ResNeSt 论文阅读笔记
论文:《ResNeSt: Split-Attention Networks》
论文链接:https://hangzhang.org/files/resnest.pdf
代码链接:https://github.com/zhanghang1989/ResNeSt
摘要
尽管图像分类模型最近一直在继续发展,但是由于其简单且模块化的结构,大多数下游应用(例如目标检测和语义分段)仍将ResNet变体用作backbone。 我们提出了一个模块化的Split-Attention block,该block可实现跨feature map groups的attention。 通过以ResNet样式堆叠这些Split-Attention块,我们获得了一个称为ResNeSt的新ResNet变体。 我们的网络保留了完整的ResNet结构,可直接用于下游任务,而不会引起额外的计算成本。
ResNeSt模型的模型复杂度优于其他网络。 例如,ResNeSt-50使用224×224的单个crop-size在ImageNet上实现了81.13%的top-1 accuracy,比以前的最佳ResNet变种高出1%以上。 此改进还有助于下游任务,包括目标检测,实例分割和语义分割。 例如,通过简单地用ResNeSt-50替换ResNet-50backbone,我们将MS-COCO上的Faster RCNN的mAP从39.3%提高到42.3%,并将ADE20K上的DeeplabV3的mIoU从42.1%提高到45.1%。
1 引言
图像分类是计算机视觉研究的基本任务。 经过图像分类训练的网络通常充当为其他应用设计的神经网络的backbone,例如目标检测[22,46],语义分割[6、43、73]和姿态估计[14、58]。 最近的工作通过大规模的神经体系结构搜索(NAS)显着提高了图像分类的准确性[45,55]。 尽管具有最先进的性能,但这些基于NAS的模型通常并未针对通用/商业处理硬件(CPU / GPU)上的训练效率或内存使用情况进行优化[36]。 由于过多的内存消耗,这些模型的某些较大版本甚至无法在每台设备batch-size合适的GPU上进行训练2 [55]。 这限制了将NAS派生的模型用于其他应用,尤其是涉及密集预测(例如分割)的任务。(NAS的局限性)
关于下游应用的最新工作仍然使用ResNet [23]或其变体之一作为backbone CNN。其简单的模块化设计可轻松适应各种任务。但是,由于ResNet模型最初是为图像分类而设计的,由于感受野大小有限且缺乏跨通道交互,它们可能不适合各种下游应用。这意味着要提高给定计算机视觉任务的性能,需要进行“网络手术”来修改ResNet,以使其对特定任务更加有效。例如,某些方法添加了金字塔模块[8,69]或引入了long-range连接[ [56]或使用跨channel特征图attention[15,65]。虽然这些方法确实提高了某些任务的学习学习性能,但它们提出了一个问题:我们是否可以创建具有通用改进特征表示的通用backbone,从而提高性能跨通道信息同时显示在下游应用中是成功的[56、64、65],而最近的图像分类网络则更侧重于分组或深度卷积[27、28、54、60]。尽管它们在分类任务中具有出色的计算能力和准确性,但这些模型无法很好地转移到其他任务,因为它们的孤立表示无法捕获跨channel关系[27,2 8]。因此,具有跨通道表示的网络是理想的。
作为本文的第一个贡献,我们探索了ResNet [23]的简单体系结构修改,将feature map 拆分attention纳入各个网络模块中。 更具体地说,我们的每个block都将特征图分为几组(沿通道维数)和更细粒度的子组或splits,其中,每个组的特征表示是通过其分割表示的加权组合确定的( 根据全局上下文信息选择权重)。 我们将结果单元称为Split-Attention block,它保持简单且模块化。 通过堆叠几个Split-Attention block,我们创建了一个类似ResNet的网络,称为ResNeSt(代表“ split”)。我们的体系结构不需要比现有ResNet变量更多的计算,并且很容易被用作其他视觉任务的backbone 。
