数据库 --> SQL 和 NoSQL 的区别
SQL 和 NoSQL 的区别
一、概念
SQL (Structured Query Language) 数据库,指关系型数据库。主要代表:SQL Server,Oracle,MySQL(开源),PostgreSQL(开源)。
NoSQL(Not Only SQL)泛指非关系型数据库。主要代表:MongoDB,Redis,CouchDB。
二、区别
1、存储方式
SQL数据存在特定结构的表中;而NoSQL则更加灵活和可扩展,存储方式可以省是JSON文档、哈希表或者其他方式。SQL通常以数据库表形式存储数据。举个栗子,存个学生借书数据:

而NoSQL存储方式比较灵活,比如使用类JSON文件存储上表中熊大的借阅数据:

2、表/数据集合的数据的关系
在SQL中,必须定义好表和字段结构后才能添加数据,例如定义表的主键(primary key),索引(index),触发器(trigger),存储过程(stored procedure)等。
表结构可以在被定义之后更新,但是如果有比较大的结构变更的话就会变得比较复杂。在NoSQL中,数据可以在任何时候任何地方添加,不需要先定义表。例如下面这段代码会自动创建一个新的"借阅表"数据集合:

NoSQL也可以在数据集中建立索引。以MongoDB为例,会自动在数据集合创建后创建唯一值_id字段,这样的话就可以在数据集创建后增加索引。
从这点来看,NoSQL可能更加适合初始化数据还不明确或者未定的项目中。
3、外部数据存储
SQL中如何需要增加外部关联数据的话,规范化做法是在原表中增加一个外键,关联外部数据表。例如需要在借阅表中增加审核人信息,先建立一个审核人表:

再在原来的借阅人表中增加审核人外键:

这样如果我们需要更新审核人个人信息的时候只需要更新审核人表而不需要对借阅人表做更新。而
在NoSQL中除了这种规范化的外部数据表做法以外,我们还能用如下的非规范化方式把外部数据直接放到原数据集中,以提高查询效率。缺点也比较明显,更新审核人数据的时候将会比较麻烦。

4、SQL中的JOIN查询
SQL中可以使用JOIN表链接方式将多个关系数据表中的数据用一条简单的查询语句查询出来。NoSQL暂未提供类似JOIN的查询方式对多个数据集中的数据做查询。所以大部分NoSQL使用非规范化的数据存储方式存储数据。
5、数据耦合性
SQL中不允许删除已经被使用的外部数据,例如审核人表中的"熊三"已经被分配给了借阅人熊大,那么在审核人表中将不允许删除熊三这条数据,
以保证数据完整性。而NoSQL中则没有这种强耦合的概念,可以随时删除任何数据。
6、事务
SQL中如果多张表数据需要同批次被更新,即如果其中一张表更新失败的话其他表也不能更新成功。这种场景可以通过事务来控制,可以在所有命令完成后再统一提交事务。
而NoSQL中没有事务这个概念,每一个数据集的操作都是原子级的。
7、增删改查语法
8、查询性能
在相同水平的系统设计的前提下,因为NoSQL中省略了JOIN查询的消耗,故理论上性能上是优于SQL的。
三、补充
目前许多大型互联网项目都会选用MySQL(或任何关系型数据库) + NoSQL的组合方案。
关系型数据库适合存储结构化数据,如用户的帐号、地址:
1)这些数据通常需要做结构化查询(嗯,好像是废话),比如join,这时候,关系型数据库就要胜出一筹
2)这些数据的规模、增长的速度通常是可以预期的
3)事务性、一致性
NoSQL适合存储非结构化数据,如文章、评论:
1)这些数据通常用于模糊处理,如全文搜索、机器学习
2)这些数据是海量的,而且增长的速度是难以预期的,
3)根据数据的特点,NoSQL数据库通常具有无限(至少接近)伸缩性
4)按key获取数据效率很高,但是对join或其他结构化查询的支持就比较差
基于它们的适用范围不同,目前主流架构才会采用组合方案,一个也不能少。目前为止,还没有出现一个能够通吃各种场景的数据库,而且根据 CAP理论,这样的数据库是不存在的。
注:CAP理论
CAP定理(CAP theorem)
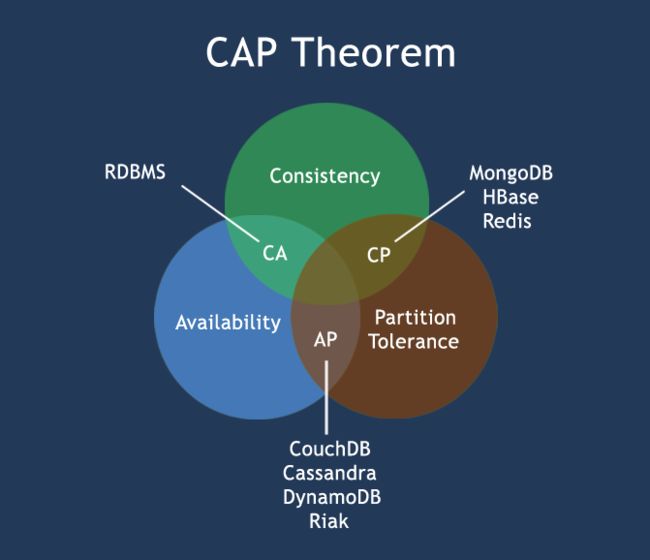
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
NoSQL的优点/缺点
优点:
- - 高可扩展性
- - 分布式计算
- - 低成本
- - 架构的灵活性,半结构化数据
- - 没有复杂的关系
缺点:
- - 没有标准化
- - 有限的查询功能(到目前为止)
- - 最终一致是不直观的程序
BASE
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble --基本可用
- Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
- Eventual Consistency -- 最终一致性, 也是是 ACID 的最终目的。
ACID vs BASE
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |