Presto Coordinator分布式改造
背景
自从上线SQL功能以来,经过两年的时间,随着sls业务的不断增长,每天处理1亿次query,扫描1000,000,000,000,000行日志(没错1000万亿行日志)。业务的增长也给系统带来无形的压力,如何保障在低延时的前提下提供这么大的负载是一个巨大的挑战。
挑战之一就是单master架构。在之前的文章中,我介绍过了presto的架构。coordinator是presto中负责query解析,任务调度,结果汇总的,集群监控的节点。其他的worker节点只负责接收单个task进行计算即可。coordinator的任务可谓是多而广,在整个集群中起到了不可替代的作用。一旦该节点出问题,整个集群不可用。
上图为集群平均cpu,下图第一个为coordinator的cpu,可见coordinator的负载一直处于高位,且明显高于普通的worker。
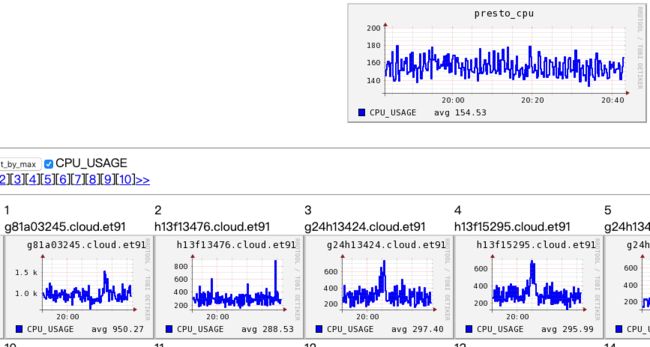
随着业务的上升,coordinator的几点瓶颈愈发凸显:
- 负责query的解析和任务分发,负载比较重,且随着业务增加,负载线性增加。而单机的性能有上限,无法横向扩展。
- 单coordinator节点无容灾,一旦宕机,恢复时间比较长。
为了解决以上问题,我下决心把coordinator改造成分布式。
coordinator主要工作内容
coordinator主要有几个功能:
- query的解析,任务调度,任务监控。
- 集群内存监控。
- 机器状态监控。
query任务流

query从提交到coordinator,到query执行完成,由coordinator负责管理,一个qeuery的具体流程包括:
- 队列排队,获取运行许可。
- 词法解析和语法解析,把SQL转换成抽象语法树。
- 语法优化,语法检查。利用预定义规则对语法数进行优化,例如剪枝优化。还有把单机plan改造成并行式plan。
- 对plan划分出不同的stage,并且按照并行度的需求,为每个stage生成多个task,每个task指定一台机器。形成最终的逻辑执行计划。
- stage代表的任务的上下游,task代表一个stage内的并行执行。一个stage内的task执行相同的任务,只是接收的数据不一样。
- 每个task调度到一个worker上,并且coordinator为每个task启动一个任务追踪,即TaskInfoFetcher,周期性轮训task的状态。
- 当轮训到task的状态发生改变时,回调改变stage-> query的状态,最终直到query的所有task都结束。
整个任务流中,像query解析,调度,监控等都可以在任意节点执行,不需要非得在全局唯一节点执行。 只有queue涉及到全局队列,需要在单点执行。
集群控制流
Presto集群控制只要有两方面内容:
- 集群状态控制
- 检查每台机器的状态,判断是ALIVE、SHUTDOWN中的哪个状态。
- 检查每台机器的各个内存池分配状态,终止超限query,以及提升大query的优先级。
- Query状态控制
- 轮询每个task的状态,通过状态机管理query状态。

集群内存管理
Presto采用逻辑的内存池,来管理不同类型的内存需求。
Presto把整个内存划分成三个内存池,分别是System Pool ,Reserved Pool, General Pool。
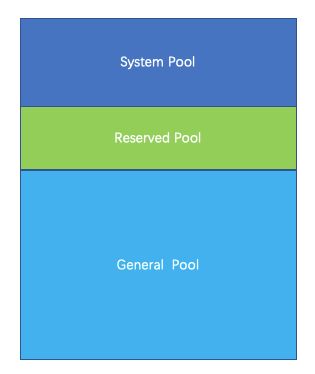
- System Pool 是用来保留给系统使用的,默认为40%的内存空间留给系统使用。
- Reserved Pool和General Pool 是用来分配query运行时内存的。
- 其中大部分的query使用general Pool。 而最大的一个query,使用Reserved Pool, 所以Reserved Pool的空间等同于一个query在一个机器上运行使用的最大空间大小,默认是10%的空间。
- General则享有除了System Pool和General Pool之外的其他内存空间。