本文的第二个贡献是图像分类和迁移学习应用的大规模基准测试。 我们发现,利用ResNeSt backbone的模型能够在几个任务上达到最先进的性能,即:图像分类,目标检测,实例分割和语义分割。 提出的ResNeSt优于所有现有的ResNet变体,并且具有相同的计算效率,甚至比通过神经结构搜索(NAS)生成的最新的CNN模型[55]更好地实现了speed-accuracy的折衷,如表1所示。 在MS-COCO实例分割中,使用ResNeSt-101backbone的Cascade RCNN [3]模型实现了48.3%的boxes mAP和41.56%的mask mAP。 我们的单个DeepLabV3 [7]模型再次使用ResNeSt-101backbone,在ADE20K场景解析验证集上的mIoU达到46.9%,比以前的最佳结果高出1%以上。 其他结果可以在第5节和第6节中找到。

表1:使用官方代码实现在GPU上(左)accuracy和latency的trade-off(第5节中的详细信息)。 (右上)使用ResNeSt在ImageNet上的Top-1accuracy。 (右下)迁移学习结果:MS-COCO上的目标检测mAP [42]和ADE20K上的语义分割mIoU [71]
2 相关工作
现代CNN结构。自从AlexNet [34]以来,深度卷积神经网络[35]主导了图像分类。随着这种趋势,研究已经从工程手工特征转移到工程网络体系结构。 NIN [40]首先使用全局平均池化层来代替沉重的全连接层,并采用1×1卷积层来学习特征图通道的非线性组合,这是第一类特征图注意机制。 VGG-Net [47]提出了一种模块化的网络设计策略,将相同类型的网络blocks重复堆叠,从而简化了网络设计的工作流程,并为下游应用提供了迁移学习的机会。Highway network[50]引入了公路连接,使信息跨几层流动而不会衰减,并有助于网络收敛。 ResNet [23]建立在开拓性工作成功的基础上,引入了identity skip connecting,减轻了深度神经网络中消失梯度的难度,并允许网络学习更深层的特征表示。 ResNet已成为最成功的CNN架构之一,已被各种计算机视觉应用采用。
Multi-path 和 特征图 Attention。多路径表示已在GoogleNet [52]中取得成功,其中每个网络块均由不同的卷积内核组成。 ResNeXt [61]在ResNet bottle block中采用组卷积[34],将多路径结构转换为统一操作。 SE-Net [29]通过自适应地重新校准通道特征响应来引入通道注意机制。 SK-Net [38]引起了两个网络分支对特征图的关注。 受先前方法的启发,我们的网络将channel-wise的注意力概括为特征图组表示,可以使用统一的CNN运算符对其进行模块化和加速。
神经结构搜索。随着计算能力的提高,人们的兴趣已经开始从手动设计的体系结构转移到系统搜索的体系结构,这些体系结构可以适应特定任务。 最近的神经体系结构搜索算法已经自适应地产生了CNN体系结构,这些体系结构实现了最新的分类性能,例如:AmoebaNet [45],MNASNet [54]和EfficientNet [55]。 尽管元网络结构在图像分类方面取得了巨大成功,但它们彼此之间却截然不同,这使得下游模型难以建立。 相反,我们的模型保留了ResNet元结构,可以将其直接应用于许多现有的下游模型[22、41、46、69]。 我们的方法还可以扩大神经体系结构搜索的搜索空间,并有可能提高整体性能,这可以在以后的工作中进行研究。
3 Split-Attention Networks
现在,我们引入Split-Attention blocks,该blocks启用了跨不同featuremap组的feature map attention。 稍后,我们将描述我们的网络实例化以及如何通过标准CNN操作加速此体系结构。
3.1 Split-Attention Block
我们的Split-Attention blocks是一个计算单元,由特征图组和Split Attention操作组成。 图1(右)描绘了Split-Attention模块的概述。

图1:将我们的ResNeSt block与SE-Net [30]和SK-Net [38]进行比较。 图2中显示了Split-Attention单元的详细视图。为简单起见,我们在cardinality-major视图中显示ResNeSt block(具有相同ardinal group index的feature map组彼此相邻)。 我们在实际实现中使用radix-major,可以通过组卷积和标准CNN层对其进行模块化和加速(请参阅补充材料)。

图2:cardinal group内的Split-Attention。 为了简化图中的可视化,我们在该图中使用![]() 。
。
