Densely Connected Convolutional Networks_论⽂周报
Densely Connected Convolutional Networks_论⽂周报
Gao Huang,Zhuang Liu,Laurens van der Maaten
CVPR 2017
为什么提出?
DenseNet的提出很⼤程度是基于Stochastic depth(随机深度⽹络)提出来的,因为该⽂章在训练过程中随机地丢掉⼀些层,反⽽可以显著的提⾼ResNet的泛化能⼒,这表明ResNet许多层是⼏乎没有贡献的,即有明显的冗余性。
再者,Stochastic随机地丢弃⼀些层,构造了⼀种任意两层可以直接相连的可能,⽽且这是有效的,这为DenseNet结构的提出提供了有⼒的⽀持。
怎么做?
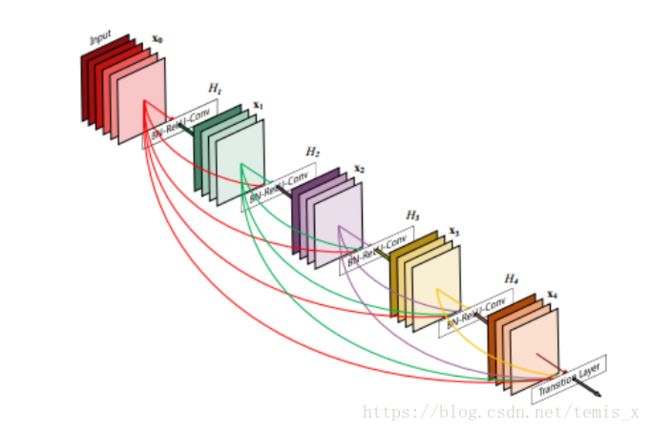
基于上述两点,为了确保⽹络各层的最⼤信息流,作者把⽹络中的每⼀层都直接与其前⾯的层连接起来,改善信息流,让梯度能容易地传到前⾯去,并强调了特征重⽤;同时把每⼀层都设置得⽐较”窄“,即学习⾮常少的feature-maps,达到降低冗余性的⽬的。先来看⼀下dense block的结构。
Dense Block
假设![]() 为⾮线性变换,其中
为⾮线性变换,其中 指⽹络的第层,定义
指⽹络的第层,定义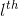 层的输出为
层的输出为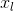 .
.
假设层得到所有前⾯的层输⼊为![]() ,且分别是由第0,...,l-1层输出的,那么有
,且分别是由第0,...,l-1层输出的,那么有
![]()
不同于ResNet的![]() ,这⾥的
,这⾥的![]() 做的操作是concat,接着包含三个连续的操作,即BN − ReLU − Conv(3 × 3)
做的操作是concat,接着包含三个连续的操作,即BN − ReLU − Conv(3 × 3)
那么,第层有个输⼊,并且它⾃⼰的feature-map输出给后⾯的![]() 层,所以总共有
层,所以总共有![]() 个connections。
个connections。
由于concat操作要求feature-maps的size是⼀致的,所以难以进⾏pooling操作,所以最终的⽹络不是![]() ⼀直堆
⼀直堆
叠下去,⽽是在block之间加⼊⼀个过渡层(transition layers)。最终的⽹络结构如下图:

Growth Rate
上⾯说到每个dense block每层的feature-maps是固定的,假设每个block每层的feature-maps个数为k,那么我们
称k为Growth rate。
那么这⾥有个计算,假设![]() 每层产⽣k个feature-maps,即Growth rate为k,设该block共有l层,那么接着该block
每层产⽣k个feature-maps,即Growth rate为k,设该block共有l层,那么接着该block
的那⼀层的输⼊channel数为![]() ,其中
,其中![]() 为该block最后⼀层的输出channel数。
为该block最后⼀层的输出channel数。
Transition layers
每个block之间的层作者把它定义为transition layers,论⽂中transition layers的操作包括两部分,即Conv(1 × 1) − AvgPooling(2 × 2)
由于每个dense block都会带来通道数的增加。使⽤过多则会导致过于复杂的模型复杂度。⽽transition layers则⽤来控制模型复杂度,通过1 × 1卷积层来减⼩channel数;同时使⽤步幅为2的平均池化层来将⾼宽减半来进⼀步降低复杂度。
这样的操作也可以有效地抑制ResNet存在的冗余的问题,把⽹络做”窄“。
