2020年3月12日学习笔记
个人学习笔记,可能存在错误,仅供参考,部分内容来自网上,侵删
目录
- 任务内容
- python学习
- torch.squeeze()和torch.unsqueeze()用法
- np.argsort()
- index[::-1]是逆序切片
- np.setdiff1d
- ReID评估标准
- 1. rank-n
- 2.Precision & Recall
- 3、mAP
- 4、CMC
- 5、ROC
- 6、PR曲线
任务内容
- 读懂
evalute.py和demo.py - 尝试界面编程
python学习
torch.squeeze()和torch.unsqueeze()用法
torch.squeeze() 这个函数主要对数据的维度进行压缩,去掉维数为1的的维度,默认是将a中所有为1的维度删掉。也可以通过dim指定位置,删掉指定位置的维数为1的维度。
torch.unsqueeze()这个函数主要是对数据维度进行扩充。需要通过dim指定位置,给指定位置加上维数为1的维度。
np.argsort()
将numpy数组中元素从小到大排列并输出索引
a=np.array([3,2,-1,7,6])
print(np.argsort(a))
>>[2 1 0 4 3]
index[::-1]是逆序切片
np.setdiff1d
setdiff1d(ar1, ar2, assume_unique=False)
1.功能:找到2个数组中集合元素的差异。
2.返回值:在ar1中但不在ar2中的已排序的唯一值。
3.参数:
ar1:array_like 输入数组。
ar2:array_like 输入比较数组。
assume_unique:bool。如果为True,则假定输入数组是唯一的,即可以加快计算速度。 默认值为False
- assume_unique = False的情况:
a = np.array([8,2,3,2,4,1])
b = np.array([7,4,5,6,3])
c = np.setdiff1d(a, b)
print(c)#[1 2 8]
- assume_unique = True的情况:
a = np.array([8,2,3,2,4,1])
b = np.array([7,4,5,6,3])
c = np.setdiff1d(a, b,True)
print(c)#[8 2 2 1]
np.intersect1d计算交集,和setdiff1d参数类似,后者实际是求差集
ReID评估标准
来源:CSDN
在此之前,看一下对行人重识别的解释
在毕设代码evaluate_gpu.py中,计算的思路如下:
遍历每个query,对于每个query,找到gallery中跟当前query属于同一个ID但是是不同camera下的图片,这些图片被认为是good_image,其他的图片就是junk_image,然后对所有gallery与当前query的距离做个升序排序,接着就对当前query计算AP,cmc(rank)
1. rank-n
搜索结果中最靠前(置信度最高)的n张图有正确结果的概率。
例如: lable为 m1,在100个样本中搜索。
如果识别结果是 m1、m2、m3、m4、m5……,则此时rank-1的正确率
为100%;rank-2的正确率也为100%;rank-5的正确率也为100%;
如果识别结果是 m2、m1、m3、m4、m5……,则此时rank-1的正确率
为0%;rank-2的正确率为100%;rank-5的正确率也为100%;
如果识别结果是 m2、m3、m4、m5、m1……,则此时rank-1的正确率