特征图组。如在ResNeXt块[61]中一样,特征可以分为几组,特征图组的数量由基数(cardinality)超参数K给出。我们将所得的特征图组称为基数组(cardinal groups)。 我们引入了一个新的基数(radix)超参数R,该基数指示cardinal group内的split 数目,因此特征组的总数为G = KR。 我们可以应用一系列变换![]() 到每个单独的组,则对于每个组的中间表示为
到每个单独的组,则对于每个组的中间表示为![]() 。
。
Cardinal Groups中的Split Attention。继[30,38]之后,每个cardinal的组合表示可以通过跨多个splits的逐元素求和来融合而获得。 第 k 个cardinal group的表示为![]() ,其中
,其中![]() ,并且H,W和C 是block输出特征图的大小。 可以使用跨空间维度
,并且H,W和C 是block输出特征图的大小。 可以使用跨空间维度![]() 的全局平均池来收集embedded channel-wise统计信息的全局上下文信息[29,38]。 在这里,第 c 个分量的计算公式为:
的全局平均池来收集embedded channel-wise统计信息的全局上下文信息[29,38]。 在这里,第 c 个分量的计算公式为:
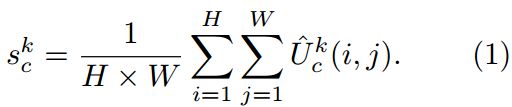
cardinal group组表示V k 2 RH×W×C = K的加权融合是使用channel-wise的soft attention聚合的,其中,每个特征图通道均使用加权splits组合产生。 第c个通道的计算公式为:
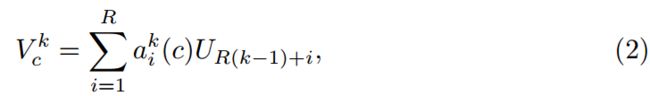
其中![]() 通过(soft)分配权重表示:
通过(soft)分配权重表示:
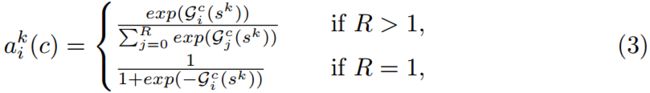
并且映射![]() 根据全局上下文表示
根据全局上下文表示![]() 确定第 c 个channel的每个split的权重。
确定第 c 个channel的每个split的权重。
ResNeSt Block。然后,将cardinal group表示形式沿通道维度连接起来:![]() 。与标准残差块一样,如果输入和输出特征图共享相同的形状,则使用shortcut connection:
。与标准残差块一样,如果输入和输出特征图共享相同的形状,则使用shortcut connection:![]() 生成我们的Split-Attention blocks的最终输出 Y。 对于具有跨步的blocks,将适当的变换 T 应用于shortcut connection以对齐输出形状:
生成我们的Split-Attention blocks的最终输出 Y。 对于具有跨步的blocks,将适当的变换 T 应用于shortcut connection以对齐输出形状:![]() 。 例如, T可以是跨步卷积(stride convolution)或卷积-池化组合。
。 例如, T可以是跨步卷积(stride convolution)或卷积-池化组合。
Instantiation, Acceleration, and Computational Costs。图1(右)显示了我们的Split-Attention块的实例,其中组变换![]() 是一个1×1卷积,然后是3×3卷积,并且注意权重函数
是一个1×1卷积,然后是3×3卷积,并且注意权重函数![]() 使用带有ReLU激活的两个全连接层进行参数化。 我们以cardinality-major的视图(具有相同cardinality index的feature map组彼此相邻)绘制此图,以方便地描述总体逻辑。 通过将布局切换到radix-major视图,可以使用标准CNN层(例如组卷积,组全连接的层和softmax操作)轻松加速这个block,我们将在补充材料中对其进行详细描述。 Split-Attention块的参数数量和FLOPS与具有相同cardinality和通道数量的残差块[23,60]大致相同。
使用带有ReLU激活的两个全连接层进行参数化。 我们以cardinality-major的视图(具有相同cardinality index的feature map组彼此相邻)绘制此图,以方便地描述总体逻辑。 通过将布局切换到radix-major视图,可以使用标准CNN层(例如组卷积,组全连接的层和softmax操作)轻松加速这个block,我们将在补充材料中对其进行详细描述。 Split-Attention块的参数数量和FLOPS与具有相同cardinality和通道数量的残差块[23,60]大致相同。
