python运用DBSCAN算法对坐标点进行离群点检测&dataframe的append问题
问题描述
(关于dataframe的append问题,直接拖至文后)
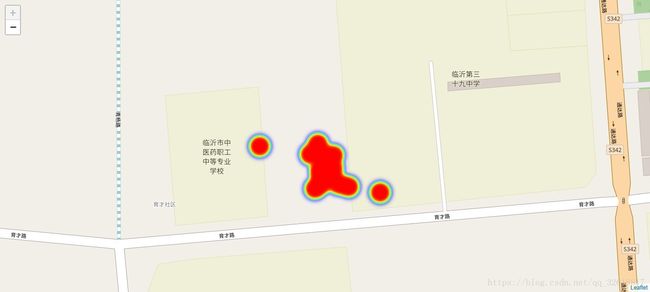
我们有n多单车,每个单车一段时间(差不多一个星期)规律返回的经纬度位置数据,类似于下图,但是有个问题是单车的这些经纬度数据的准确性只有70%左右,不准确的经纬度会出现偏差,我们要做的就是去掉那些噪音比较大的坐标点,筛选出正确位置从而进行之后的操作。
解决方案
- DBSCAN算法简介
- 操作源码
- 小收获&小总结
DBSCAN算法简介
DBSCAN是一种典型的基于密度的聚类算法。
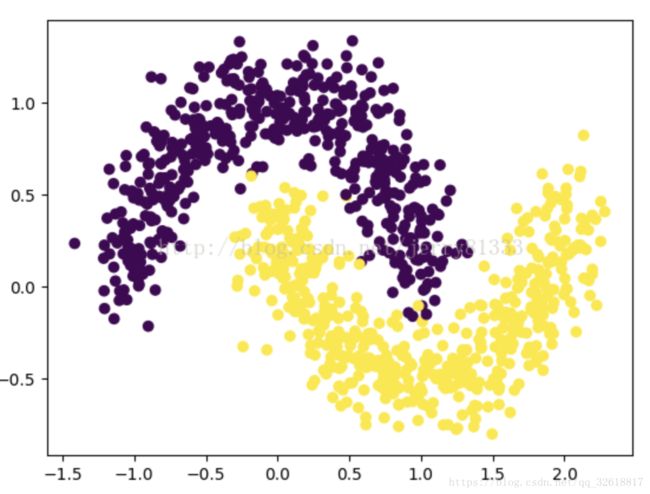
两张图可以非常清晰地表现k-means与DBSCAN的聚类结果:
原始随机数据:
k-means的聚类结果:
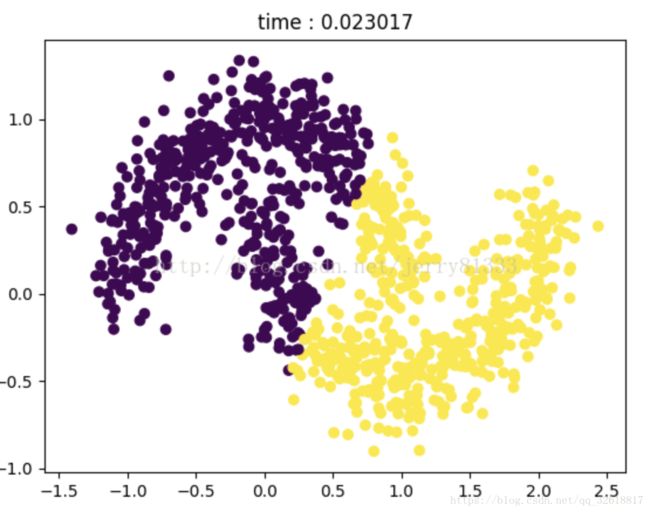
DBSCAN的聚类结果:

关于DBSCAN的具体介绍可以参照:
https://blog.csdn.net/jerry81333/article/details/75640140
操作源码
import pandas as pd
from math import radians
from math import tan,atan,acos,sin,cos,asin,sqrt
import itertools
from sklearn.cluster import DBSCAN
import numpy as np
# 该函数是为了通过经纬度计算两点之间的距离(以米为单位)
def geodistance(array_1,array_2):
lng1 = array_1[0]
lat1 = array_1[1]
lng2 = array_2[0]
lat2 = array_2[1]
lng1, lat1, lng2, lat2 = map(radians, [lng1, lat1, lng2, lat2])
dlon=lng2-lng1
dlat=lat2-lat1
a=sin(dlat/2)**2 + cos(lat1) * cos(lat2) * sin(dlon/2)**2
dis=2*asin(sqrt(a))*6371*1000
return dis
def main():
data = pd.read_csv('outlier_data.csv', sep=',')
data.columns = ['id', 'time', 'lon', 'lat', 'last_lon', 'last_lat', 'distance'] # 原来是中文的列名,担心之后的解码问题,更改了列名
data = data[['id', 'time', 'lon', 'lat']] # 只需要其中的四列数据
# 该部分是去掉那些上传数据次数小于3的车辆id
count = data.groupby(by=['id'])['time'].agg({'count': len}).reset_index()# 算出每一个车辆id收集的数据次数
data = pd.merge(data, count, on=['id'], how='left')
data['lon_lat'] = data.apply(lambda x: [x['lon'], x['lat']], axis=1)# 为了方便使用geodistance这个经纬度换算公式,更改一下数据格式
data = data[data['count'] > 3]
# 对于清洗之后的数据,对每一个groupby的group进行处理,将DBSCAN之后的label值赋予成新的一列
new = pd.DataFrame()
for id_index,group in data.groupby(by=['id']):
dbscan = DBSCAN(eps=500, min_samples=4, metric=geodistance).fit(list(group['lon_lat']))# 对于DBSCAN来说,两个最重要的参数就是eps,和min_samples。当然这两个值不是随便定义的,这个在下文再说
group['label'] = dbscan.labels_
new = new.append(group)# 我在这里被坑得不浅,也留在下文总结
print(new)
clean_data = new[new['label'] != -1]# label为-1的即为离群点,删除掉离群点
# 然后求出其他点的中心点
temp_lon = clean_data.groupby(by=['id'])['lon'].mean().reset_index()
temp_lat = clean_data.groupby(by=['id'])['lat'].mean().reset_index()
result = pd.merge(temp_lon,temp_lat,on=['id'],how='left')
print(result.head(20))
result.to_csv('去除离散点的数据.csv')
return result
if __name__ == '__main__':
main()小收获&小总结
1、关于DBSCAN的调参问题
DBCSAN有两个最重要的参数,eps和min_samples。必须设置好符合该数据集的参数,才能保证聚类的效果较好。
具体参考该网址:https://blog.csdn.net/u013206066/article/details/70985282
大致意思是找出每个点到其他每个点的距离,按照距离进行排序,也就是[第一近的距离,第二近的距离,… , 第k近的距离]这样一个序列,将其可视化,找到距离突变的位置,确定该距离为eps(半径),和该位置的k为min_samples。
2、关于dataframe的append问题
之前我一直是固有的对待list的态度来处理dataframe。因为在list中,前面已经定义list = []之后,要往里面添加数据只需要list.append(a);但是,对于dataframe不是这样的,直接进行dataframe.append(数据)是不行的,数据不会写入。一定要重新赋值:
new = new.append(group)
(当时把代码逐字看完都没找到问题==太蠢了…)