为0%;rank-2的正确率为0%;rank-5的正确率为100%
2.Precision & Recall
参考:CSDN-1,简书
TP : True Positive 预测为1,实际也为1
TN:True Nagetive 预测为0,实际也为0
FP:False Positive 预测为1,实际为0的
FN:False Nagetive 预测为0,实际为1的
预测\实际 正 负 正 TP FP 负 FN TN
Accuracy:准确率
预测正确的数量
T P + T N T P + T N + F P + F N \frac{TP+TN}{TP+TN+FP+FN} TP+TN+FP+FNTP+TN
Precision:精确率
它表示的是预测为正的样本(TP,FP)中有多少是真正的正样本
T P T P + F P \frac{TP}{TP+FP} TP+FPTP
Recall:召回率
表示样本中的正例(TP,FN)有多少被预测正确了
T P T P + F N \frac{TP}{TP+FN} TP+FNTP
F-score,也叫F1值
是精确率和召回率的调和均值
F 1 = 2 ∗ P ∗ R P + R F_1=\frac{2*P*R}{P+R} F1=P+R2∗P∗R
同样地:
F 1 = 2 T P 2 T P + F P + F N F_1=\frac{2TP}{2TP+FP+FN} F1=2TP+FP+FN2TP
3、mAP
AP(平均Precision,即平均精度)衡量的是学出来的模型在单个类别上的好坏。mAP衡量的是学出的模型在所有类别上的好坏,也即PR曲线线下的面积(PR曲线: 所有样本的precision和recall绘制在图里)表示

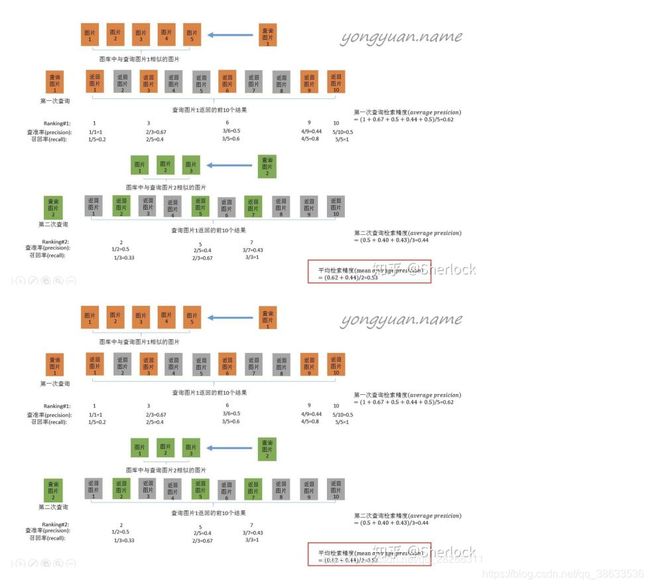
4、CMC
CMC曲线是算一种top-k的击中概率,主要用来评估闭集中rank的正确率
例如待识别人脸有3个(假如label为m1,m2,m3),同样对每一个人脸都有一个从高到低的得分。
比如人脸1结果为m1、m2、m3、m4、m5……,人脸2结果为m2、m1、m3、m4、m5……,人脸3结果m3、m1、m2、m4、m5……,则此时rank-1的正确率为(1+1+1)/3=100%;rank-2的正确率也为(1+1+1)/3=100%;rank-5的正确率也为(1+1+1)/3=100%;
比如人脸1结果为m4、m2、m3、m5、m6……,人脸2结果为m1、m2、m3、m4、m5……,人脸3结果m3、m1、m2、m4、m5……,则此时rank-1的正确率为(0+0+1)/3=33.33%;rank-2的正确率为(0+1+1)/3=66.66%;rank-5的正确率也为(0+1+1)/3=66.66%;
PS:和rank好像,我在此时间点还未搞清楚
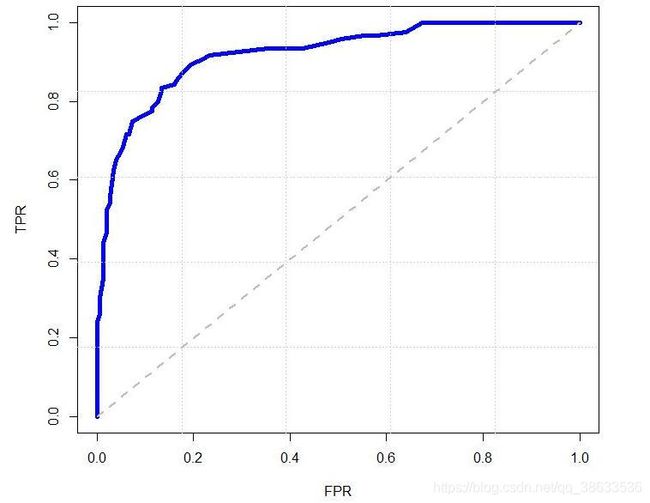
5、ROC
ROC曲线是检测、分类、识别任务中很常用的一项评价指标
ROC曲线上的每一点反映的是不同的阈值对应的FP(false positive)和TP(true positive)之间的关系
通常情况下,ROC曲线越靠近(0,1)坐标表示性能越好。
TPR=TP/(TP+FN)=Recall
FPR=FP/(FP+TN),预测为好人,实际是坏人的占所有坏人的比例
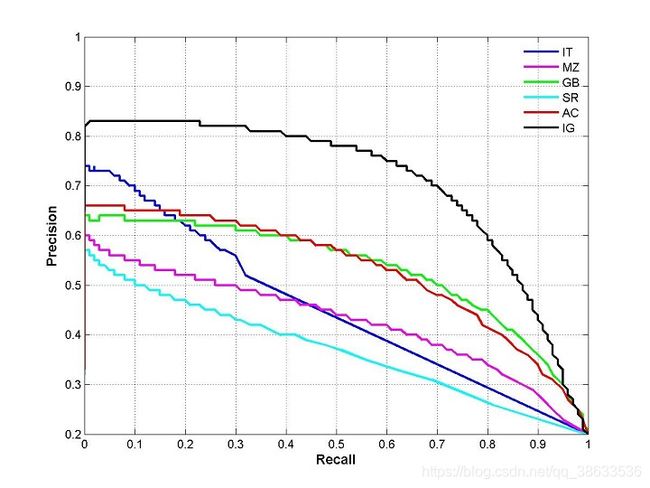
6、PR曲线
参考:
PR曲线深入理解
机器学习PRC
PR曲线就是精确率precision vs 召回率recall 曲线,以recall作为横坐标轴,precision作为纵坐标轴。