和现有Attention方法的关系。在SE-Net[29]中首次引入的“squeeze-and-attention”(在原文中称为“excitation”)概念是利用一个全局上下文来预测信道上的注意因素。当radix=1时,我们的Split-Attention block对每个cardinal group应用一个sequeeze-and-attention操作,而SE-Net在整个block的顶部操作,而不管多个groups。之前的SK-Net[38]模型引入了两个网络分支之间的特征注意,但是其操作并没有在训练效率和向大型神经网络扩展方面进行优化。我们的方法概括了之前在cardinal group设置[60]中关于特征图注意力的工作[29,38],并且它的实现保持计算效率。图1显示了与SE-Net和SK-Net块的总体比较。
4 网络和训练
现在我们来描述实验中使用的网络设计和训练策略。首先,我们详细介绍了一些进一步提高性能的调整,其中一些已经在[25]中得到了经验验证。
4.1 网络调整(Network Tweaks)
Average Downsampling。当迁移学习的下游应用是密集的预测任务(例如检测或分割)时,保留空间信息就变得至关重要。 最近的ResNet实现通常将跨步卷积应用于3×3层而不是1×1层,以更好地保存此类信息[26,30]。 卷积层需要使用零填充策略处理特征图边界,这在转移到其他密集的预测任务时通常不是最佳选择。 我们不是在过渡块(对空间分辨率进行下采样)(transitioning block)处使用大步卷积,而是使用kernel size为3×3的平均池化层。
从ResNet-D上面调整。我们还采用了[26]引入的两个简单而有效的ResNet修改:(1)将第一个7×7卷积层替换为三个连续的3×3卷积层,它们具有相同的感受野大小,并且计算代价比原始设计更小。 (2)对于步长为2的过渡块(transition blocks),在1×1卷积层之前,将2×2平均池化层添加到shortcut连接中。
4.2 训练策略
大mini-batch分布式训练。遵循在先前的工作[19,37],我们并行使用8个服务器(总共64个GPU)训练模型。 我们的学习率根据consine scheduler进行调整[26,31]。 我们遵循通常的做法,即根据mini-batch size线性扩展初始学习率。 初始学习率由 给出,其中B是mini-batch size,我们使用
给出,其中B是mini-batch size,我们使用![]() 作为基本学习率。 这种Warmup策略在前5个epochs内应用,将学习率从0逐渐线性增加到Cosine scheduler的初始值[19,39]。 batch normalize(BN)参数γ在每个块的最终BN操作中被初始化为零,这已被建议用于大型批处理训练[19]。
作为基本学习率。 这种Warmup策略在前5个epochs内应用,将学习率从0逐渐线性增加到Cosine scheduler的初始值[19,39]。 batch normalize(BN)参数γ在每个块的最终BN操作中被初始化为零,这已被建议用于大型批处理训练[19]。
Label Smoothing。标签平滑首先用于改善Inception-V2的训练[53]。 回想一下,我们的网络的预测类概率q的交叉熵损失是针对ground truthp计算的,如下所示:
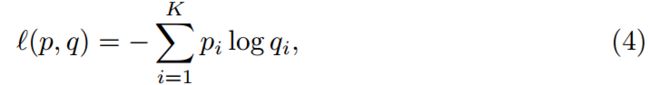
其中 K 是类别总数,![]() 是第 i 类的ground truth概率,
是第 i 类的ground truth概率,![]() 是网络对第 i 类的预测概率。 与标准图片分类一样,我们定义:
是网络对第 i 类的预测概率。 与标准图片分类一样,我们定义: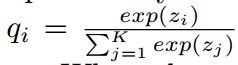 其中
其中 ![]() 是我们网络的输出层产生的对数。 当提供的标签是类而不是类概率(硬标签)时,如果 i 等于ground truth类 c,则
是我们网络的输出层产生的对数。 当提供的标签是类而不是类概率(硬标签)时,如果 i 等于ground truth类 c,则![]() ,否则=0。因此,在这种情况下:
,否则=0。因此,在这种情况下:![]()
![]() 。 在训练的最后阶段,对于j
。 在训练的最后阶段,对于j![]() ,
,![]() 往往很小,而将