Presto内存管理,分两部分:
- query内存管理
- query划分成很多task, 每个task会有一个线程循环获取task的状态,包括task所用内存。汇总成query所用内存。
- 如果query的汇总内存超过一定大小,则强制终止该query。
- 机器内存管理
- coordinator有一个线程,定时的轮训每台机器,查看当前的机器内存状态。
- 当query内存和机器内存汇总之后,coordinator会挑选出一个内存使用最大的query,分配给Reserved Pool。
内存管理是由coordinator来管理的, coordinator每秒钟做一次判断,指定某个query在所有的机器上都能使用reserved 内存。那么问题来了,如果某台机器上,,没有运行该query,那岂不是该机器预留的内存浪费了?为什么不在单台机器上挑出来一个最大的task执行。原因还是死锁,假如query,在其他机器上享有reserved内存,很快执行结束。但是在某一台机器上不是最大的task,一直得不到运行,导致该query无法结束。
Coordinator分布式改造
从上边的介绍中,我们可以看出,只能在集群唯一节点进行的操作有:
- 全局队列。
- 机器状态监控。
- 集群内存状态管理。
二coordinator上负载最重的操作是query的task状态管理。一个query会分配若干个task,这个膨胀是很大的。每个task都要轮询状态信息。这部分逻辑是可以分布式搞得,不必放在全局唯一节点进行。
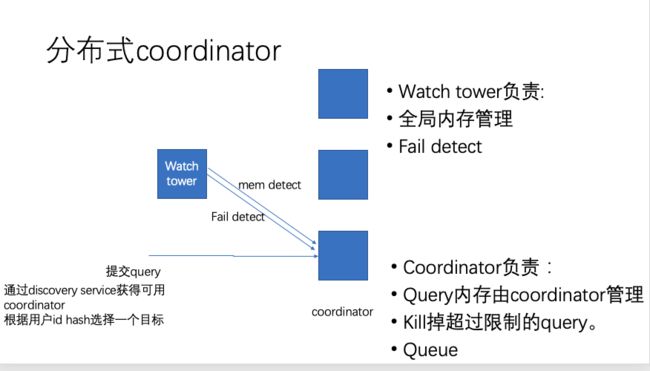
coordinator改造方案,就是把一些不是全局性的操作,都拆分到不同节点去做。而把全局性的操作放到一个节点。所以原来的coordinator会变成两个角色,watch tower和新coordinator:

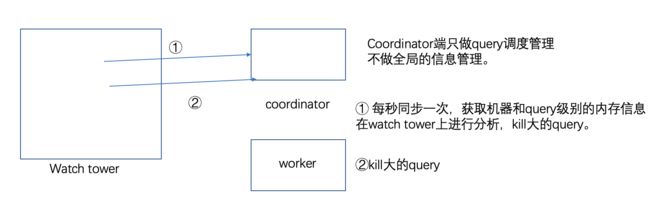
Watch tower:
只负责集群的监控,不负责跟query相关的工作。
- 集群内存管理,周期性轮询每台机器的内存分配状态,把最大的query提升导reserved memory pool。
- 机器状态管理,周期性轮询每台机器状态,是否ALIVE、SHUTDOWN。
由于coordinator需要知道每台机器的状态、内存,因此在coordinate向每台机器同步信息时,会同时把相关状态同步给coordinator。
Coordinator:
coordinator只专心做query相关的工作,接受请求,解析、调度、监控所有的task。
队列处理
presto的队列模型,可以设置query运行的最大并发度和最大排队数。这些参数可以时用户级别,也可以是整个集群的级别。
在官方的presto中,由于只有一个coordinator节点,可以很容易在单点控制整个集群的执行并发度。分拆成多个coordinator并发执行之后,控制整个集群的并发度变得比较困难。因而我们选择在单个coordinator上控制运行在本机的并发度。
客户端
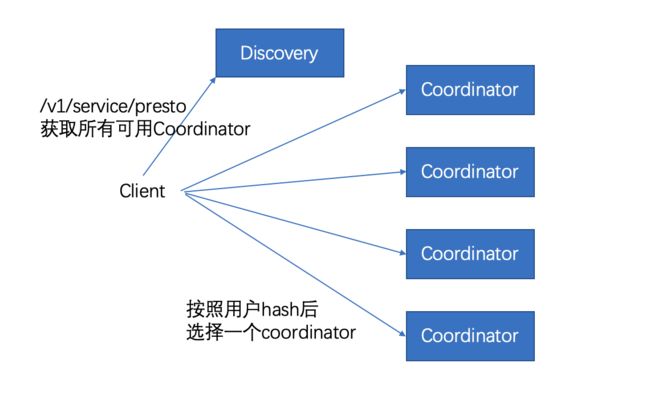
改造成并发coordinator后,client端从Discovery获取到所有的coordinator(coordiantor向discovery回报心跳时,增加了标识coordinator)。并且把coordinator按照地址排序,保证所有的client获取到的都是同样的顺序。
当接收到SQL请求后,client按照user的hash值,选择一个coordinator发送。这样就可以保证同一个用户的SQL只发送导一个coordinator,从而控制并发度。当然如果coordinator发生扩容缩容,在短时间内,coordinate的顺序会发生改变,影响队列。
总结
在完成分布式改造后, coordinator可以做到水平扩展,解决了coordinator的单点问题。改造后的效果:

CPU消耗比较高的Coordinator经过分布式改造后,有3个coordinator,可以看出每个coordinator的CPU仍然很高。这是由于coordinator上负责整个query的运行监控,如果一个query分配的task非常多,那么是需要启动很多后台任务轮询task状态,这对coordinator的负载压力是很大的。虽然我们可以做到水平扩展coordinator,但是由于单个coordinator的最大并发有限,也影响了整个集群的性能。接下来我们也会继续对这部分逻辑进行改造,期望能够优化coordinator的性能。
招聘阿里云智能事业群-智能日志分析研发专家-杭州/上海 扫码加我