Aminer学术社交网络数据知识图谱构建(三元组与嵌入)
本文共2865个字,预计阅读时间需要10分钟。
Aminer
科技情报大数据挖掘与服务系统平台AMiner是由清华大学计算机科学与技术系教授唐杰率领团队建立的,具有完全自主知识产权的新一代科技情报分析与挖掘平台 。
AMiner平台以科研人员、科技文献、学术活动三大类数据为基础,构建三者之间的关联关系,深入分析挖掘,面向全球科研机构及相关工作人员,提供学者、论文文献等学术信息资源检索以及面向科技文献、专利和科技新闻的语义搜索、语义分析、成果评价等知识服务。典型的知识服务包括:学者档案管理及分析挖掘、专家学者搜索及推荐、技术发展趋势分析、全球学者分布地图、全球学者迁徙图、开放平台等。

Academic Social Network数据集
数据集地址:https://www.aminer.cn/aminernetwork
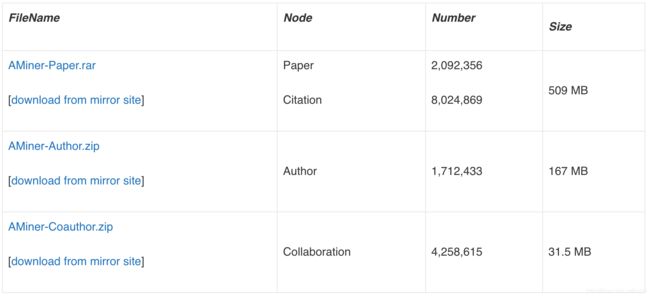
Supplement: The relaionship between author id and paper id AMiner-Author2Paper.zip. The 1st column is index, the 2nd colum is auhor id, the 3rd column is paper id, the 4th column is author’s position.
连上补充数据一共4个数据集文件。
该数据的内容包括论文信息,论文引文,作者信息和作者协作。 2,092,356篇论文和8,024,869之间的引用被保存在文件AMiner-Paper.rar中; 1,712,433位作者被保存在AMiner-Author.zip文件中,4,258,615位合作关系被保存在文件AMiner-Coauthor.zip中。
连上补充数据一共4个数据集文件。
数据三元组转化与连接
将上述4个数据集下载到本地目录后通过Python脚本读取、处理、连接生成实体csv和关系csv文件。
脚本代码:https://github.com/xyjigsaw/Aminer2KG
脚本生成的数据包括一下几个部分:
- author2csv.py includes
e_author.csv: author entity
e_affiliation.csv: affiliation entity
e_concept.csv: concept entity
r_author2affiliation.csv: relation between author and affiliation
r_author2concept.csv: relation between author and concept - author2paper2csv.py includes
r_author2paper.csv: relation between author and paper - paper2csv.py includes
e_paper.csv: paper entity
e_venue.csv: venue entity
r_paper2venue.csv: relation between paper and venue
r_citation.csv: relation between papers
r_coauthor.csv: relation between authors
汇总:
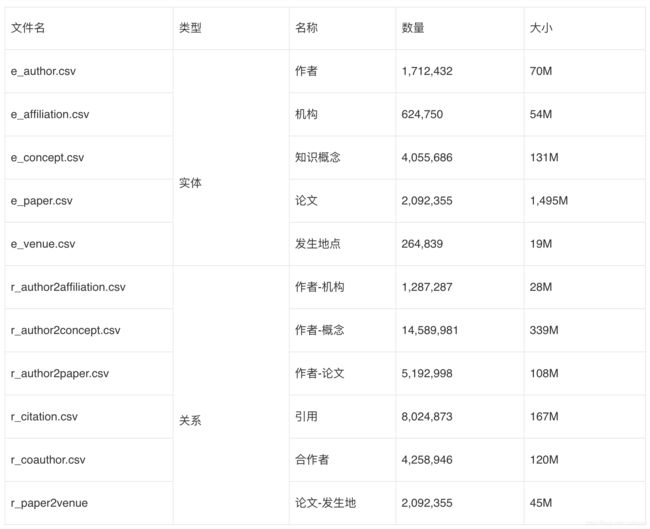
以上共5个实体类型,6个关系类型。
至此,生成了Aminer学术社交网络知识图谱三元组数据。
导入Neo4j
将上述11个csv文件放入Neo4j数据库的import文件夹中。
在Neo4j桌面端控制台一句一句执行下述CYPHER代码:
包含了实体节点导入、实体索引构建、关系导入、关系索引构建。
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///e_author.csv" AS line
CREATE (author:AUTHOR{authorID:line.authorID, authorName:line.authorName, pc:line.pc, cn:line.cn, hi:line.hi, pi:line.pi, upi:line.upi})
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///e_affiliation.csv" AS line
CREATE (affiliation:AFFILIATION{affiliationID:line.affiliationID, affiliationName:line.affiliationName})
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///e_concept.csv" AS line
CREATE (concept:CONCEPT{conceptID:line.conceptID, conceptName:line.conceptName})
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///e_paper.csv" AS line
CREATE (paper:PAPER{paperID:line.paperID, paperTitle:line.title, paperYear:line.year, paperAbstract:line.abstract})