往往很小,而将![]() 推至最佳值
推至最佳值![]() 时,这可能会导致过拟合[26,53]。 标签平滑处理不是使用硬标签作为目标,而是使用平滑的ground truth概率:
时,这可能会导致过拟合[26,53]。 标签平滑处理不是使用硬标签作为目标,而是使用平滑的ground truth概率:
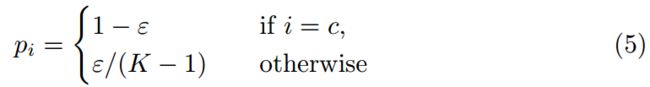
小常 ![]() 。这可以减轻网络的过度自信和过拟合。
。这可以减轻网络的过度自信和过拟合。
自动增强。Auto-Augment [11]是一种通过变换图像增强训练数据的策略,在变换图像中自适应地学习变换。 引入了16种不同类型的图像抖动转换,从中,一种基于两个连续转换的24种不同组合(例如移位,旋转和色彩抖动)增强了数据。 可以利用相对参数(例如,rotation angle)来控制每个变换的幅度,并且可以概率性地跳过变换。 尝试各种候选增强策略的搜索将返回最佳的24种最佳组合。 然后,在训练期间随机选择这24个策略之一并将其应用于每个样本图像。 原始的Auto-Augment实现使用强化学习来搜索这些超参数,并将它们视为离散搜索空间中的分类值。 对于连续搜索空间,它会先搜索可能的值,然后再搜索最佳值。
Mixup训练。mixup是另一种数据增强策略,可以从训练数据中生成随机图像对的加权组合[67]。 给定两个图像及其ground truth标签:![]() ,合成训练示例
,合成训练示例![]() 生成为:
生成为:

其中,λ〜Beta(α= 0.2)是每个增强样本的独立采样。
Large Crop Size。图像分类研究通常会比较在共享相同crop size的图像上运行的不同网络的性能。 ResNet变体[23,26,29,60]通常使用224的固定训练crop size,而 Inception-Net 系列[51 {53]使用299的训 crop size。最近,EfficientNet方法[55]已证明 增加输入图像大小以实现更深,更宽的网络可能会更好地权衡accuracy与FLOPS。 为了公平比较,在将ResNeSt与ResNet变体进行比较时,我们使用的crop size为224,在与其他方法进行比较时,我们使用的crop size为256。
正则化。即使对于大型数据集,非常深的神经网络也倾向于过拟合[68]。 为了防止这种情况,dropout正则化在训练过程中(但不是在推理过程中)随机掩盖了一些神经元,以形成隐式网络集成[29、49、68]。 在最终的全连接层之前,将以0.2的丢弃概率应用于具有200层以上的网络。 我们还将DropBlock层应用于网络的最后两个阶段的卷积层。 作为dropout的结构化变体,DropBlock [18]随机掩盖了局部块区域,并且比dropout更有效地用于特定正则化卷积层。
最后,我们还应用了权重衰减(即L2正则化),这还有助于稳定训练。 先前对大 mini-batch训练的研究表明,权重衰减仅应应用于卷积层和全连接层的权重[19,26]。 我们不对其他任何网络参数进行权重衰减,包括batch normalization层中的 biasd 单元 γ 和 β。
5 图像分类结果
我们的第一个实验研究了ImageNet 2012数据集[13]上ResNeSt 的图像分类性能,其中包含1.28M训练图像和 50K 验证图像(来自1000个不同的类)。 按照标准,网络会在训练集上进行训练,我们会在验证集上报告其top-1 accuracy。
5.1 改善细节
我们使用数据分片(sharding)在ImageNet上进行分布式训练,从而在GPU之间平均划分数据。在每次训练迭代中,从相应的分片中采样一小部分训练数据(无替换)。我们将从学习到的“自动增强”策略应用于每个单独的图像。然后,我们进一步应用标准转换,包括:随机size裁剪,随机水平翻转,颜色抖动和更改照明。最后,通过 均值/标准差 重新缩放对图像数据进行RGB归一化。对于mixup训练,我们仅将当前mini-batch中的每个样本与其相反顺序的样本进行mix[26]。在ReLU激活[44]之前的每个卷积层之后使用batch normalization[32]。使用Kaiming初始化[24]初始化网络权重。在最终分类层之前插入一个dropout层,其dropout 概率为0.2。使用余弦学习速率scheduler(其中前5个时间段预留给warmup),针对270个epochs进行训练,权重衰减为0.0001,momentum为0.9。对于ResNeSt-50,我们使用大小为8192的mini-batch,对于ResNeSt101,使用大小为4096的mini-batch,并且对于ResNeSt-{200, 269}采用2048的mini-batch。为了进行评估,我们首先将每个图像沿短边resize为crop size的1 / 0.875,然后应用center crop。我们用于ImageNet训练的代码实现使用GluonCV [21]和MXNet [9]。
