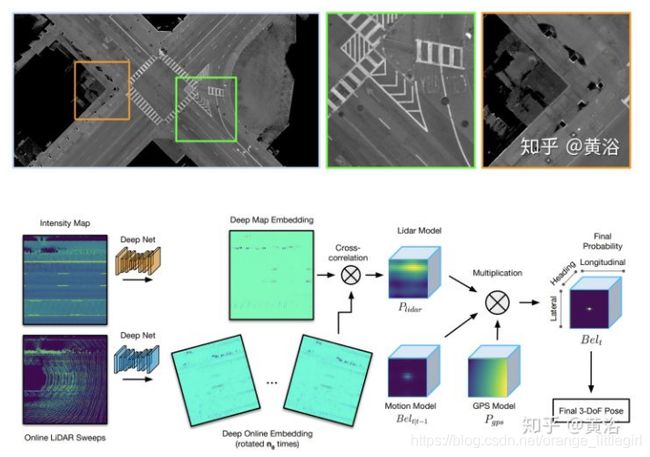
激光雷达灰度图像(反射值)和点云定位进行融合, 两种定位方法都用了卷积网络进行搜索
采用激光雷达扫描(利用卷积网络)的地面反射图来定位车辆,下面可以看到这种灰度图的样子。
引用文献
[1] Intersection Safety using Lidar and Stereo sensors.
[2] LiDAR and Camera-based Pedestrian and Vehicle Detection.
[3] 2D/3D Sensor Exploitation and Fusion for Detection.
[4] Multiple Sensor Fusion and Classification for Moving Object Detection and Tracking.
[5] Robust and Precise Vehicle Localization based on Multi-sensor Fusion in Diverse City Scenes.
[6] Real-time Depth Enhanced Monocular Odometry.
[7] Multi-View 3D Object Detection Network for Autonomous Driving.
[8] End-to-end Learning of Multi-sensor 3D Tracking by Detection.
[9] Learning to Localize Using a LiDAR Intensity Map.