用python爬取链家二手房楼盘
前言
想看下最近房价是否能入手,抓取链家 二手房 、 新房 的信息,发现广州有些精装修 88平米 的 3房2厅 首付只要 29 万!平均 1.1万/平:

查看请求信息
本次用的是火狐浏览器32.0配合 firebug 和 httpfox 使用,基于 python3 环境,前期步骤:
1.首先打开 firefox 浏览器,清除网页所有的历史纪录,这是为了防止以前的 Cookie 影响服务器返回的数据。
2.F12 打开 firebug ,进入链家手机端首页https://m.lianjia.com,点击 网络 -> 头信息 ,查看请求的头部信息。

发现请求头信息如下,这个是后面要模拟的:

查看导航链接
点击 firebug 的查看元素箭头,选中导航查看元素:

发现导航的主要是在 class=inner post_ulog 的超链接元素 a 里面,这里用 BeautifulSoup 抓取名称和 href 就好,最后组成一个字典:
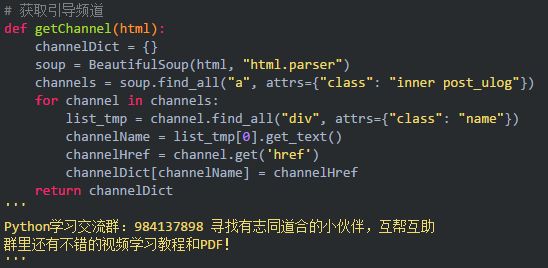
结果如下:
{'海外':'/i/','卖房':'/bj/yezhu/','新房':'/bj/loupan/fang/','找小区':'/bj/xiaoqu/','查成交':'/bj/chengjiao/','租房':'/chuzu/bj/zufang/','二手房':'/bj/ershoufang/index/','写字楼':'https://shang.lianjia.com/bj/'}
获取城市编码
点击页面低于按钮,获取城市编码:

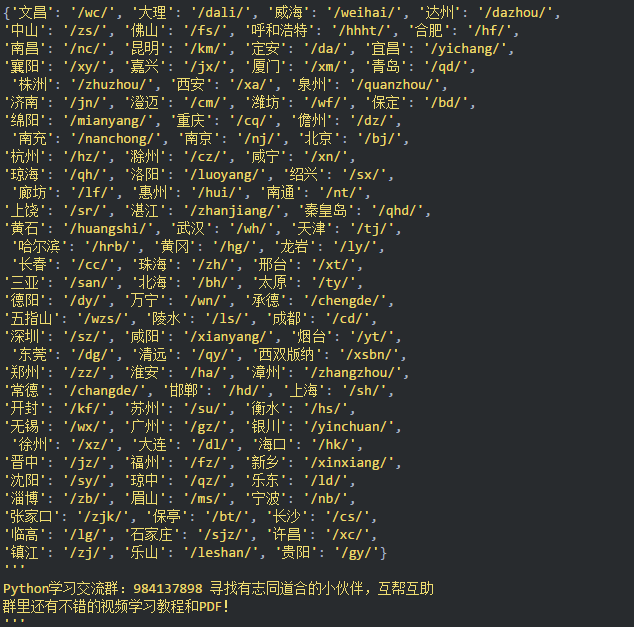
发现城市的编码主要在 class=block city_block 的 div 里面,如下抓取所有就好,这里需要的是广州,广州的城市编码是 gz :

结果如下:
模拟请求二手房
点击二手房链接进入二手房列表页面,发现列表页面的 url 是 https://m.lianjia.com/bj/ershoufang/index/ ,把网页往下拉进行翻页,发现下一页的 url 构造为:

只是在原来的网址后面添加了页码 pg1 ,但是在 httpfox 里面惊奇的发现了一段 json:

对于爬虫的各位作者有个忠告:能抓取json就抓取json!* json 是一个 API 接口,相比于网页来说更新频率低,网页架构很容易换掉,但是 API 接口一般不会换掉,且换掉后维护的成本比网页低。试想,接口只是一个 dict ,如果更新只要在代码里面改 key 就好了;而网页更新后,需要改的是 bs4 里面的元素,对于以后开发过多的爬虫来说,维护特别麻烦!
所以对于这里肯定是抓取 json,查看头部:

头部需要携带 cookie !
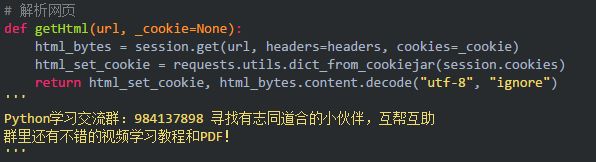
所以这里需要携带 cookie。而 requests 本身就有抓取携带 cookie 的写法。那么作者就在从获取导航链接、城市编码都获取更新 cookie。而在每一次 requests 请求的时候,返回 cookie 的代码为:
![]()
那么在导航链接、城市编码的时候,不仅仅返回网页的 html ,还多返回一个 cookie :

然后在请求头携带 cookie :
这里也模拟请求头携带 cookie 后抓取下来的 json 为:
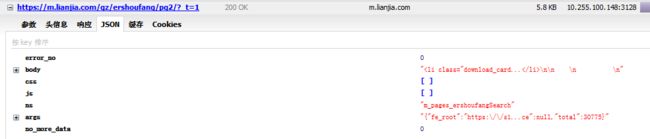
而主要的信息在 body 里面,直接解析 html 变成 dict ,提取 body 出来:

发现信息都在 class=item_list 里面,直接用 bs4 抓取即可。可以抓取到的信息为:标题、标签、房子构造、面积、总价、单价、房屋朝向、详情页 url 等:

获取信息的部分代码为:

封装代码
为了让代码更加的和谐,这里对代码进行了封装,包括如下几个方面:
选择城市
选择查看二手房、新房等
详情页抓取页数
计算首付
按照首付升序排列
目前只写那么多了,毕竟博文只教方法给读者,更多抓取的信息需要各位读者根据自己的需求添加
下载源码
作者已经将源码放到 github 上面了,包括 3 个 py 文件:
lianjia.py ,跳转页面到详情页的代码,为主代码
GetDetail.py,抓取详情页翻页的代码
GetInfo.py,提取详情页里面信息的代码
源代码地址为:
https://github.com/TTyb/lianjia