5.2 消融研究
ResNeSt基于ResNet-D模型[26]。 Mixup训练将ResNetD-50的准确性从78.31%提高到79.15%。 自动增强功能将准确性进一步提高了0.26%。 当使用我们的Split-Attention块形成ResNeSt-50-fast模型时,准确度进一步提高到80.64%。 在此ResNeSt-fast设置中,在3×3卷积之前应用有效的平均下采样以避免在模型中引入额外的计算成本。 当把下采样操作移动到卷积层之后,ResNeSt-50达到了81.13%的accuracy。
Radix vs. Cardinality。我们对具有不同 radix/cardinality 的ResNeSt变体进行消融研究。 在每种变体中,我们都会适当调整网络的宽度,以使其整体计算成本与ResNet变体相似。 结果显示在表2中,其中 s 表示radix,x 表示cardinality,d 表示网络宽度(0s表示使用ResNet-D [26]中的标准残差块)。 从经验上我们发现,将radix从0增加到4会不断提高top-1的accuracy,同时还会增加latency和内存使用率。 尽管我们期望通过更大的 radix/cardinality 进一步提高accuracy,但我们在后续实验中采用了2s1x64d设置的Split-Attention,以确保这些blocks可扩展到更深的网络,并在速度,准确性和内存使用之间取得良好的平衡。
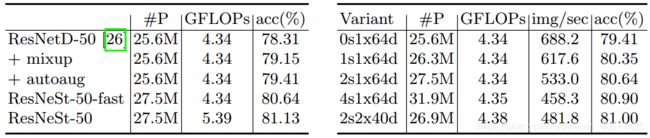
表2:ImageNet图像分类的消融研究。 (左)改进的细目分类。 ResNeSt-fast设置下的(右)cardinality vs. radix的关系。 例如2s2x40d表示radix= 2,cardinality= 2,width= 40。 请注意,即使radix = 1也不会降低任何现有方法的性能(请参见公式3)。
5.3 和State-of-the-Art比较
ResNet变体。为了与ResNet变体[23,26,29,38,60]进行比较,所有网络(包括ResNeSt)都使用224×224的crop size进行训练,然后使用224×224以及320x320的center crop进行评估。按照先前的实践,我们在此基准测试中考虑50层和101层网络。使用平均池而不是大步卷积作为下采样策略,会使计算量额外增加1 GFLOPS。为了公平地比较匹配的计算成本,我们将平均池化操作移到3×3卷积层之前,以构建ResNeSt-fast模型,其中卷积层在降采样特征图上运行。我们使用2s1x64d(请参阅表2)作为ResNeSt设置,因为它具有更好的训练和推理速度,并且内存使用较少。表3显示,我们提出的ResNeSt在具有相似数量的网络参数和FLOPS的情况下优于所有ResNet变体,包括:ResNet [23],ResNeXt [60],SENet [29],ResNet-D [26]和SKNet [38]。值得注意的是,我们的ResNeSt-50达到了80.64 top-1accuracy,这是第一个50层ResNet变体,在ImageNet上超过80%。

表3:在ImageNet上进行的图像分类结果,将我们提出的ResNeSt与其他复杂程度在50层和101层配置中的ResNet变体进行了比较。 我们使用crop size224和320报top-1的accuracy。
其他CNN模型。为了与使用不同crop size设置训练的CNN模型进行比较,我们增加了更较深模型的训练crop size。 对于ResNeSt-200,我们使用256×256的crop size;对于ResNeSt 269,我们使用320×320的crop size。对于大于256的输入大小,采用双三次上采样策略。结果如表4所示,除了参数数量外,我们还比较inference速度。 我们发现,尽管在accuracy折衷的参数上具有优势,但广泛使用的depth-wise卷积并未针对推理速度进行优化。 在此基准测试中,所有推论速度均使用mini-batch为16 进行测量,并使用原始作者在单个NVIDIA V100 GPU上的实现[1]。 与通过神经体系结构搜索找到的模型相比,提出的ResNeSt具有更好的accuracy和latency权衡。

