吴恩达机器学习笔记(二)(附编程作业链接)
吴恩达机器学习笔记(二)
标签: 机器学习
- 吴恩达机器学习笔记二
- 一逻辑回归logistic regression
- 逻辑函数S型函数logistic function and sigmoid function
- 决策边界decision boundary
- 代价函数cost function
- 代价函数的简化Simplified Cost Function
- 梯度下降Gradient Descent
- 更快的优化算法
- 多元分类问题
- 二过拟合Overfitting
- 基本概念
- 正则化的代价函数cost function
- 正规化的线性回归Regularized Linear Regression
- 正则化的逻辑回归Regularized Logistic Regression
- 总结重要的几个式子
- 编程作业下载
- 点我下载编程作业
- 一逻辑回归logistic regression
一.逻辑回归(logistic regression)
1.逻辑函数&&S型函数(logistic function and sigmoid function)
线性回归的假设表达式不试用于仅有0,1两种结果的分类表达,将表达式简单修改为逻辑函数也叫S型函数如下:
hθ(x)=g(θTx)z=θTxg(z)=11+e−z
该函数的函数图像如下

在预测时输入x变量所得的g(z)即结果为1的概率值
2.决策边界(decision boundary)
hθ(x)≥0.5→y=1hθ(x)<0.5→y=0
在S型函数中若y大于0.5边界则x必定大于0,于是:
hθ(x)=g(θTx)≥0.5whenθTx≥0
所以可以推出以下 结论!
θTx≥0⇒y=1θTx<0⇒y=0
3.代价函数(cost function)
分类问题的代价函数与回归问题的代价函数有一定的区别如下:
J(θ)=1m∑i=1mCost(hθ(x(i)),y(i))Cost(hθ(x),y)=−log(hθ(x))Cost(hθ(x),y)=−log(1−hθ(x))if y = 1if y = 0
当y=1时函数图像如下
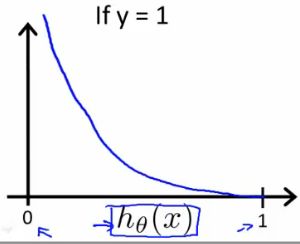
当y=0时函数图像如下
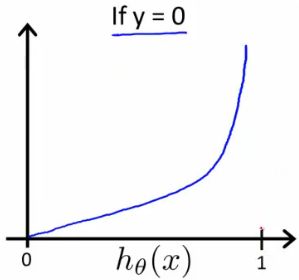
4.代价函数的简化(Simplified Cost Function)
Cost(hθ(x),y) 可以写作:
Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
从而得到简化的代价函数:
J(θ)=−1m∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
将其表达为矢量表达为:
h=g(Xθ)J(θ)=1m⋅(−yTlog(h)−(1−y)Tlog(1−h))(重要)
5.梯度下降(Gradient Descent)
将其代价函数应用到梯度下降算法中为:
Repeat{θj:=θj−αm∑i=1m(hθ(x(i))−y(i))x(i)j}
矢量化表达为:
θ:=θ−αmXT(g(Xθ)−y⃗ )(重要)
6.更快的优化算法
“Conjugate gradient”, “BFGS”, and “L-BFGS”
这些算法都不需要手动选择学习速率,并且比梯度下降速度更高效,但是也更复杂。
使用方法:
1.先计算出J值与梯度值 J(θ)与∂∂θjJ(θ)
2.写一个代价函数返回J值与梯度值:
function [jVal, gradient] = costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end3.使用fminunc()优化算法 (无约束非线性规划函数)
options = optimset('GradObj', 'on', 'MaxIter', 100); %100表示迭代次数
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);
%optTheta是最后迭代出的theta,functionVal是J的最小值exitFlag返回是否收敛7.多元分类问题
将n元问题分成n个二元问题,然后在对这个二元问题进行预测
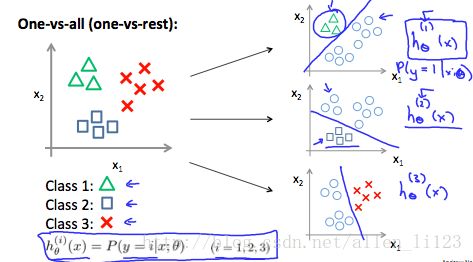
y∈{0,1...n}h(0)θ(x)=P(y=0|x;θ)h(1)θ(x)=P(y=1|x;θ)⋯h(n)θ(x)=P(y=n|x;θ)prediction=maxi(h(i)θ(x))
二.过拟合(Overfitting)
1.基本概念

左边第一副图称作欠拟合(underfitting), 特征太少导致并没有很好的拟合数据,cost function非常大
中间一幅图拟合的很好
而右边一幅图称作过拟合(overfitting),特征太多导致过分的拟合,cost function虽然非常小但是不符合实际情况
解决过度拟合问题有两种方法:
1.减少特征数量
- 手动选择哪些特征需要保留
- 使用一个模型选择算法
2.使用正则化
- 保留所有的特征,减少参数 θ 的数量
- 当有很多有用的特征时使用的很好
2.正则化的代价函数(cost function)
将前面的代价函数加上一个惩罚(penalize)使之尽量少的增加变量,添加后的代价函数如下:
minθ 12m ∑i=1m(hθ(x(i))−y(i))2+λ ∑j=1nθ2j
λ 是一个 正则化参数(regularization parameter),决定了惩罚的大小
通过正则化可以使假设函数更加平滑并且减少过拟合,但是如果 λ 太大则会出现欠拟合。
3.正规化的线性回归(Regularized Linear Regression)
1.修改梯度下降方程、
Repeat { θ0:=θ0−α 1m ∑i=1m(hθ(x(i))−y(i))x(i)0 θj:=θj−α [(1m ∑i=1m(hθ(x(i))−y(i))x(i)j)+λmθj]} j∈{1,2...n}
注:将 θ0 与 θi 分开因为我们一般不惩罚 θ0
θi 可以写做:
θj:=θj(1−αλm)−α1m∑i=1m(hθ(x(i))−y(i))x(i)j
2.正则方程
θ=(XTX+λ⋅L)−1XTywhere L=⎡⎣⎢⎢⎢⎢⎢⎢⎢011⋱1⎤⎦⎥⎥⎥⎥⎥⎥⎥(重要)
注:L是(n+1)*(n+1)维的
4.正则化的逻辑回归(Regularized Logistic Regression)
加上正则化的代价函数如下:
J(θ)=−1m∑i=1m[y(i) log(hθ(x(i)))+(1−y(i)) log(1−hθ(x(i)))]+λ2m∑j=1nθ2j
然后通过梯度下降不断更新 θi 获得代价函数。
3.总结重要的几个式子
1.逻辑回归的代价函数的矢量表达:
h=g(Xθ)J(θ)=1m⋅(−yTlog(h)−(1−y)Tlog(1−h))(重要)
2.逻辑回归梯度下降的矢量表达:
θ:=θ−αmXT(g(Xθ)−y⃗ )(重要)
3..正则方程
θ=(XTX+λ⋅L)−1XTywhere L=⎡⎣⎢⎢⎢⎢⎢⎢⎢011⋱1⎤⎦⎥⎥⎥⎥⎥⎥⎥(重要)
注:L是(n+1)*(n+1)维的
另外找到了plot函数画点形状的命令
