django+echarts数据可视化(NBA球队数据可视化02)!
来写我们的爬虫 >_< (我可能是条咸鱼了吧!) 爬虫十分简单也没有爬取得网站也没有什么反爬整体还是很方便得
# -*- coding:utf-8 -*-
import requests
import random
from bs4 import BeautifulSoup
import pymssql
import os
# 获取网页源码
def get_data():
headers = Ua_headers()
response = requests.get('https://nba.hupu.com/standings',headers=headers,verify=False)
return response.text
# ua的形成
def Ua_headers():
user_agent_list = [
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0',
'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0',]
user_agent = random.choice(user_agent_list)
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
}
headers['user_agent'] = user_agent
return headers
# 绑定写入数据库
def Analyze_data(data):
soup = BeautifulSoup(data,'html.parser')
datas = soup.find('tbody')
datas_tr = datas.find_all('tr')
# 链接我的数据库
conn = pymssql.connect("DESKTOP-SCIMUGR", "sa", "zxc1230.", "NBA")
cursor = conn.cursor()
cursor.execute('truncate table index_nbadata')
for tr in datas_tr:
print(tr)
td = tr.find_all("td")
if len(td) == 1:
area = td[0].text
else:
da1 = td[0].text # 排名
da2 = td[1].text # 队名
da3 = td[2].text # 胜场
da4 = td[3].text # 败场
da5 = td[4].text # 胜率
try:
img_url = td[1].find("a")['href']
get_img(img_url,td[1].text)
img = "/static/images/"+ da2 + '.png' # os.getcwd() + "\\NBA\\
except TypeError:
pass
try:
cursor.execute("insert into index_nbadata values('%d','%s','%d','%d','%s','%s','%s')"%(
int(da1),da2,int(da3),int(da4),da5,img,area
))
except ValueError:
pass
conn.commit() # 必须要有这个语句才能写入数据库
# 球队图片的抓取 因为在的django的文件夹里运行的进行想对的存储文件夹设置
def get_img(url,name):
path = os.getcwd() + '\\NBA_web\\index\\static\\images\\'
print(path)
headers = Ua_headers()
response = requests.get(url, headers=headers, verify=False)
soup = BeautifulSoup(response.text,'lxml')
img = soup.find('div',{'class':'img'})
img_url = img.find("img")['src']
pon = requests.get(img_url)
with open(path+name+'.png','ab+') as im:
im.write(pon.content)
im.close()
print('保存图片成功')
if __name__ == "__main__":
pon = get_data()
Analyze_data(pon)
# url = 'https://nba.hupu.com/teams/raptors'
# get_img(url,'雄鹿')爬虫写好之后运行一次就可以获取到最新的数据 # (运行一次获取一次 哈哈)T_T我就是这个水平怎么滴!

这个时候数据库已经有数据啦 我们已经成功九成啦! 666!
要想让这些数据在网站上可是话是十分简单的 O_O!!
首先进入https://echarts.baidu.com
echarts 的官网 查找你所要用的图例 然后 https://www.echartsjs.com/dist/echarts-gl.js
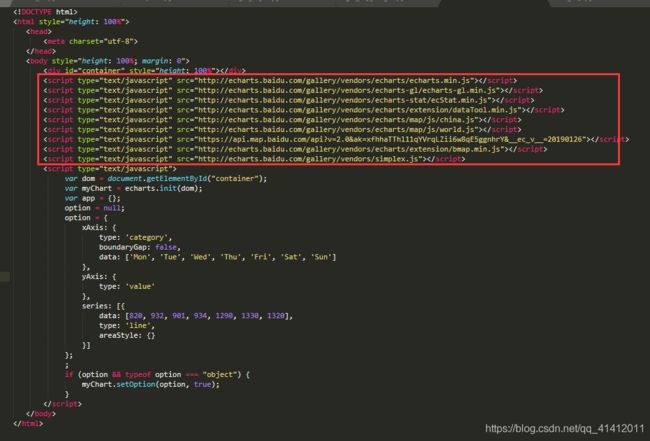
把这个echarts-gl.js 下载下来 导入您的django 中以便使用 这样就完成啦 导入这个js 按照下图的写法进行可视化操作

这个是源码 模仿源码进行写就可以啦 上面的那些js 不用写的直接用刚刚下载的那个 echarts-gl.js 就可以啦
我的文件夹结构图:
我用了通用模块 views.py 是这样写的
from django.views import generic # 通用模块
class EastViews(generic.ListView):
template_name = 'east.html' # 指向前端网页名称
context_object_name = 'GGGG' # 数据的名称
def get_queryset(self):
return NBAData.objects.filter(area='东部').all() # 获取东部的数据
class WestViews(generic.ListView):
template_name = 'west.html'
context_object_name = 'GGGG'
def get_queryset(self):
return NBAData.objects.filter(area='西部').all() # 获取西部的数据
# 前端的书写 哈哈有趣的前端
# east.html
{% extends 'model.html' %}
{% load static %}
{% block title %}
东部球队展示
{% endblock %}
{% block modeljs %}
{% endblock %}
{% block modelcss %}
{% endblock %}
{% block modeldiv %}
{% endblock %}
{% if NBAdata %}
{% block modelscript %}
{% endblock %}
{% endif %}
{% block modeltable %}
排名
球队logo
球队
胜场
输场
胜率
{% if GGGG %}
{% for data in GGGG %}
{{ data.ranking }}

{{ data.ballgame }}
{{ data.win }}
{{ data.transport }}
{{ data.winrate }}
{% endfor %}
{% else %}
Not Datas
{% endif %}
{% endblock %}
# 主要的操作就是按照echart.js 的规则填上所需的数据就可以啦 下面展示一下网页
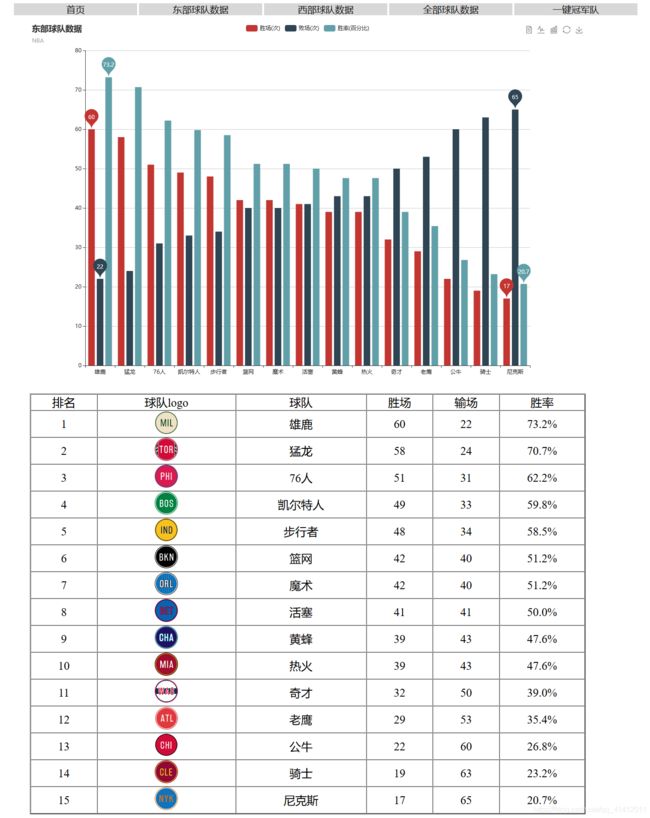
页面简陋 勿喷 勿喷 ! 完成啦 !! 开心!!>_
https://github.com/jingziren-GG/django-start
项目在这里