6 迁移学习结果
6.1 目标检测
我们在 表5 中报告了在MS-COCO [42]上的检测结果。所有模型均在带有118k图像的COCO-2017训练集上进行了训练,并使用标准COCO在具有5k图像(又称为minival)的COCO-2017验证集上进行了单一尺度的AP指标评估。 我们使用FPN [41],(跨卡)同步batch normalization[65]和图像多尺度增强(从640到800随机选择图像的短边尺寸)训练所有模型。 使用 1x 学习率scheduler。 我们使用 Detectron2 [57]进行FasterRCNNs和Cascade-RCNNs实验。 为了进行比较,我们仅使用ResNeSt替换了原始的ResNetbackbone,同时使用了超参数和检测头的默认设置[20,57]。
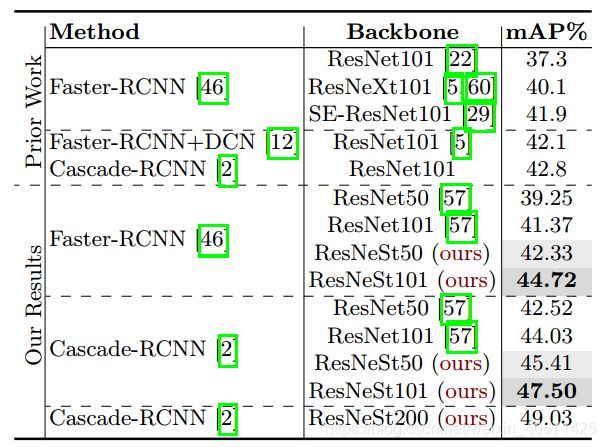
表5:MS-COCO验证集上的目标检测结果。 我们的ResNeS backbone极大地改善了FasterRCNN和Cascade-RCNN。
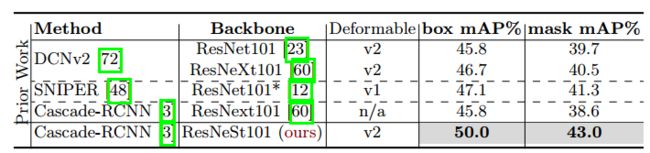
表10:MS-COCO test-dev集上的实例分割结果。 *表示多尺度inference。
与使用标准ResNet的baselines相比,我们的backbone能够将Faster-RCNN和CascadeRCNN的mean average precision提高约3%。 结果表明,我们的backbone具有良好的泛化能力,可以轻松地转移到下游任务。 值得注意的是,在更少的参数下,我们的ResNeSt50在Faster-RCNN和Cascade-RCNN检测模型上均优于ResNet101。 详细结果见表10。我们评估了具有ResNeSt101可变形的Cascade-RCNN,它也是使用COCO test-dev集上的1倍学习率计划进行训练的。 使用单尺度inference得出的boxes mAP为49.2。
6.2 实例分割
为了探索我们新型backbone的泛化能力,我们还将其应用于实例分割任务。 除了边界框和类别概率之外,实例分割还可以预测目标mask,因此需要更精确的密集图像表示。
我们以ResNeSt-50和ResNeSt-101为backbone评估了Mask-RCNN [22]和Cascade-Mask-RCNN [2]模型。 所有模型都与FPN [41]和同步batch normalization一起训练。 为了增强数据,输入图像的短边会随机缩放为(640、672、704、736、768、800)之一。 为了与其他方法进行公平比较,应用了1x学习率计schedule,其他超参数保持不变。 我们使用上述相同的设置,但使用标准的ResNet重新训练baseline。 我们所有的实验都在使用COCO-2017数据集并使用Detectron2进行了训练[57]。 对于baseline实验,我们默认使用的backbone是ResNet的MSRA版本,在1x1转换层上具有stride-2。 边界框和mask mAP均在COCO-2017验证数据集上报告。
如表6所示,我们的新backbone具有更好的性能。 对于Mask-RCNN,ResNeSt50的性能优于baseline,box/mask 的性能提高了2.85%/ 2.09%,而ResNeSt101的改进更好,为4.03%/ 3.14%。 对于Cascade-Mask-RCNN,切换到ResNeSt50或ResNeSt101所产生的增益分别为3.13%/ 2.36%或3.51%/ 3.04%。 这表明,如果模型包含更多的“Split-Attention”模块,则效果会更好。 从检测结果中可以看出,我们的ResNeSt50的mAP超过了标准ResNet101 backbone的结果,这表明使用我们所提出模块的小型模型的容量更高。 最后,我们还使用1倍的学习速率schedule训练了具有ResNeSt101可变形的CascadeMask-RCNN。 我们在COCO test-dev集上对其进行评估,分别得出50.0 box mAP和43.1 mask mAP。 补充材料中包括不同设置下的其他实验。

表6:MS-COCO验证集上的实例分割结果。 我们的ResNeSt backbone改进了Mask-RCNN和Cascade-RCNN模型。 使用ResNeSt-101的模型优于使用ResNet-101的所有先前工作。