为了进⼀步提⾼模型的紧凑性,transition layers还有⼀个超参数 来控制feature-maps的数量,即假设dense
来控制feature-maps的数量,即假设dense
block的feature-maps为m,那么跟随block其后的transition layers 产⽣![]() 个feature-maps输出,,其中
个feature-maps输出,,其中![]() ,则
,则
- 当
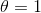 时,transition layers的feature-maps数量不改变;
时,transition layers的feature-maps数量不改变; - 当
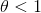 时,transition layers的feature-maps数量减半,称为DenseNet-C,论⽂实验中设为0.5。
时,transition layers的feature-maps数量减半,称为DenseNet-C,论⽂实验中设为0.5。
瓶颈设计
受ResNet瓶颈设计的启发,瓶颈设计可以利⽤1 × 1的卷积,有效地控制feature-maps的数量,降低模型的复杂
度与冗余性,提⾼计算效率,本⽂也延续了这种思路,在3 × 3卷积之前使⽤1 × 1卷积来控制通道数,具体操作即BN − ReLU − Conv(1 × 1) − BN − ReLU − Conv(3 × 3)。
DenseNet的优点
1 . 解决了梯度消失的问题,隐含着深度监督的效果:
- 这很容易理解,因为任意两层都能直接相连,loss的梯度就相对容易传递下去。
- 隐含的深度监督:这个不同于DSN,不是增加辅助分类器来进⾏深度监督,⽽是因为每⼀层都与后⾯层有直接相连的通路,相当于每⼀层都接收到了额外的、来⾃这些direct connection的监督,使得梯度可以⽐较容易地传递下去。
2 . ⼤⼤减少了参数数量:
每个卷积层的输出feature map的数量都很⼩(⼩于100),⼤⼤降低了⽹络的冗余性与复杂性,⽽且有过渡层的存在,⽹络的复杂度也会得到⼀定的控制。
3 . Feature Reuse 特征重⽤:
Denseblock任意两层都可以直接相连,所以每⼀层⾃然可以重⽤前⾯层的特征,这样的设计可以把特征的利⽤率⼤⼤提⾼。
下⾯是⼀个特征重⽤的热点图(heat map),
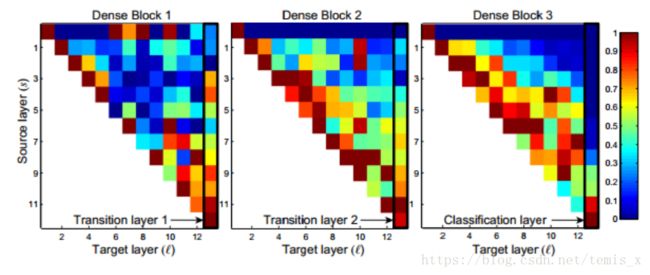
这个图可以说明⼏下⼏点:
- 后⾯的层还是会直接使⽤到前⾯的层的feature;
- 每⼀层使⽤⽐较靠近的层的feature的⽐例会⽐较⼤;
- transition layers的权重分散在前⾯各层中,说明它的信息流从第⼀层到最后⼀层基本上很少有间接流动,⼤多数是直接的传递;
- 最后⼀个分类器层,权重都集中在⽹络靠后的位置,说明⽹络信息流是贯穿整个block每⼀层传递上来的⽽不是直接传递过来的,说明⼀些更⾼层次的feature是由⽹络⽐较深的层产⽣的。
联想与理解
- ⼀个不⾜:
任意两层都有connection,这样的连接会不会出现冗余,有些特征重⽤很少,从热度图也可以看出来某些连接的负载⽐较⼩。那么可不可以尝试通过随机地剪 掉⼀些连接来验证⼀下⽹络是否有冗余性呢,以及进⾏有针对性的⽹络剪枝,使模型的效率更⾼。
- 与Inception相⽐:
其实这种concat的想法在inception⾥就有体现,只不过inception是在宽度上进⾏concat,它concat的特征来⾃于同⼀层,⽽Dense是来⾃于不同层的特征进⾏concat。
- 特征重⽤与特征融合:
我感觉DenseNet这种特征重⽤的⽅式与特征融合挺相似的,但是它不是⼈为地选择哪些层的特征进⾏融合,⽽是有⼀种⾃适应性。换句话说就是,由于任意两层都有连接,所以是不是每⼀层都能够⾃适应地进⾏特征融合,这可能可以增强⽹络每⼀层的表达能⼒。