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///e_venue.csv" AS line
CREATE (venue:VENUE{venueID:line.venueID, venueName:line.name})
CREATE INDEX ON: AUTHOR(authorID)
CREATE INDEX ON: AFFILIATION(affiliationID)
CREATE INDEX ON: CONCEPT(conceptID)
CREATE INDEX ON: PAPER(paperID)
CREATE INDEX ON: VENUE(venueID)
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///r_author2affiliation.csv" AS line
MATCH (FROM:AUTHOR{authorID:line.START_ID}), (TO:AFFILIATION{affiliationID:line.END_ID})
MERGE (FROM)-[AUTHOR2AFFILIATION: AUTHOR2AFFILIATION{type:line.TYPE}]->(TO)
USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///r_author2concept.csv" AS line
MATCH (FROM:AUTHOR{authorID:line.START_ID}), (TO:CONCEPT{conceptID:line.END_ID})
MERGE (FROM)-[AUTHOR2CONCEPT: AUTHOR2CONCEPT{type:line.TYPE}]->(TO)
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///r_author2paper.csv" AS line
MATCH (FROM:AUTHOR{authorID:line.START_ID}), (TO:PAPER{paperID:line.END_ID})
MERGE (FROM)-[AUTHOR2PAPER: AUTHOR2PAPER{type:line.TYPE, author_pos:line.author_position}]->(TO)
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///r_citation.csv" AS line
MATCH (FROM:PAPER{paperID:line.START_ID}), (TO:PAPER{paperID:line.END_ID})
MERGE (FROM)-[CITATION: CITATION{type:line.TYPE}]->(TO)
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///r_coauthor.csv" AS line
MATCH (FROM:AUTHOR{authorID:line.START_ID}), (TO:AUTHOR{authorID:line.END_ID})
MERGE (FROM)<-[COAUTHOR: COAUTHOR{type:line.TYPE, n_cooperation:line.n_cooperation}]->(TO)
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM "file:///r_paper2venue.csv" AS line
MATCH (FROM:PAPER{paperID:line.START_ID}), (TO:VENUE{venueID:line.END_ID})
MERGE (FROM)-[PAPER2VENUE: PAPER2VENUE{type:line.TYPE}]->(TO)
CREATE INDEX ON: AUTHOR(authorName)
CREATE INDEX ON: AFFILIATION(affiliationName)
CREATE INDEX ON: CONCEPT(conceptName)
CREATE INDEX ON: PAPER(paperTitle)
CREATE INDEX ON: VENUE(venueName)
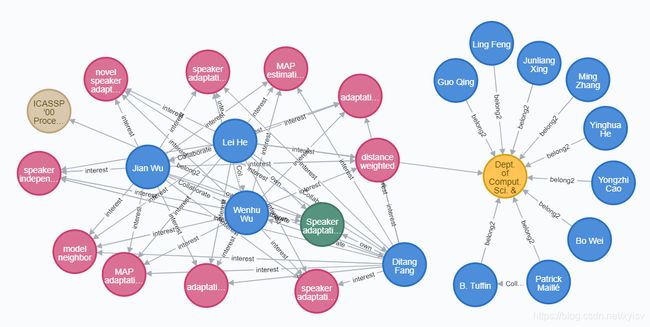
预览:
知识图谱嵌入
这部分将上述千万级三元组训练成嵌入数据,PyTorch-BigGraph(PBG)给出了令人满意的解决方案。PBG是一个分布式大规模图嵌入系统,能够处理多达数十亿个实体和数万亿条边的大型网络图结构。图结构分区、分布式多线程和批处理负采样技术赋予了PBG处理大型图的能力。
这部分内容具体请看:https://www.omegaxyz.com/2020/07/12/aminer-academic-social-network/
项目代码:Aminer2KG
更多内容访问 omegaxyz.com
网站所有代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权
© 2020 • OmegaXYZ-版权所有 转载请注明出处