6.3 语义分割
在迁移学习的语义分段的下游任务中,我们使用DeepLabV3 [7]的GluonCV [21]实现作为baseline方法。 此处,将膨胀的(dilated)网络策略[6,62]应用于backbone网络,从而形成了stride-8模型。 训练期间使用了同步batch normalize[65],以及类似多项式的学习率scheduler(初始学习率= 0.1)。 为了进行评估,对网络预测对数进行了8次上采样,以针对ground truth标签计算每个像素的交叉熵损失。 我们使用flipping[65、69、73]进行多尺度评估。
我们首先考虑Cityscapes [10]数据集,该数据集由5K高质量标注的图像组成。 我们在训练集中的2,975张图像上训练每个模型,并在500个验证图像上报告其mIoU。 经过先前的工作,我们在此基准测试中仅考虑19种object/stuff类别。 在此benchmark中,我们没有使用任何带有粗标注的图像或任何其他数据。 我们的ResNeSt backbone将DeepLabV3模型实现的mIoU提高了约1%,同时保持了相似的总体模型复杂性。 值得注意的是,使用我们的ResNeSt-50 backbone的DeepLabV3模型已经比具有更大的ResNet-101 backbone的DeepLabV3获得了更好的性能。
ADE20K [71]是一个大型场景解析数据集,包含150个object和stuff类,其中包含20K训练,2K验证和3K测试图像。 所有网络都在训练集上训练了120个epochs,并在验证集上进行了评估。 表7显示了得到的像素精度(pixAcc)和mean IoU(mIoU)。 通过使用ResNeSt backbone,DeepLabV3模型的性能得到了显着改善。 与之前的结果类似,使用ResNeSt-50 backbone的DeepLabv3模型已经优于使用更深的ResNet-101 backbone的DeepLabv3模型。 带有ResNeSt-101 backbone的DeepLabV3达到了82.07%pixAcc和46.91%mIoU,据我们所知,这是针对ADE20K推出的最佳单一模型。

表7:验证集的语义分割结果:ADE20K(左),Citscapes(右)。 训练模型时没有粗略标记或额外的数据。
附录
A Radix-major的Split-Attention Block
为了轻松直观地显示“Split-Attentio”的概念,我们在主要方法的描述中采用了cardinality major实现,其中cardinal index相同的组在物理上彼此相邻。 cardinality-major的实现是直接直观的,但是很难使用标准的CNN运算符进行模块化和加速。 因此,我们在实验中采用以radix-major的实现。
图3 radix-major的布局概述了Split-Attention block。首先将输入feature map分为 RK 组,其中每个组都有一个cardinality-index和radix-index。在这种布局中,具有相同radix-index的组在内存中彼此相邻。然后,我们可以对不同的splits进行求和,以便将cardinality-index相同,但radix-index不同的特征图组融合在一起。此操作与在主要论文中所述的cardinality-major实现中的每个radix组内的各个片段之间的融合处相同。类似地,全局池化层在空间维上聚合,同时保持通道维分离,这与对每个cardinal组进行全局池化然后将结果连接在一起相同。然后在池化层之后添加两个连续的全连接(FC)层,其组数等于基cardinaty,以预测每个splits的attention权重。分组FC层的使用使得将每个FC对分别应用于每个cardinal组的顶部相同。
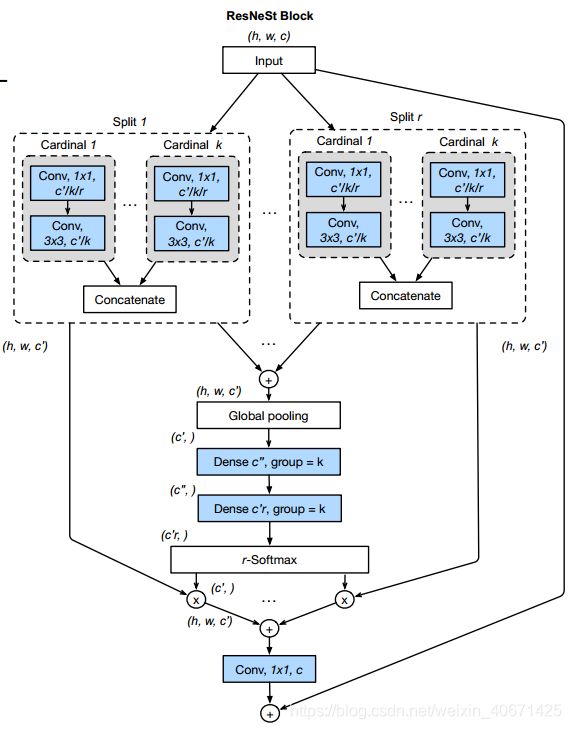
图3:ResNeSt块的Radix-major实现,其中具有相同radix-index但不同cardinality的特征图组在物理上彼此相邻。 因为可以将1×1卷积层统一为一个层,并且可以使用组卷积(组数等于RK)来实现3×3卷积层,所以可以轻松地加速此实现。
通过这种实现,可以将前1×1卷积层统一为一个层,并可以使用具有 RK 组数的单个分组卷积来实现3×3卷积层。 因此,使用标准CNN运算符将SplitAttention block模块化并实现。